[LG]《Robust Layerwise Scaling Rules by Proper Weight Decay Tuning》Z Fan, Y Liu, Q Zhao, A Yuan... [MIT & UCLA] (2025)
近年来,大规模语言模型训练依赖于经验缩放定律指导参数、数据和计算资源的分配,同时最大更新参数化(µP)方法实现了学习率在不同模型宽度间的迁移。但现代归一化架构中,训练很快进入一个由优化器主导的稳态,归一化层对反向传播产生尺度敏感性,导致有效学习率依赖宽度,破坏了µP的迁移效果。
本文突破这一瓶颈,提出了针对AdamW优化器的权重衰减(weight decay)缩放规则,确保不同宽度下子层增益保持不变。核心发现包括:
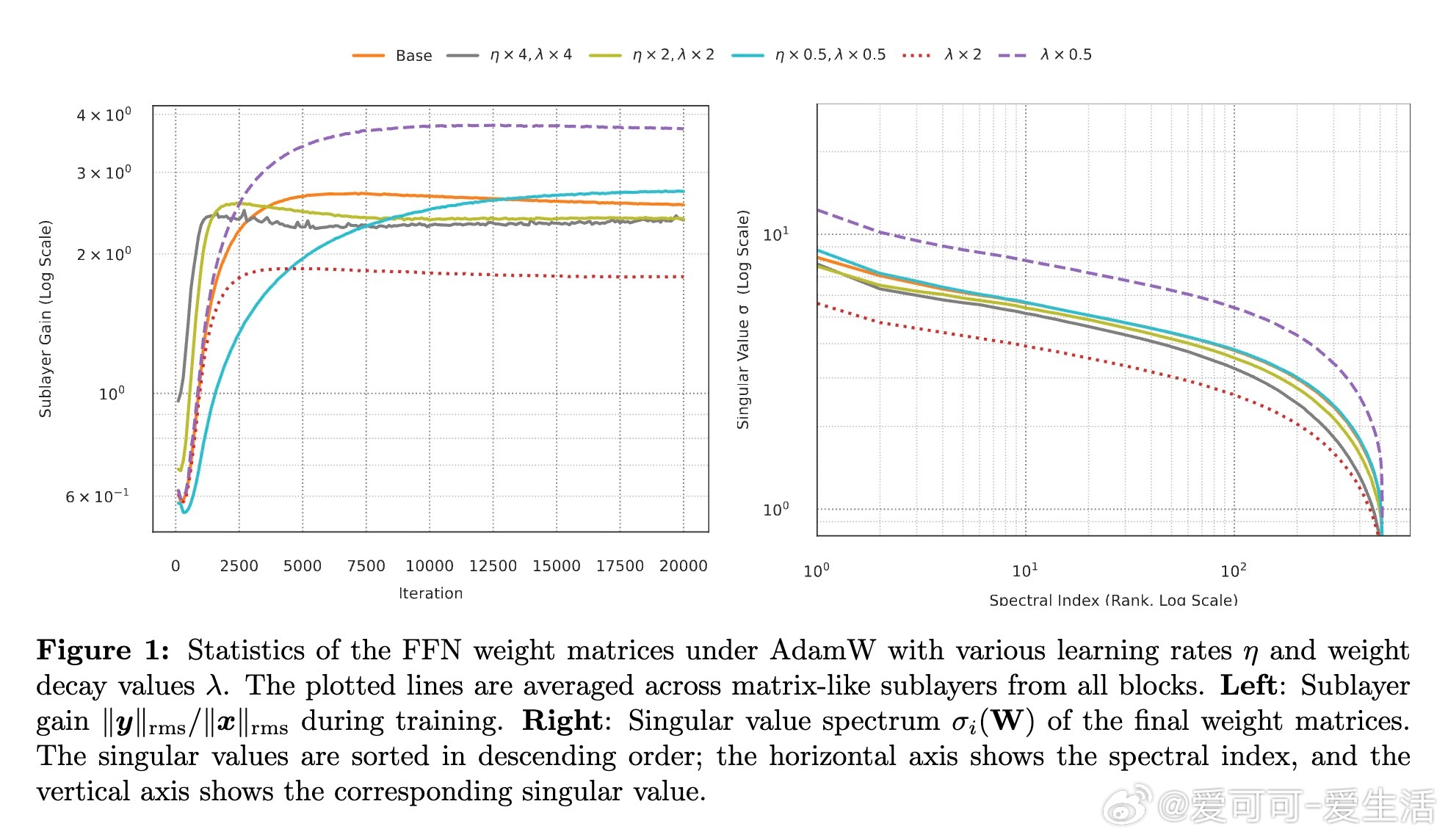
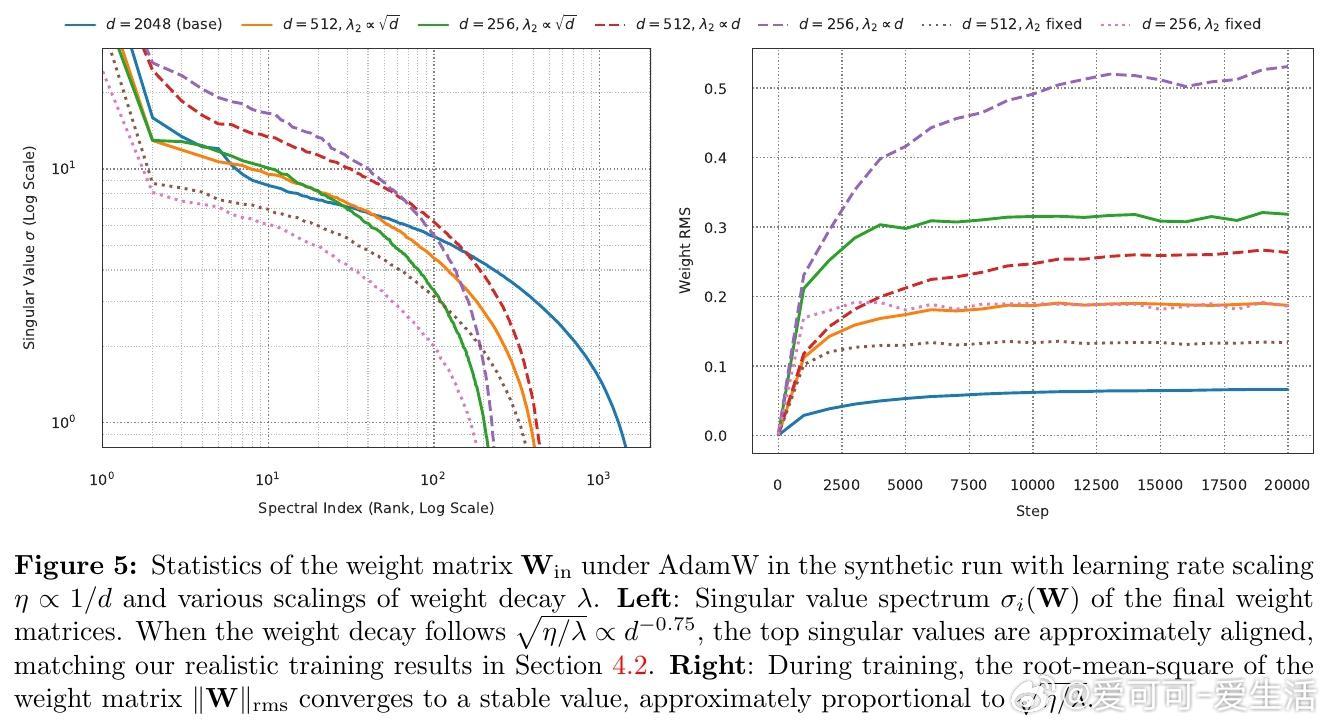
