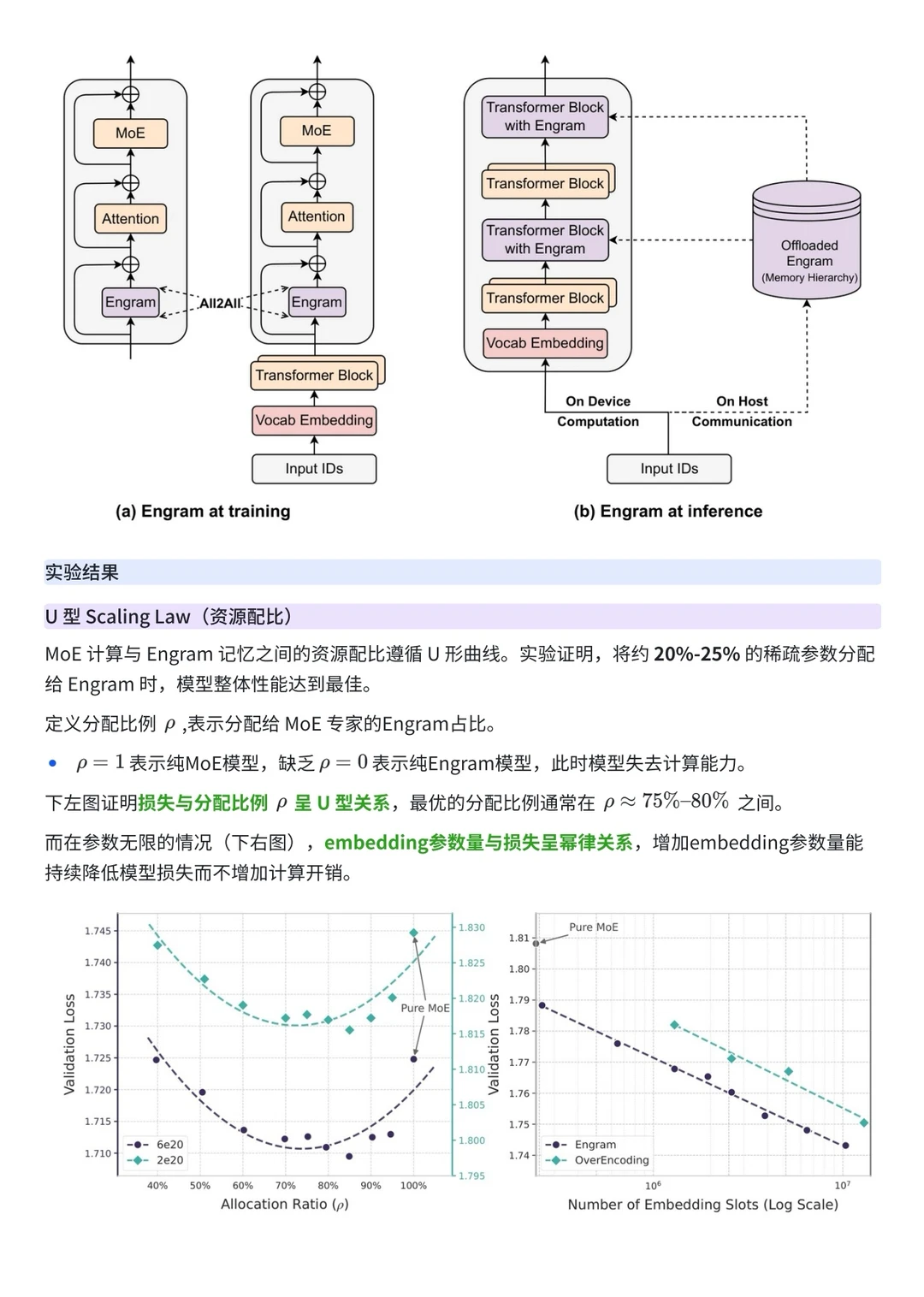
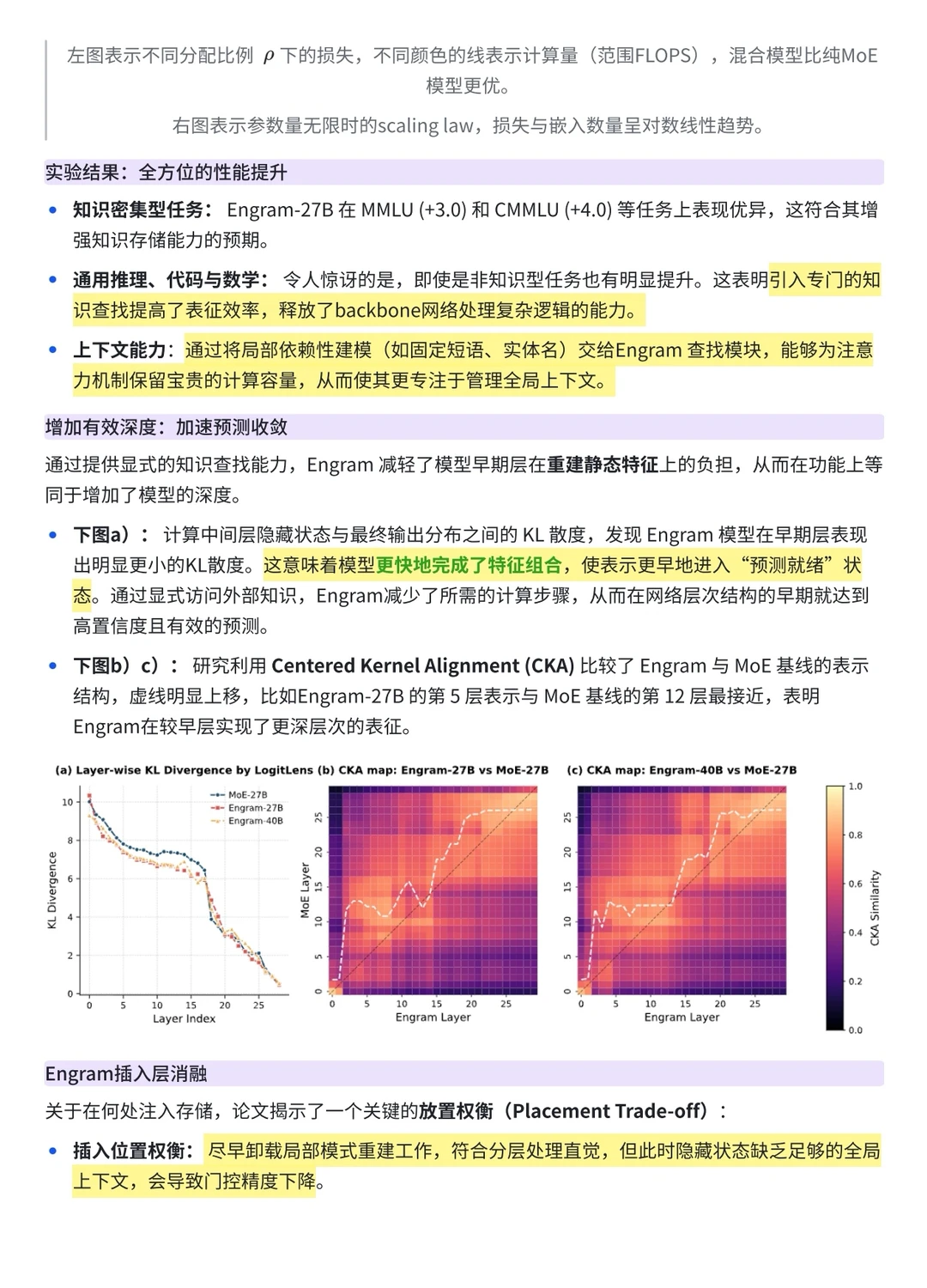
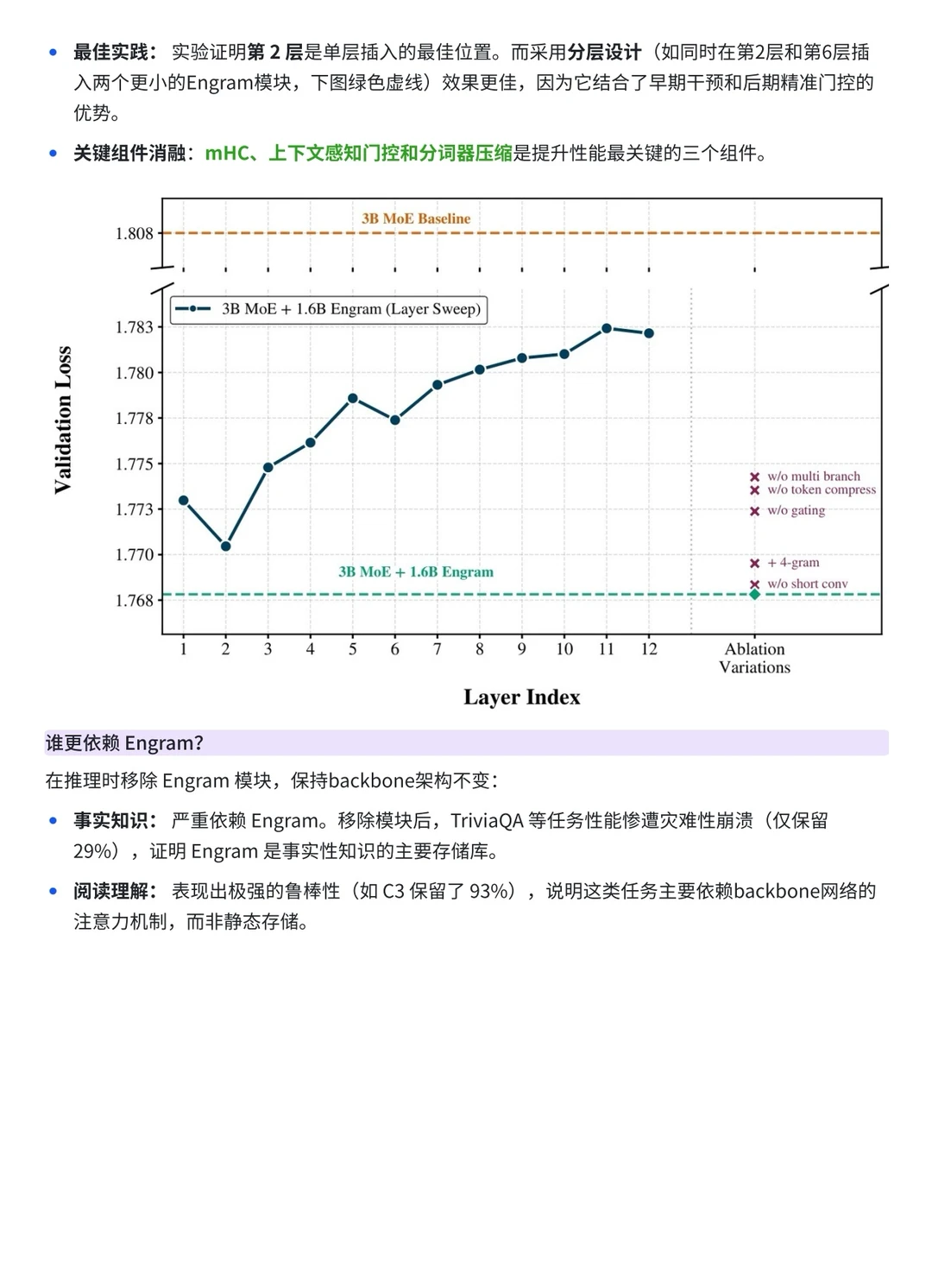
