[LG]《The Coverage Principle: How Pre-training Enables Post-Training》F Chen, A Huang, N Golowich, S Malladi... [Microsoft Research & MIT & UIUC] (2025)
深度解析预训练如何助力后期训练——覆盖原理新视角
语言模型的强大能力主要来源于两阶段训练:大规模预训练(基于下一词预测的交叉熵损失)和针对任务的后期训练(如强化学习)。然而,预训练的损失指标(交叉熵)往往不能准确预测下游任务表现,甚至可能出现负相关。
本文提出“覆盖剖面(Coverage Profile)”这一关键概念,量化预训练模型对高质量响应赋予的概率质量。理论证明,覆盖剖面优良是后期训练及测试时采样(如Best-of-N)成功的充分且必要条件。
核心贡献包括:
1. 覆盖原理:下一词预测天然隐式优化覆盖剖面,且覆盖剖面较交叉熵具有更快的泛化速度和更少对序列长度等问题依赖参数的敏感性。
2. 覆盖与交叉熵的局限:交叉熵随序列长度线性增长,导致预训练指标难以准确反映下游性能;而覆盖剖面避免了这一问题,更能反映模型对稀有高质量响应的支持能力。
3. 算法干预:
- 模型或检查点选择策略基于覆盖剖面比交叉熵更能筛选出适合后期训练的模型。