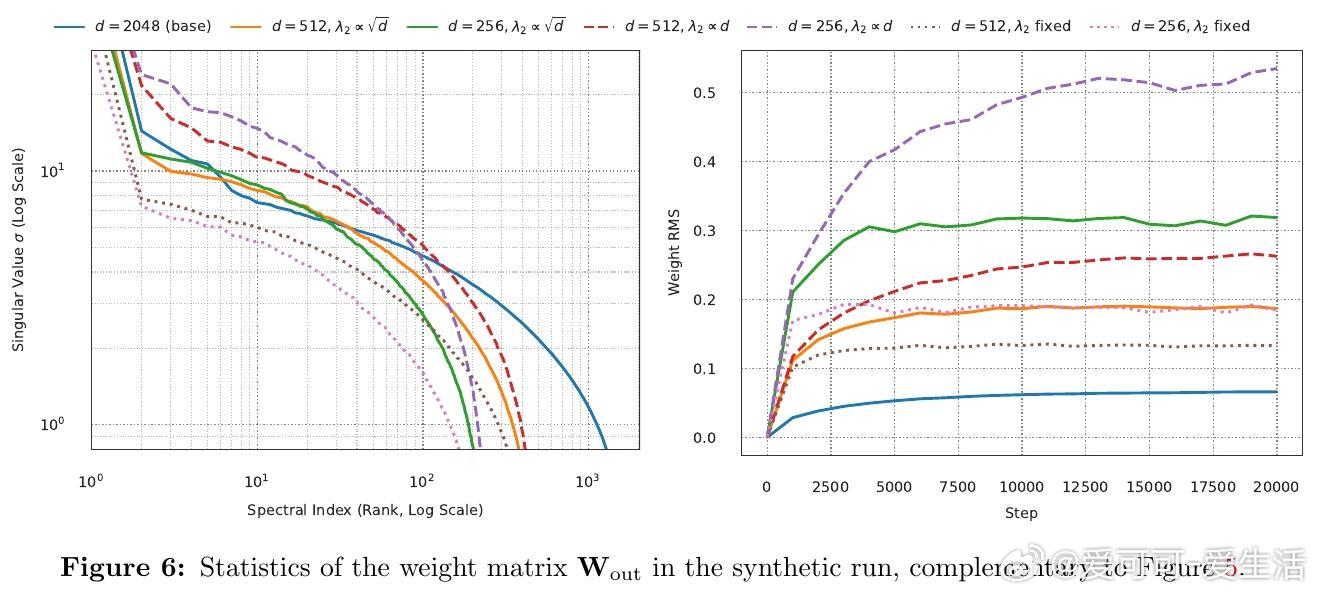
1. 在AdamW稳态训练下,权重矩阵的奇异值谱整体按√(η/λ)比例缩放,谱形几乎不变。宽度d变化时,最大奇异值约按√(η/λ)·d^0.75缩放。
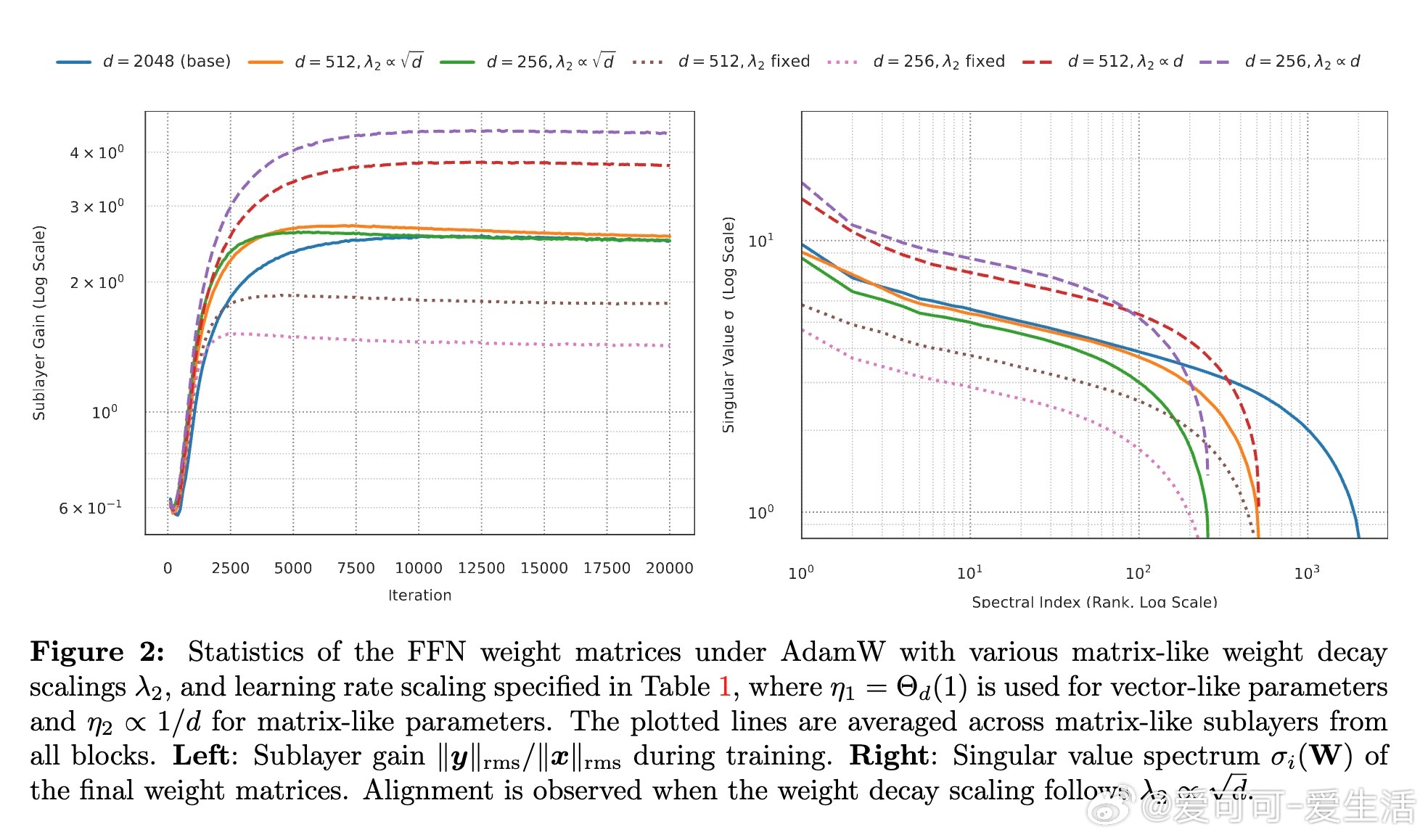
