[LG]《Learning Correlated Reward Models: Statistical Barriers and Opportunities》Y Cherapanamjeri, C Daskalakis, G Farina, S Mohammadpour [MIT EECS] (2025)
《学习相关奖励模型:统计障碍与机遇》——最新研究揭示偏好学习新视角
随机效用模型(RUM)是理解人类偏好的经典框架,广泛应用于心理学、交通经济学、市场营销,近年来更是强化学习从人类反馈(RLHF)中的核心环节。然而,传统模型普遍依赖“无关选项独立性”(IIA)假设,简化了人类偏好为单一效用函数,忽略了偏好间复杂相关性,导致模型表达力受限。
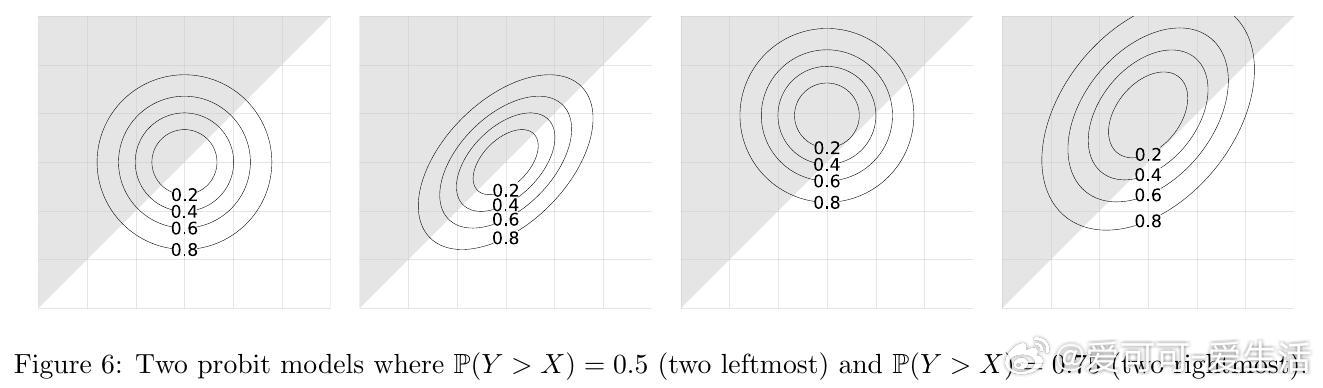
本论文聚焦于突破IIA限制的相关Probit模型,效用向量服从多元正态分布,能够捕捉偏好间的相关结构。关键贡献包括:
