目前业界共识是纯文本 LLM 的 Scaling Law 正在放缓。单一文本维度的 Token 预测,在泛化性上已接近天花板。
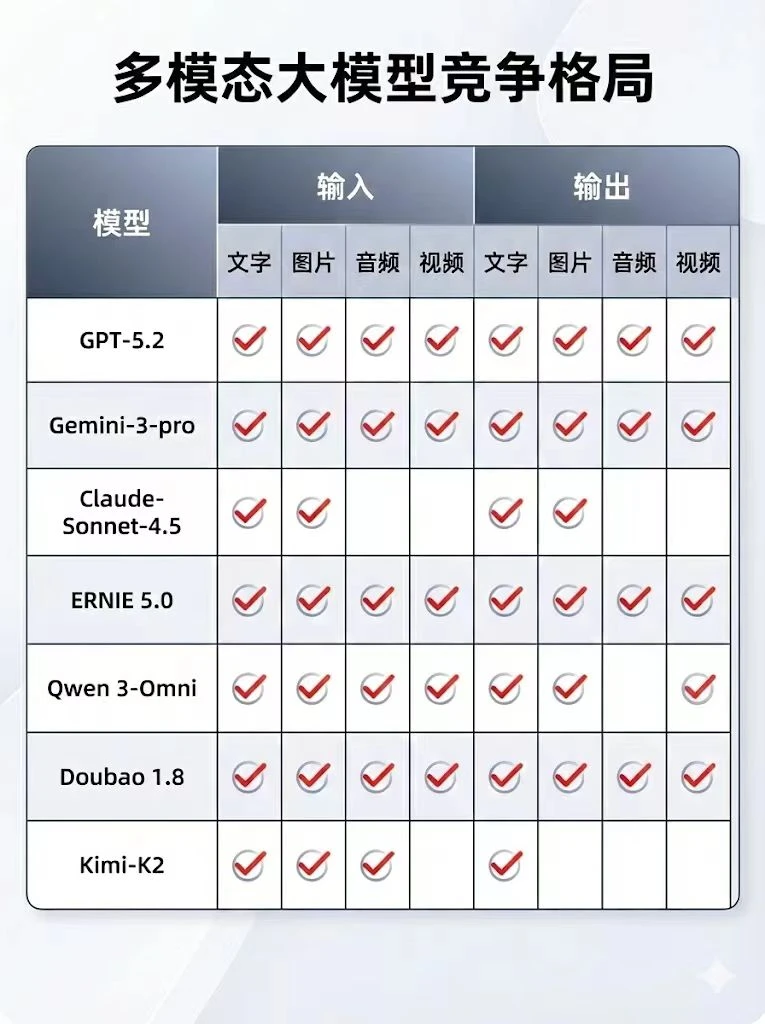
眼下主流的多模态,大多还是“胶水模型”的思路——各个模态搞独立的Encoder,再用Adapter拼起来,这导致了信息在跨模态传递时的严重失真。
而文心 5.0 这种 2.4 万亿参数的统一建模,本质上是在做信息密度的对齐。将视频、图像、音频在 Embedding 空间直接打通,这样才可以通过非语言信号来辅助模型理解物理世界,这其实就是World Model的前哨探索。
跳出技术架构,落到实际的商业化层面,推理成本是绕不开的硬指标,甚至能定义一个模型的商业化死线。文心5.0提到的3%激活参数比,我觉得特别有代表性——哪怕体量已经到了2.4T,依然在死磕推理能效比。
这也解释了为什么现在行业都在提“六边形战士”的重要性:当模型要落地到多模态实时交互场景,比如原生语音、视频流处理,推理开销会是纯文本的好几倍。这时候如果没有自研芯片(比如昆仑芯)和深度学习框架(比如飞桨)的算子级优化,单纯靠买H100堆算力,C端大规模推广的时候,商业模式根本跑不通。
