从一个面试场景开始,尤其是简历上写了 DeepResearch 项目的同学,很可能被这么问:
🤖面试官: 通义新出的那个 DeepResearch 有了解吗
🤡答:DeepResearch 是阿里搞的一个 Agentic LLM 框架。它通过合成数据增量预训练 + 多阶段后训练,让模型在做复杂研究任务时的多步推理和工具调用能力变得超级强。
它有两种工作模式:
1️⃣ReAct 模式: 就是基础的思考-行动-观察循环,走一步看一步。
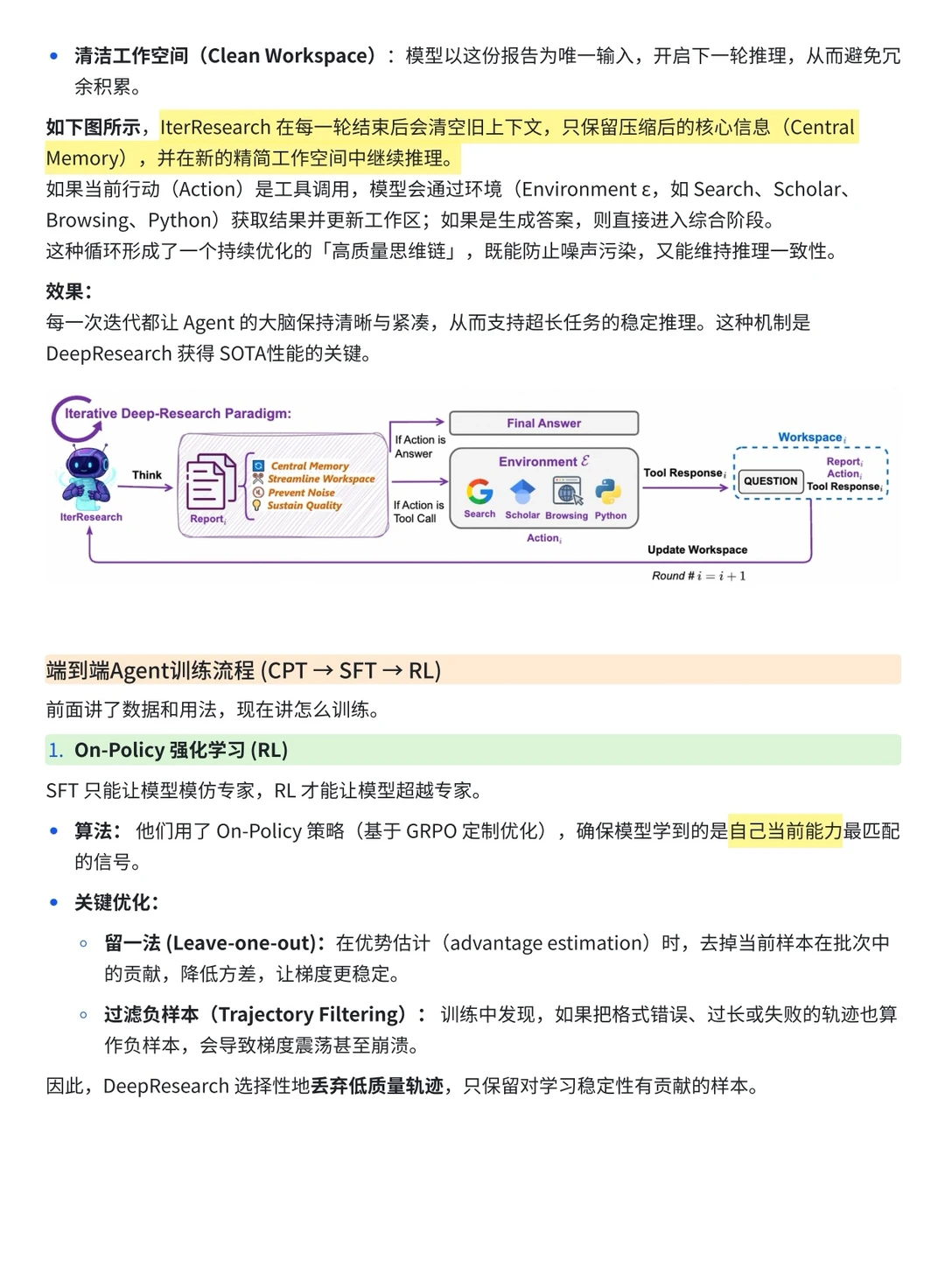
2️⃣ IterResearch 模式: 这个是进阶版,能处理超复杂的任务。它会做多轮研究,每轮搞完还会写压缩笔记当成长期记忆,然后再开始下一轮。
整体目标就是让模型像个真正的研究员,自己会上网、会分析、会总结,最后给你一份报告。它的训练闭环是 Agentic CPT → SFT → RL,最后通过 on-policy 强化学习让模型自己卷自己,学会怎么更聪明地去推理。
🤖面试官:为什么它不需要像传统 RAG那样做chunk呢?
🤡答:DeepResearch 虽然用到了外部检索,但并不是传统意义上的 RAG。它没有预先 chunk 文档做 embedding,而是通过 agent 动态检索网页、筛选、摘要化再整合。
所以它是一个 Agentic RAG,核心在检索增强推理(Retrieval-Augmented Reasoning),而不是生成。检索只是它推理过程中的一个动作而已。
🤖面试官:那你觉得,这种 Agent 架构未来会取代 RAG 吗?
🤡答:我觉得不会完全取代,但是会融合。
长上下文(Long Context)让模型能读得更多,传统 RAG 让模型能读得准,而 DeepResearch 其实在验证一条新路:检索是模型自己行动的一部分,而不是一个外部的外挂模块。
未来的 Agent 框架,肯定都是在工具调用、动态检索、长记忆这三者之间找平衡。