- 梯度归一化(类似Adam优化器)显著提升覆盖,去除序列长度依赖。
- 测试时解码策略(如测试时训练)进一步改善覆盖水平。
- 教师指导蒸馏中采纳截断梯度方案,提升覆盖表现。
4. 理论保证:
- 针对自回归线性模型,证明覆盖剖面期望误差与训练样本数、模型复杂度以及数据的“内在方差”相关,且对序列长度依赖弱。
- SGD存在序列长度依赖的覆盖劣势,归一化方法可缓解此问题。
- 提出覆盖优化的锦标赛(tournament)模型选择方法,保证选出覆盖最佳模型,且适用于模型类不完全匹配的情况。
5. 实验验证:
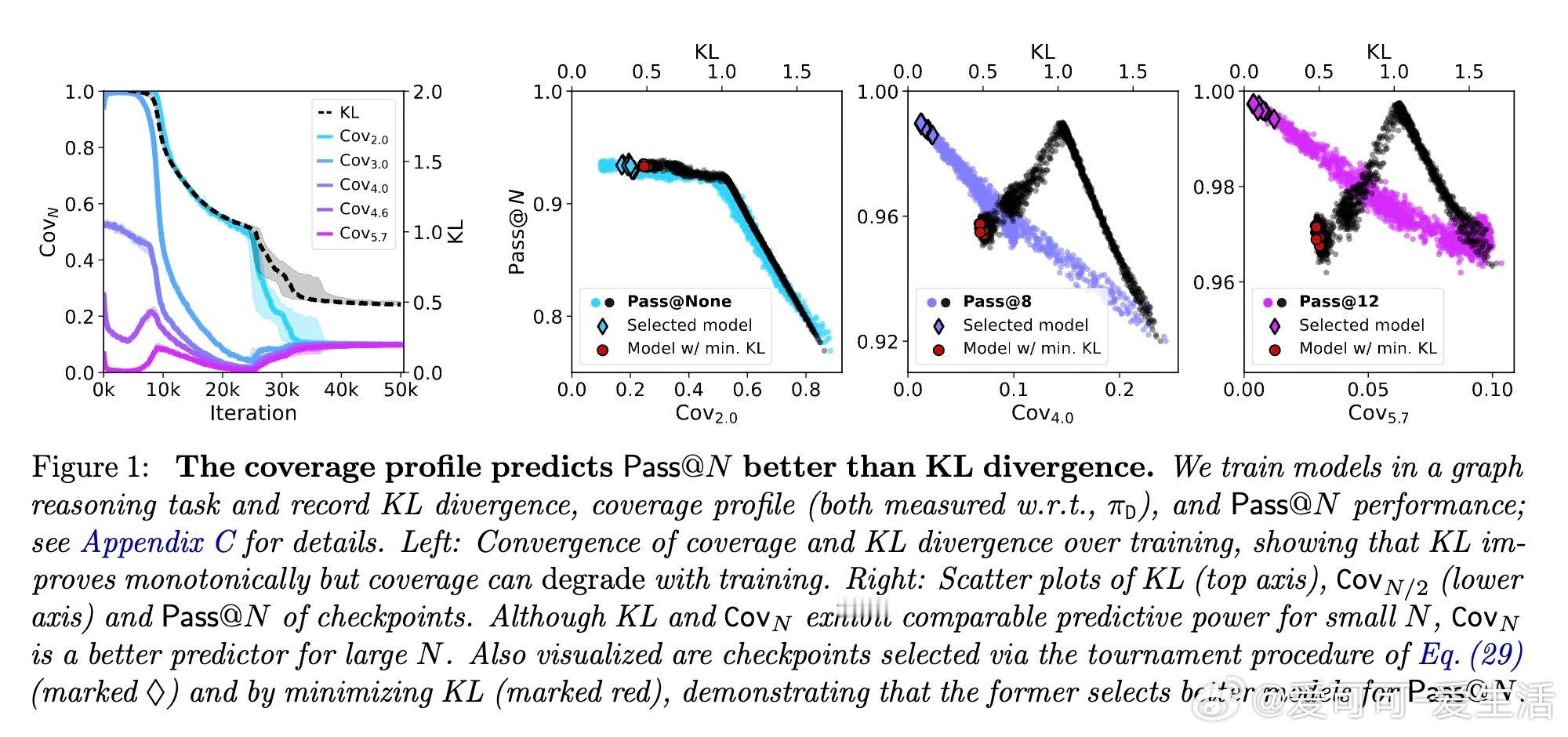
- 图推理任务中,覆盖剖面与后期训练性能高度相关,而交叉熵指标则可能误导选择。
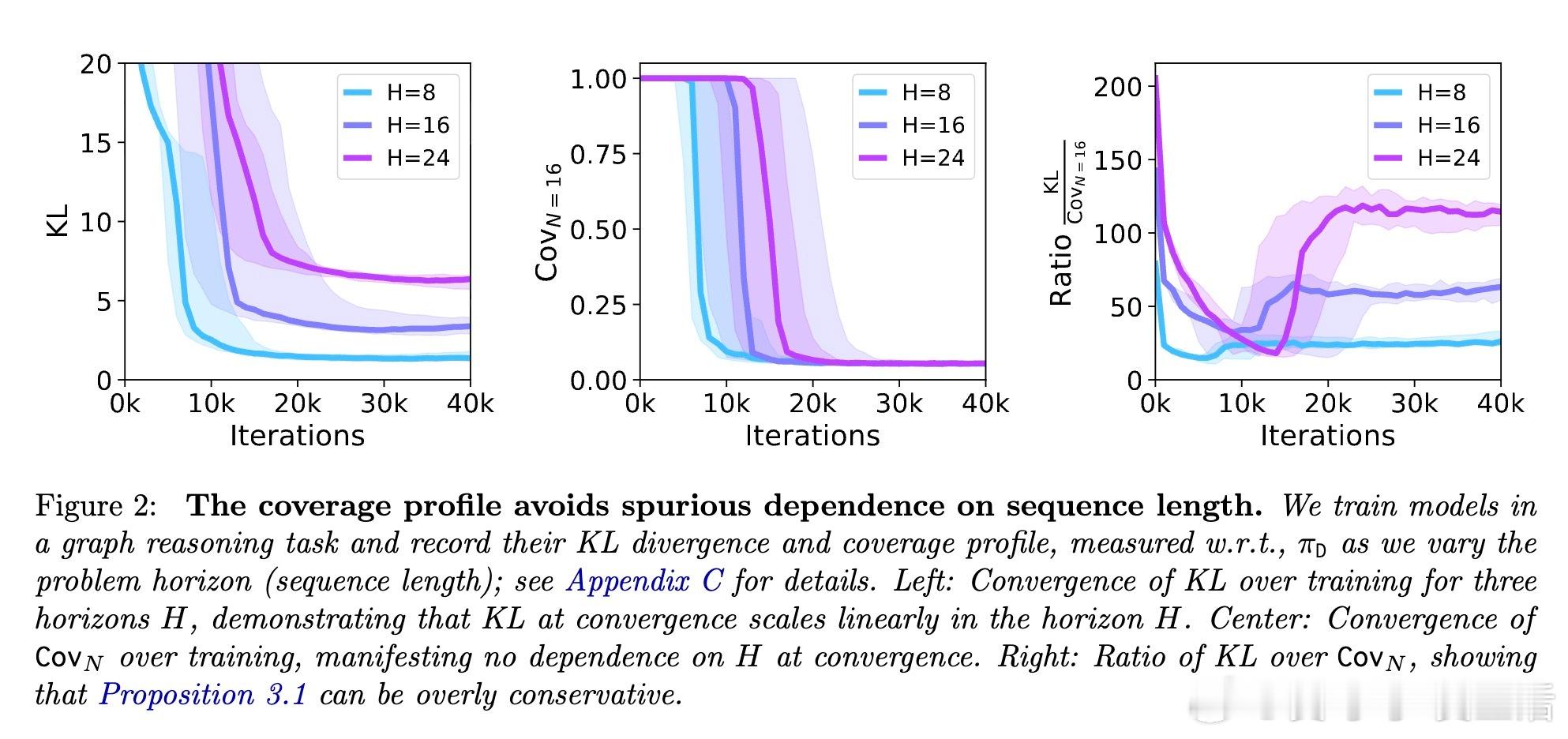
- 覆盖剖面对序列长度变化不敏感,验证了理论上的覆盖原则。
未来方向:基于覆盖原理设计更优预训练目标和训练流程,发展更语义化的覆盖指标,以及深入研究覆盖与强化学习成功的内在机制。
全文链接:arxiv.org/abs/2510.15020
——预训练不只是降低交叉熵,更关键的是保障模型对关键答案的“覆盖”,这是后期训练成功的根基。覆盖原理为理解和改进大规模语言模型训练提供了全新理论支撑。欢迎大家深入阅读与探讨!