而最终决定模型价值的,还是“超级入口”的争夺,这里的逻辑升级了,以前搜索是“给你一堆链接自己找”,现在是“直接给整理好的结果”,未来,肯定是“直接帮你把事做完”。
这也是为什么Google和百度一直被行业盯着——它们手里有最宝贵的真实世界闭环场景,比如搜索、地图、自动驾驶。大模型迭代离不开这些真实场景的反馈数据(不管是RLHF还是RLAIF),靠这些数据才能不断调准意图识别的精度。没有这些“入口”,再聪明的模型也只是困在服务器里的大脑,没法在物理世界落地,更谈不上创造价值。
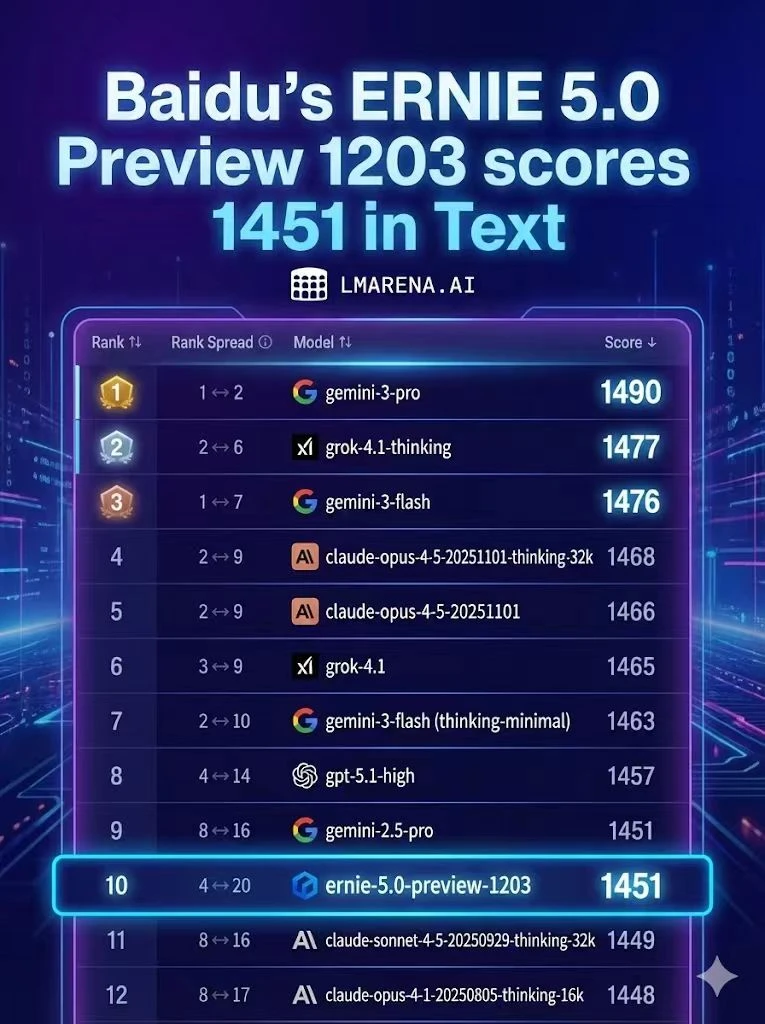
回到这次LMArena的排名,更值得关注的是ERNIE-5.0-Preview-1203的表现——不仅以1451分跻身前10,超过了Claude Sonnet 4.5、GPT-5.2等前沿模型,更是榜单前20中唯一的非美国模型。而这份排名背后,有价值的信息点在于:
1️⃣数据的异构对齐:在 2.4T 参数下,如何保持文本逻辑不被庞大的视频/图像数据冲淡?
2️⃣端侧部署: 随着豆包、文心等模型向手机 OS 和硬件下沉,端云协同的推理架构(Speculative Decoding 等技术)将成为真正的战场。
说到底,AI竞争早就从“单点技术突破”进入“系统能力比拼”的阶段了。榜单也就当个参考,能落地、能创造价值的系统,才是未来的核心。