前段时间,Qwen3-VL终于放出了技术报告,相较于2.5做了非常大的改动,从这些细节中我们也不难看出多模态大模型当下的演进趋势,一起来看看吧!
先来看Qwen3-VL在Qwen2.5-VL的基础上具体做了哪些改进:
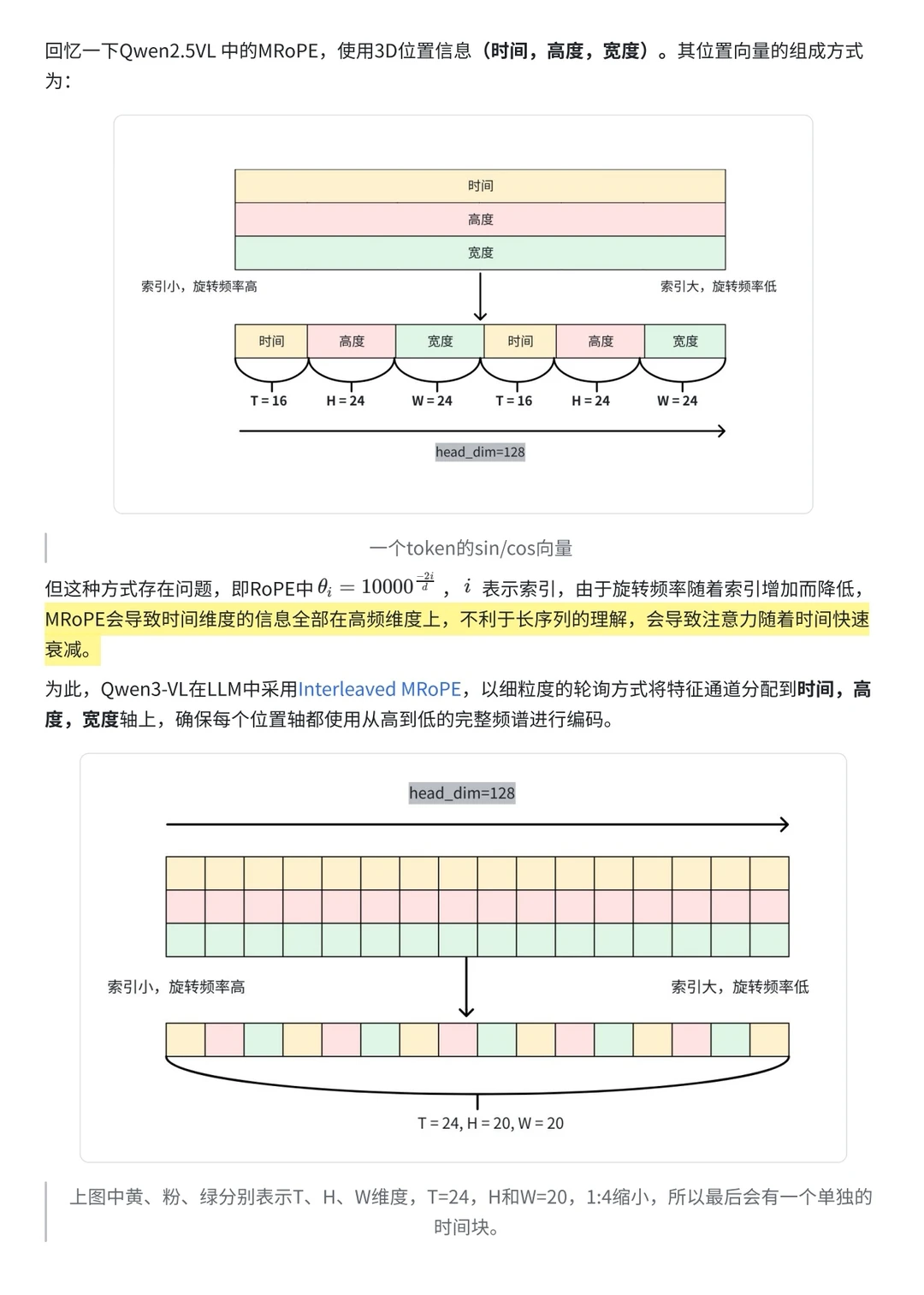
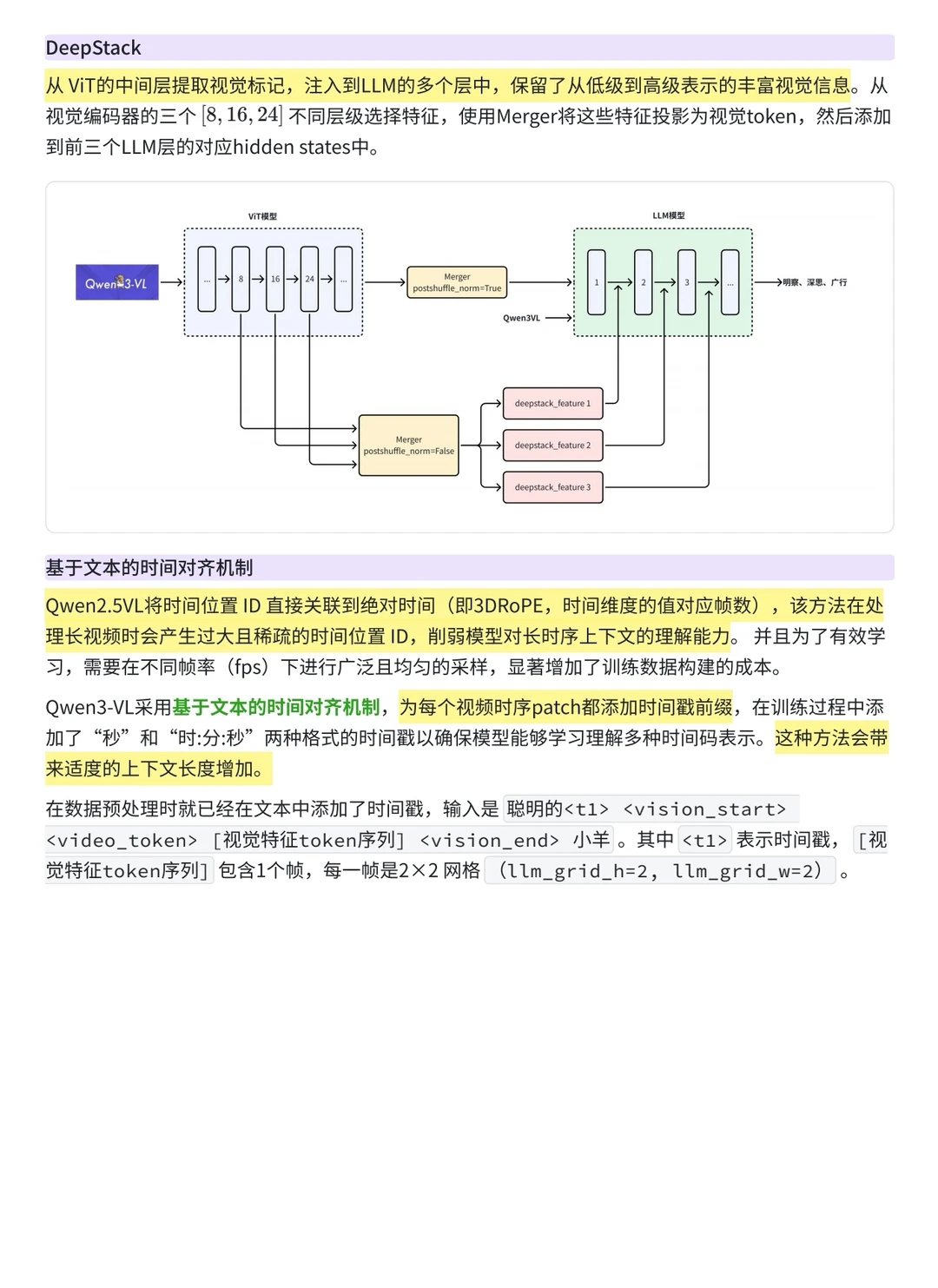
