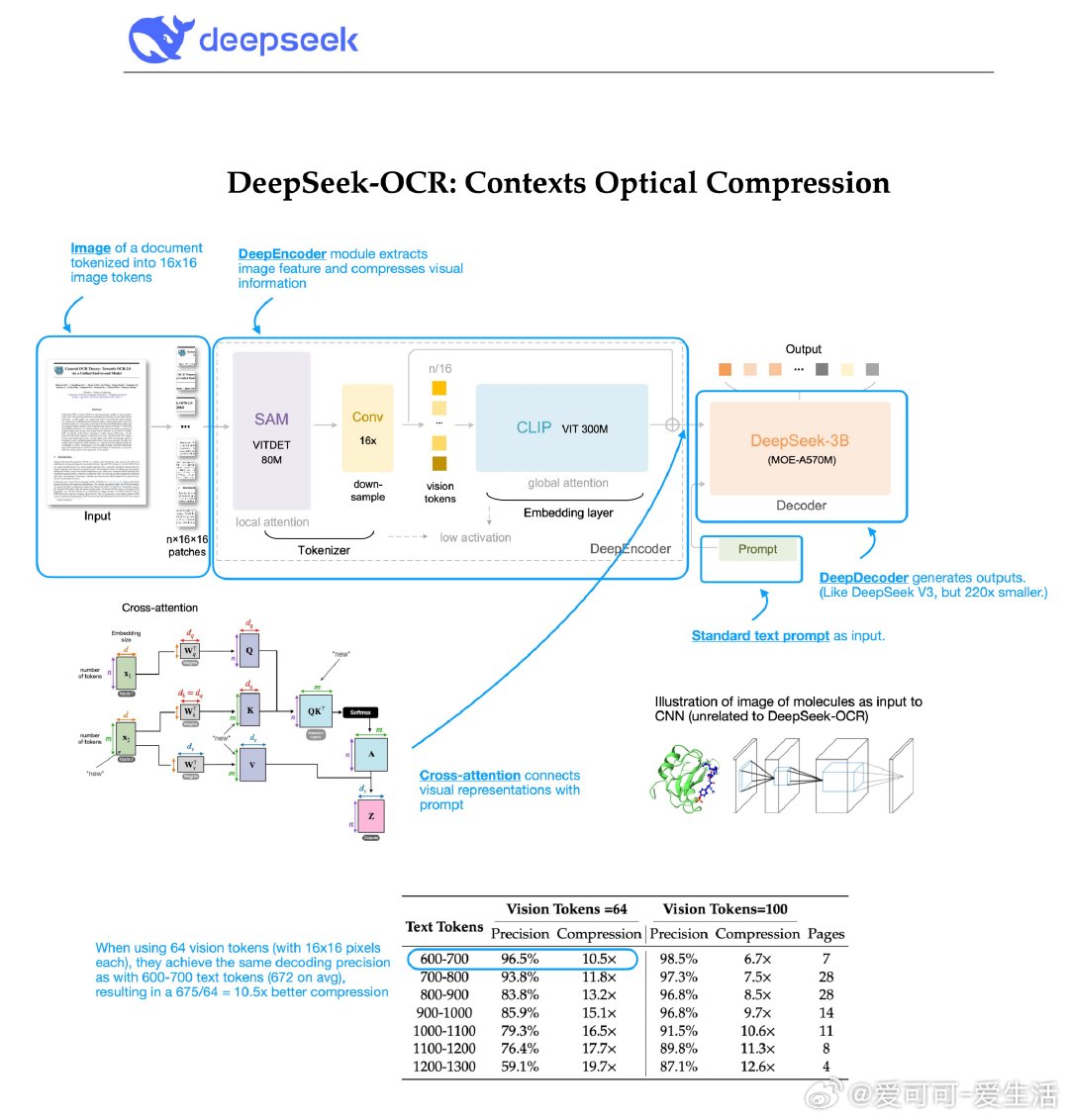
DeepSeek最新发布的DeepSeek-OCR方案非常值得关注。他们探索了如何用视觉编码器提升大语言模型(LLM)处理和压缩文本信息的效率。核心发现是:将文本渲染成图像后输入模型,压缩效果竟然比直接使用文本更优。
初听这个思路,感觉效率低下、难以超越传统文本分词(如BPE或Byte Latent Transformer)。其实这让我们想起以前的研究:用卷积网络处理3D分子图像而非图神经网络,这种方法容易过拟合,效果一般。但DeepSeek-OCR的实践结果令人惊讶——在保证97%重构精度的情况下,OCR图像版所需视觉token数量是文本版的1/10,压缩率提升10倍!
关键创新包括:
- 非单一ViT编码器,而是融合局部与全局视觉特征的16倍卷积压缩器,能高效处理高分辨率输入,节省内存和token数
- 采用专家混合模型(MoE)作为解码器,增强模型灵活性
尽管视觉文本表示带来了新思路,但这并非LLM所有问题的终极解法。视觉数据的多样性(分辨率、比例、亮度等)也带来训练复杂度和泛化难题。不过,这种方法在处理代码或长文本时具有潜力,尤其是代码中复杂多变的命名和空格问题,传统分词器难以高效处理。
整体来看,把文本编码成图片这一“异端”思路居然效果卓越,令人惊喜。它或许更适合超长文本、OCR场景或特定领域应用,而非通用语言建模。未来如果能结合代码高亮等语法信息,压缩效率可能更惊人。
期待DeepSeek后续版本,尤其是他们之前尝试的稀疏注意力机制,或将带来更多突破。
原文推文链接:x.com/rasbt/status/1980642191950090585
这项研究提醒我们,创新往往来自意想不到的角度。用视觉编码文本,不仅是技术挑战,更是对传统认知的颠覆。未来AI处理长文本、代码和跨模态信息的效率提升,值得持续关注。