过去我们做多模态 RAG,要么拿 VLM 给图片写个 Caption,然后当纯文本搜;要么就是用 CLIP 或者 SigLIP 这种模型去做端到端,虽然 SigLIP 作为 CLIP 的改进版,在 Zero-shot 场景下确实能打,处理非统一分辨率图片时也更灵活。但是,在某些情况下,这两种方法都不太够用——比如当你的知识库里混合了长文本、复杂的统计图表、视频流时,单纯依靠 CLIP 这种粗粒度的双塔结构,往往需要大量的预处理和微调工作,而且很难捕捉到细粒度的图文交互信息。
今年 6 月份,Qwen3-Embedding(纯文本版)刚出时我就测过,它在跨语言检索和自定义维度(MRL)上的表现确实不错。而就在最近,Qwen 团队把这个能力延伸到了多模态领域,发布了 Qwen3-VL-Embedding 和 Reranker。
它不仅在 MMEB-v2 榜单上以 77.8 分拿下了 SOTA,它还两个工程上的痛点:一是统一了视觉文档(Visual Document)和视频的检索空间,不再需要拼凑多个模型;二是继承了套娃表示(MRL)和量化训练(QAT)。这意味着我们在部署时,可以像处理纯文本一样灵活地用 Int8 甚至更低精度来换取显存和速度,这对生产环境很友好。
今天这篇文章,我们就来解读一下Qwen3-VL-Embedding&Reranker的原论文吧,本文目录如下:
1️⃣架构解析
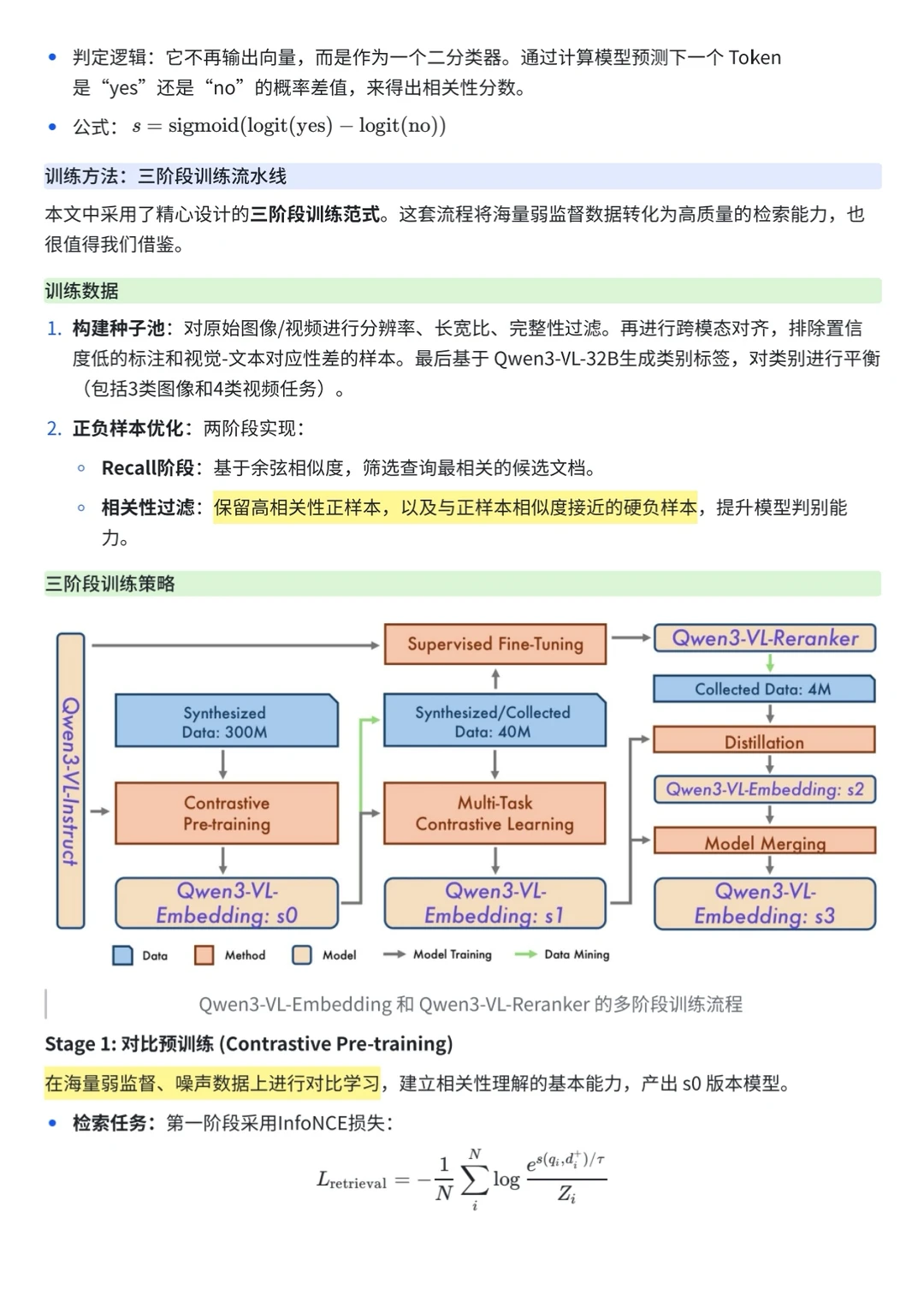
2️⃣训练方法:三阶段训练流水线
3️⃣工程落地实战:MRL、QAT 与架构权衡