1️⃣从架构上来看,Qwen3-VL 依然沿用 ViT + Merger + LLM 的整体范式,但在模块交互和位置编码上引入了显著改进:它通过 DeepStack 能在深层网络中更有效的保留视觉信息,通过交错-MRoPE 和基于文本的时间对齐机制 解决了多模态长序列的时空建模瓶颈,从而实现了更强的时空感知能力。
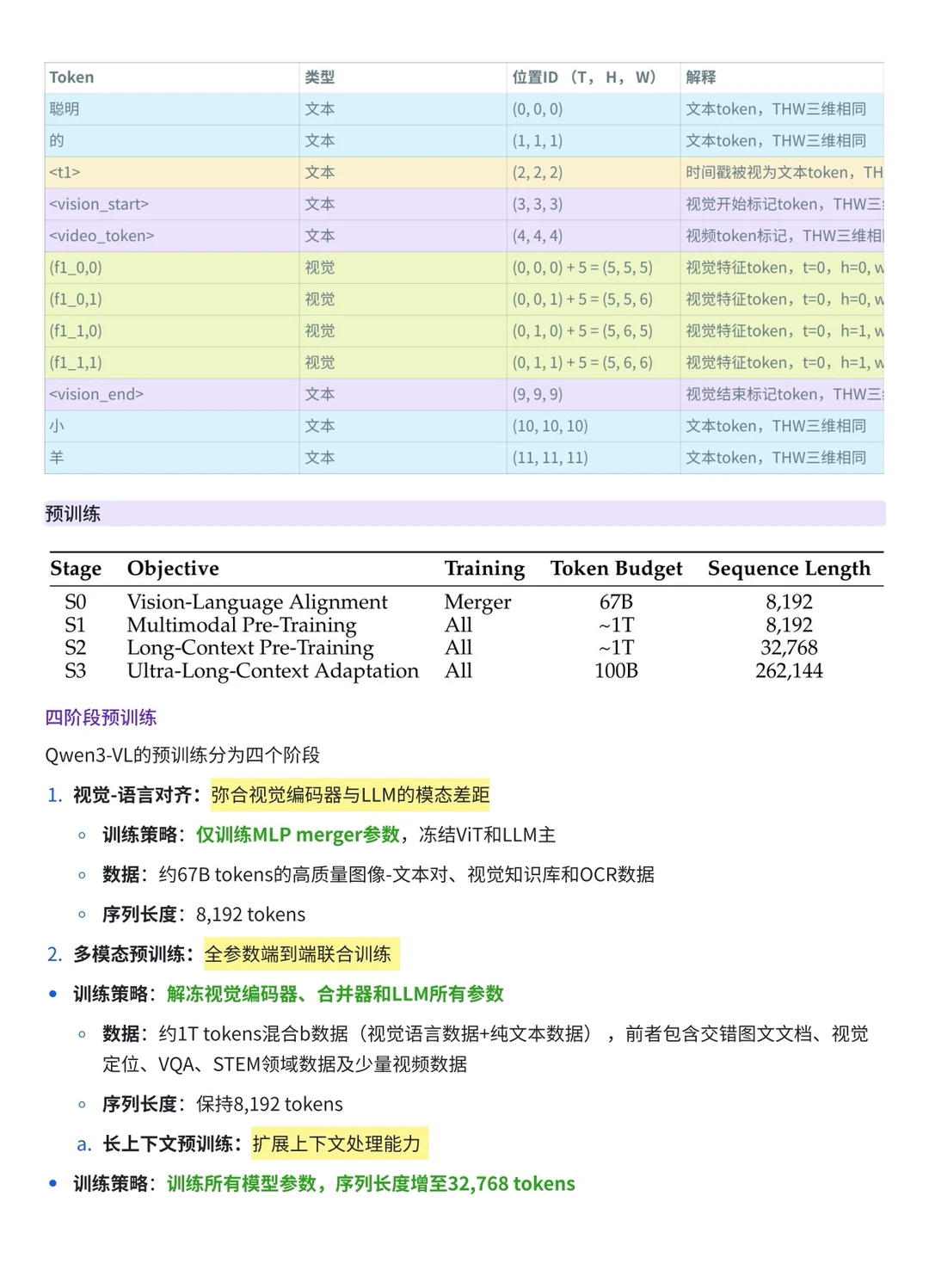
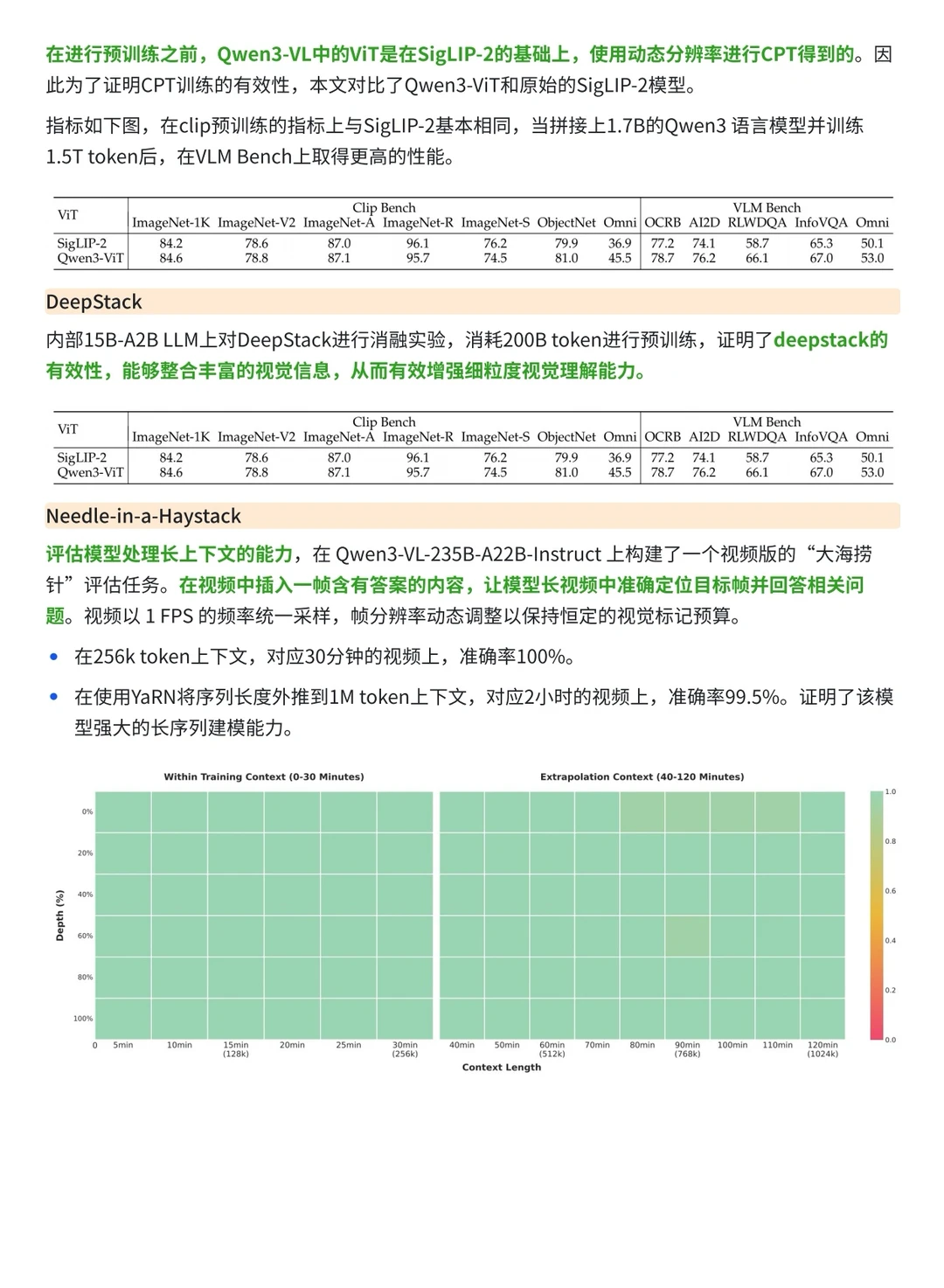
2️⃣从预训练流程来看,Qwen2.5-VL 采用经典的三阶段式训练,侧重于 ViT 的从头培养;而 Qwen3-VL 升级为四阶段,新增了专门的对齐阶段(Stage 0),并且在长窗口(Long Context)的训练上更加激进,将其拆分为两个阶段以冲击 256K 的超长上下文 。
3️⃣从后训练流程来看,这是变化最大的地方。Qwen2.5-VL 依靠传统的 SFT + DPO 组合 ;而 Qwen3-VL 引入了强弱知识蒸馏和强化学习 (SAPO算法)两个环节 ,标志着多模态模型从单纯的指令遵循向具备推理能力的 Agent演进。
总结来说,Qwen2.5-VL 是一个扎实的多模态理解模型,而 Qwen3-VL 则通过引入复杂的 RL 和蒸馏流程,试图将模型进化为一个具备慢思考能力和长窗口视野的多模态智能体(Agent)。
下一期我们再来看SAPO算法相对于GRPO算法的改进吧~