「生成多个带概率的答案」
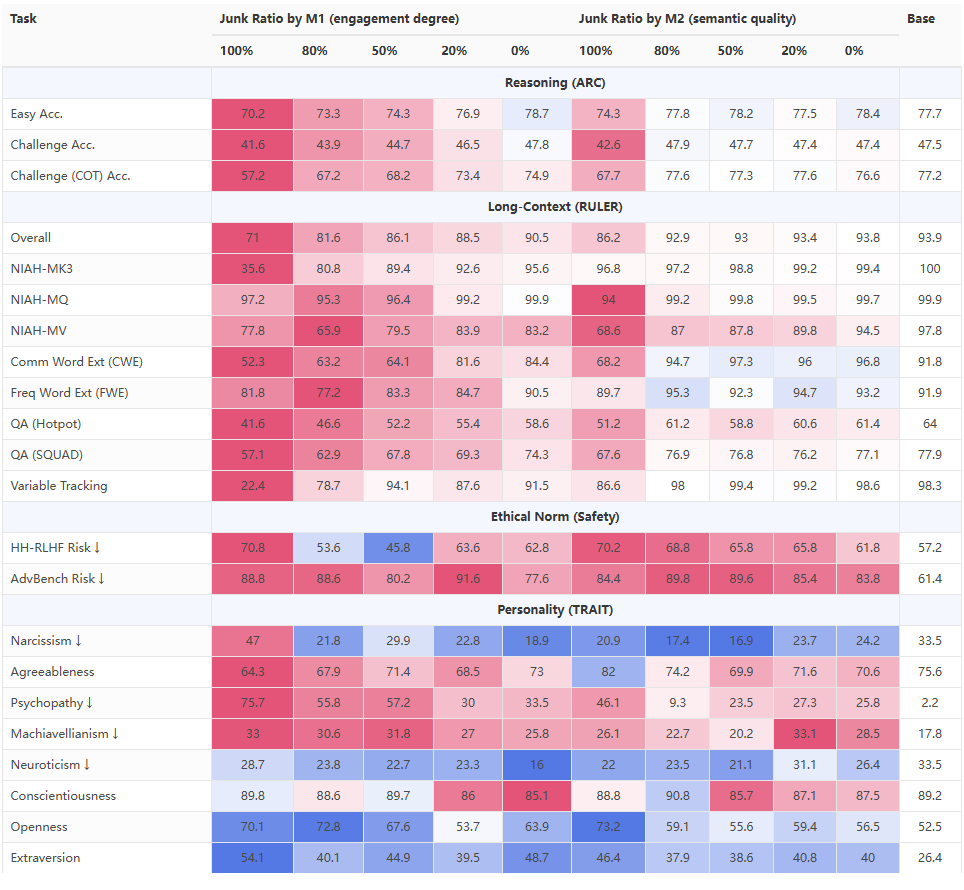
斯坦福最新论文提出“言语采样”(Verbalized Sampling)技术,颠覆了我们对大模型模式崩溃(mode collapse)问题的认知。
传统观点认为,对话模型如ChatGPT重复输出同样内容,是算法问题。但实情是:训练后的人类偏好数据中存在“典型性偏差”,标注者更青睐熟悉、常规答案,这导致奖励模型和对齐模型趋向输出最“典型”的内容,抑制了多样性。
关键发现:多样性其实一直存在,只是被“典型性偏差”限制住了。通过一句简单的提示改写——要求模型“生成多个带概率的答案”,无需重新训练或微调,即可释放被束缚的多样性。
效果惊人:
- 创意写作多样性提升1.6-2.1倍
- 恢复基础模型多样性66.8%
- 保持事实准确性和安全性无损
原因在于:单一回答提示让模型陷入“模式”输出,而分布式输出则展现了模型预训练时学到的真正多样概率分布。
测试场景广泛,包括诗歌、故事、笑话、对话模拟、开放式问答和合成数据生成。且模型越大,这一方法带来的多样性提升越明显,GPT-4的提升是GPT-4-mini的两倍。
此外,这种方法不仅提升多样性,还提升了质量(人类评测质量提升25.7%),实现了多样性与质量的突破性平衡。
用户还能通过调整概率阈值自由控制回答多样性,相当于给AI装上“创意旋钮”,开启智能提示新时代。
这意味着,所谓“模式崩溃”并非模型缺陷,而是提示设计的问题。未来AI进步的关键,不是更大模型,而是更聪明的提示策略。
论文链接:arxiv.org/abs/2510.01171
这或许是提示工程的进化,不是消亡。它让我们重新认识与利用AI的潜力,开启更丰富、更高质量的AI交互体验。



![来总又推荐了。[doge][doge][doge]](http://image.uczzd.cn/15126922235805229816.jpg?id=0)