1. 统计数据需求的根本性突破:经典的两两偏好比较数据无法识别相关性,存在无限多组模型参数可解释相同数据,导致统计和计算上的不确定性。
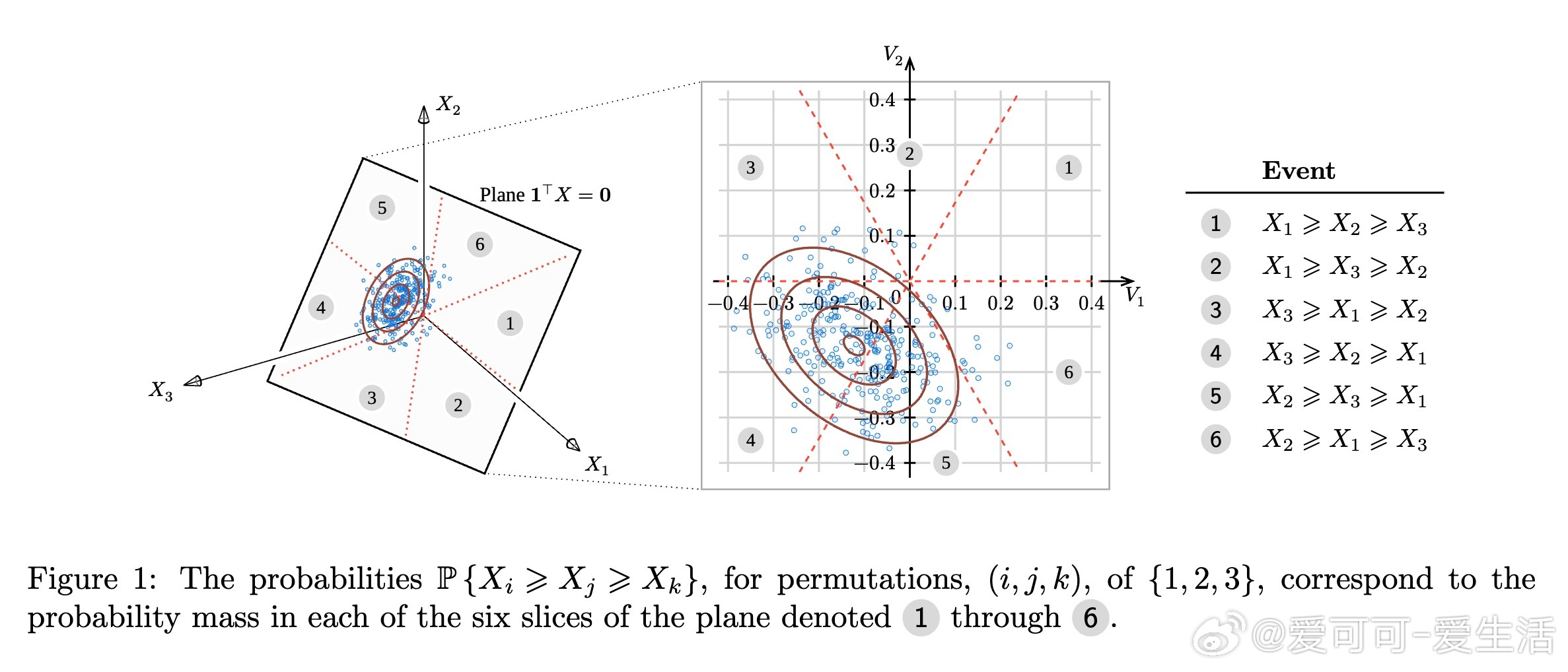
2. 三选一偏好数据的必要性与充分性:作者证明了“最佳三选一”偏好数据既是识别模型参数的必要条件,也是充分条件,极大丰富了可观测信息。
3. 构建高效估计器并提供有限样本理论保证:设计了基于三元偏好数据的多项式时间估计算法,理论上近似最优,具有高置信区间下的误差界限。
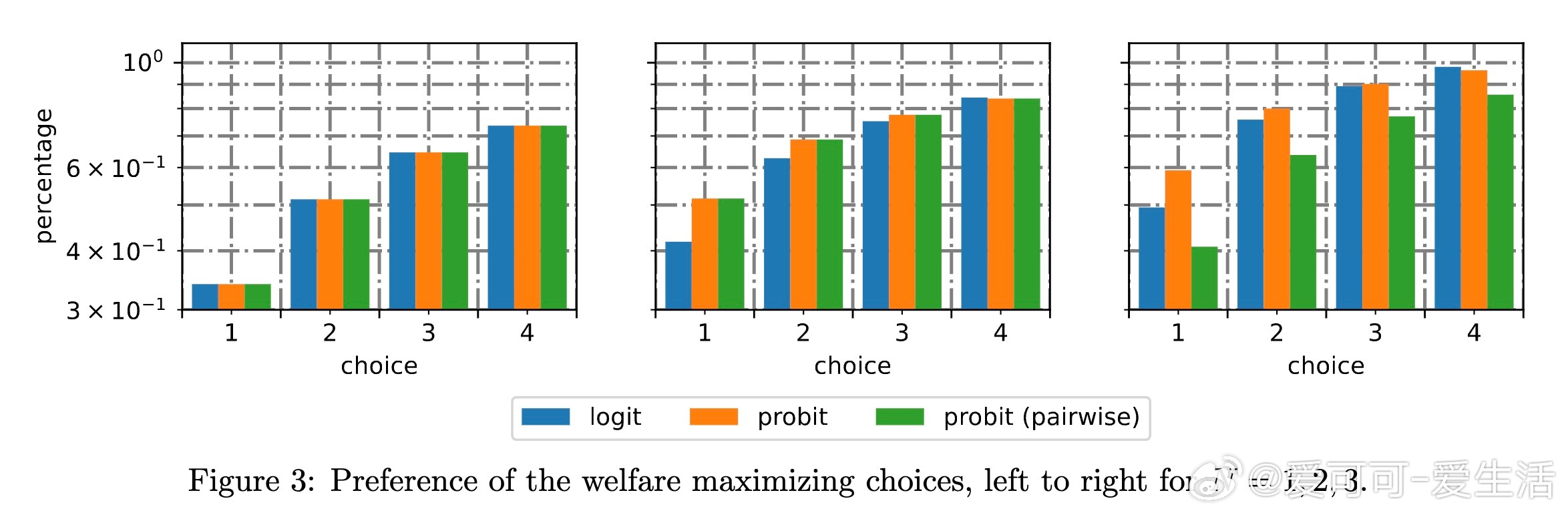
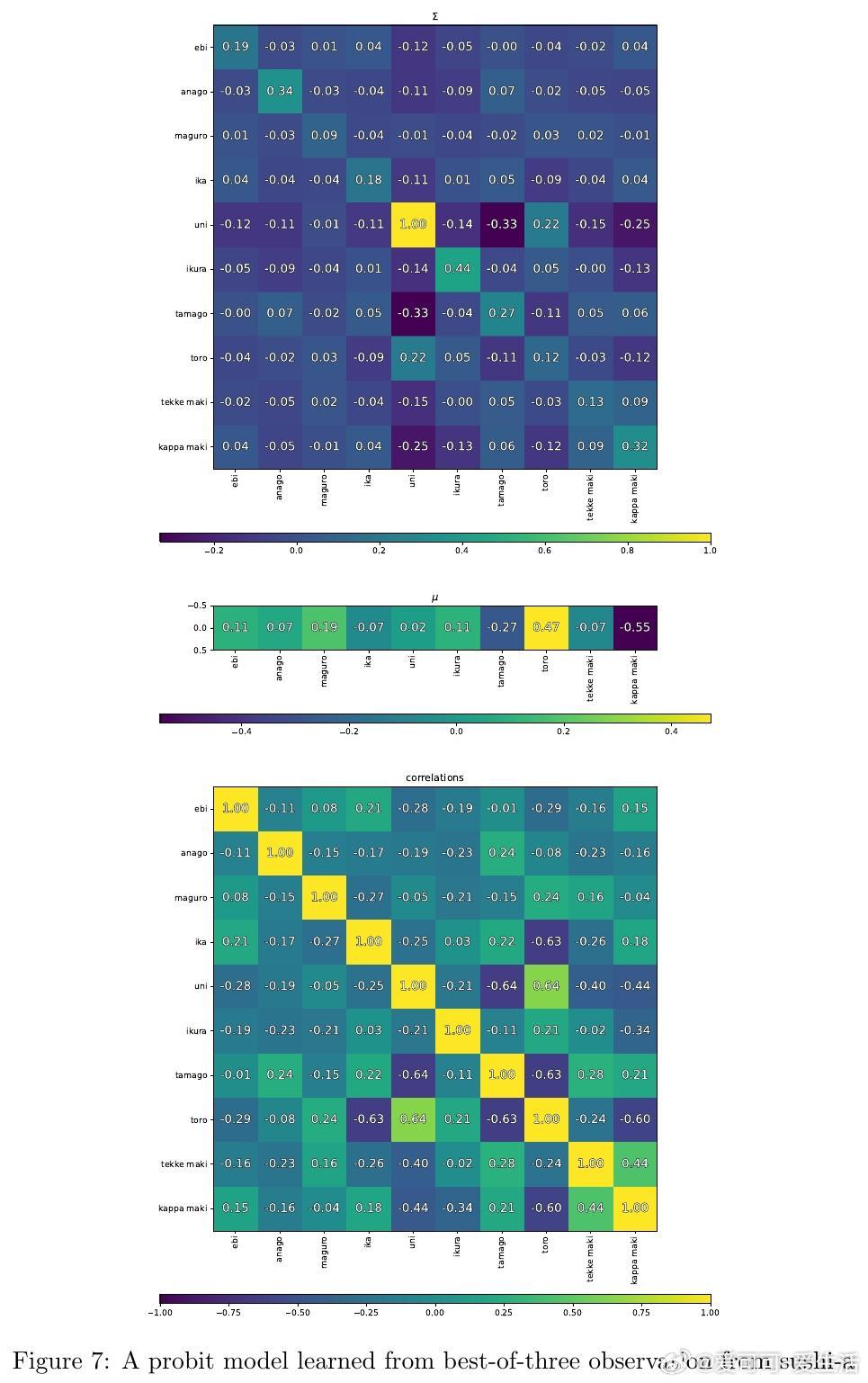
4. 实证验证与应用:在多个真实数据集(如Sushi偏好、Netflix电影评分、MovieLens数据集)中,三元偏好训练的相关Probit模型表现优于传统logit和两元Probit模型,能更精准地捕捉用户个性化偏好及偏好相关性,辅助更合理的福利最大化决策。
5. 理论与实践的桥梁:论文不仅深入讨论了模型的数学结构与参数可识别性,还针对实际大规模偏好学习中的样本复杂度和计算效率提出了创新的图结构采样策略,显著降低了样本需求规模。
研究启示:
- 传统只收集两两比较数据的偏好学习方法存在根本局限,未来采集更复杂的多元偏好信息势在必行。
- 相关偏好模型为个性化推荐、决策优化等领域提供了更细粒度的人类偏好表征工具。
- 该工作为RLHF及大语言模型调优中的“奖励建模”提供了新的理论基础和算法支持,助力更精准地捕捉人类多样化偏好。
论文地址:arxiv.org/abs/2510.15839
机器学习 偏好学习 随机效用模型 强化学习 人类反馈 统计学习 推荐系统