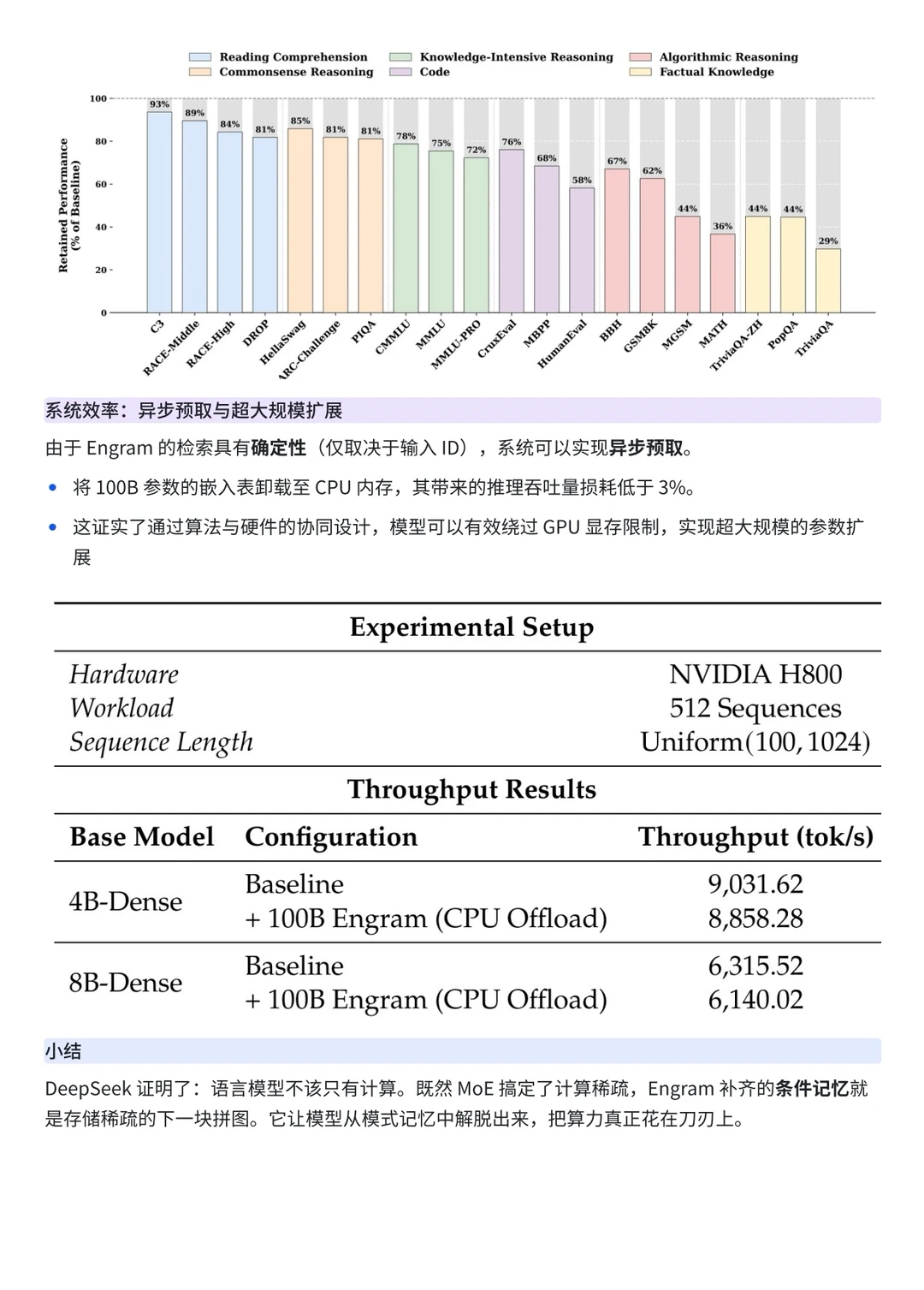
前段时间,DeepSeek 发布了论文《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》,提出了 Engram。
N-gram 这种基于马尔可夫假设的统计模型,这个诞生于上世纪 50 年代的老古董,在如今的大模型时代,本以为它会像 LSTM、RNN 一样,因处理不了长程依赖而被时代抛弃。
然而,DeepSeek 却通过 Engram 模块让它焕发了生机,证明了查表在 O(1) 复杂度下的极致魅力:既然有些知识是查字典就能解决的肌肉记忆,为什么还要动用昂贵的神经网络去推导?
本笔记从一下几个部分对原论文进行了解读:
1️⃣溯源:为什么 N-gram 是 LLM 的高效外挂?
2️⃣动机:语言的双重性与计算浪费
3️⃣Engram 架构设计:如何实现大规模哈希检索?
4️⃣实验结果