2. 结合µP对矩阵参数学习率η2∝d^(-1)的规则,推导出权重衰减应按λ2∝√d缩放,保持子层增益宽度不变。
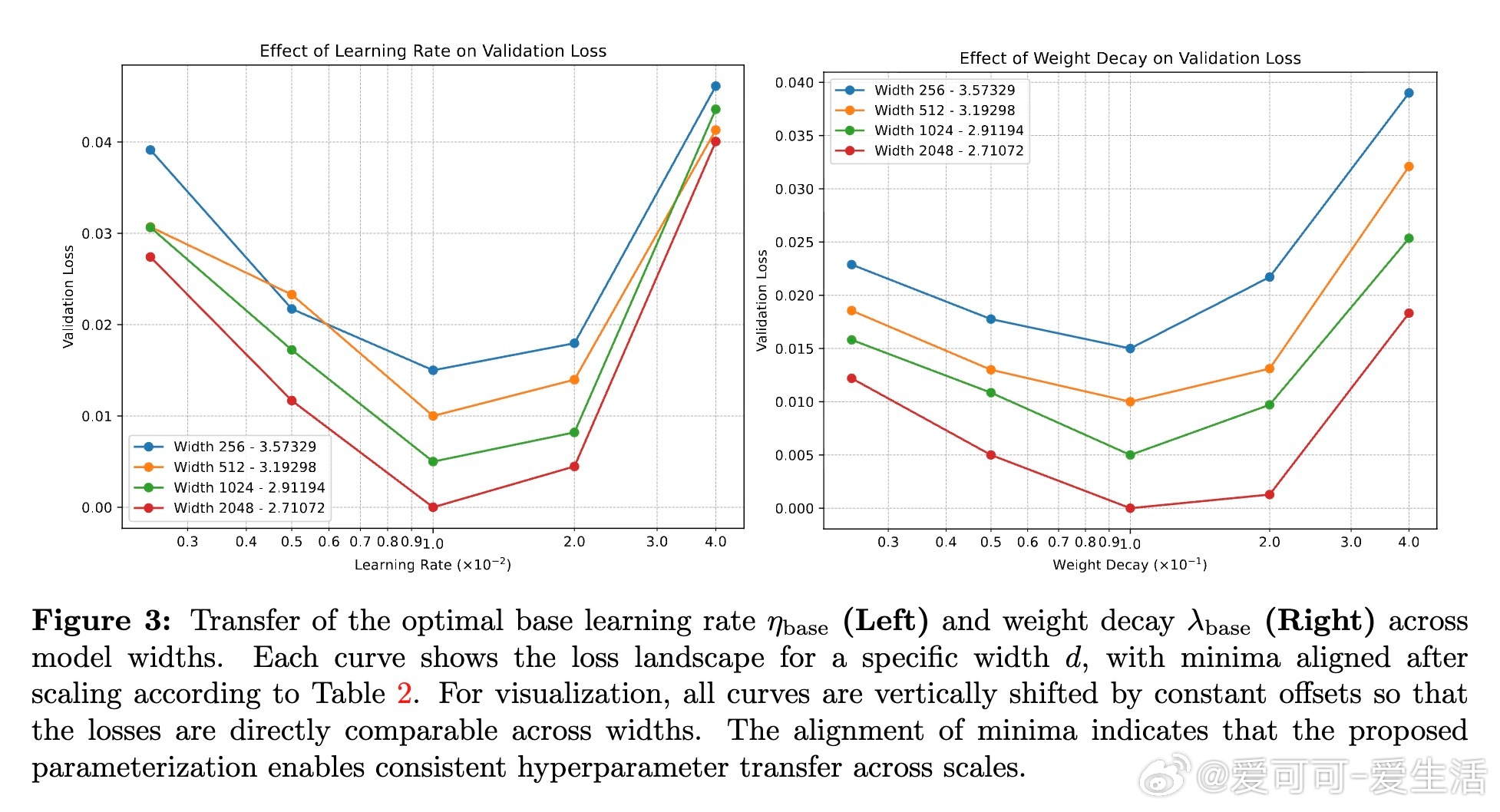
3. 向量类参数(如嵌入层、规范化增益)采用常数学习率η1=Θd(1)且无权重衰减λ1=0;矩阵类参数则用上述缩放规则。此参数化实现了从小模型代理到大模型的零样本超参迁移,避免了对每个宽度的超参调优。
4. 在LLaMA-风格Transformer及合成数据上验证了该规则,且提供了通过匹配最大奇异值来检测子层增益不变性的简单诊断方法。
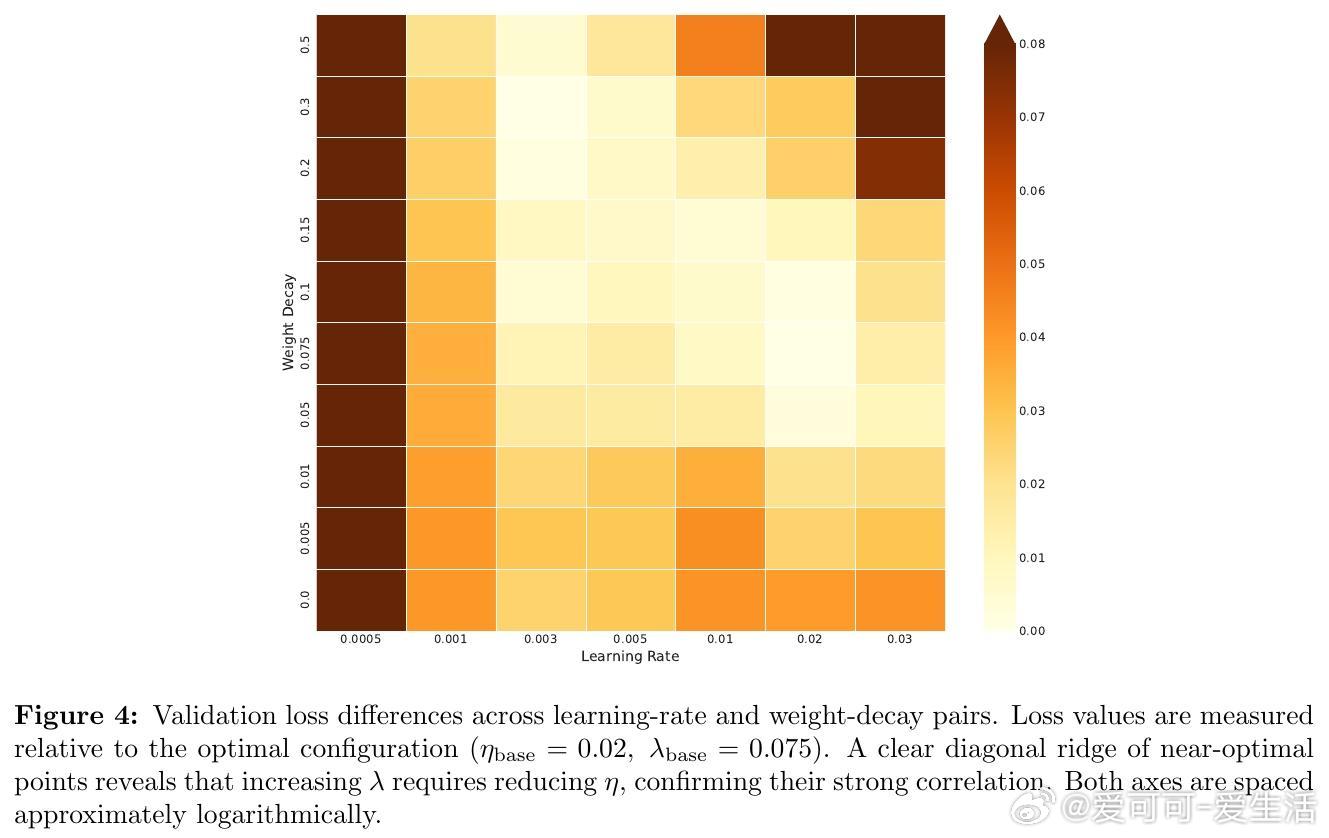
此外,作者分析了学习率与权重衰减间的相互影响,发现二者存在一条近似对角的最优配置路径,调节其中之一须同步调整另一超参。论文还指出,权重衰减缩放规则源自模型架构本身,与数据分布无关,暗示了训练动态中潜在的随机矩阵理论与均场行为。
本研究拓展了µP理论至训练稳态阶段,提供了实用的宽度鲁棒超参迁移方案,对大规模Transformer训练与调优具有重要指导意义。未来方向包括探索其他优化器、混合专家模型、深度扩展及基于数据分布的理论构建。
原文链接:arxiv.org/abs/2510.15262
机器学习 深度学习 Transformer 超参数调优 大规模训练 AdamW 权重衰减 模型缩放