[CV]《VISTA: A Test-Time Self-Improving Video Generation Agent》D X Long, X Wan, H Nakhost, C Lee... [Google] (2025)
VISTA:一种测试时自我提升的视频生成智能体
近年来,文本到视频(T2V)生成技术迅猛发展,但生成视频的质量高度依赖于用户输入提示的精准度,且视频的多维复杂性使得现有测试时优化方法难以有效提升质量。针对这一挑战,VISTA(Video Iterative Self-improvement Agent)提出了一种创新的多智能体协作框架,能够在测试时通过迭代优化提示,自动提升视频生成的视觉、音频和语境质量,实现更好地满足用户意图。
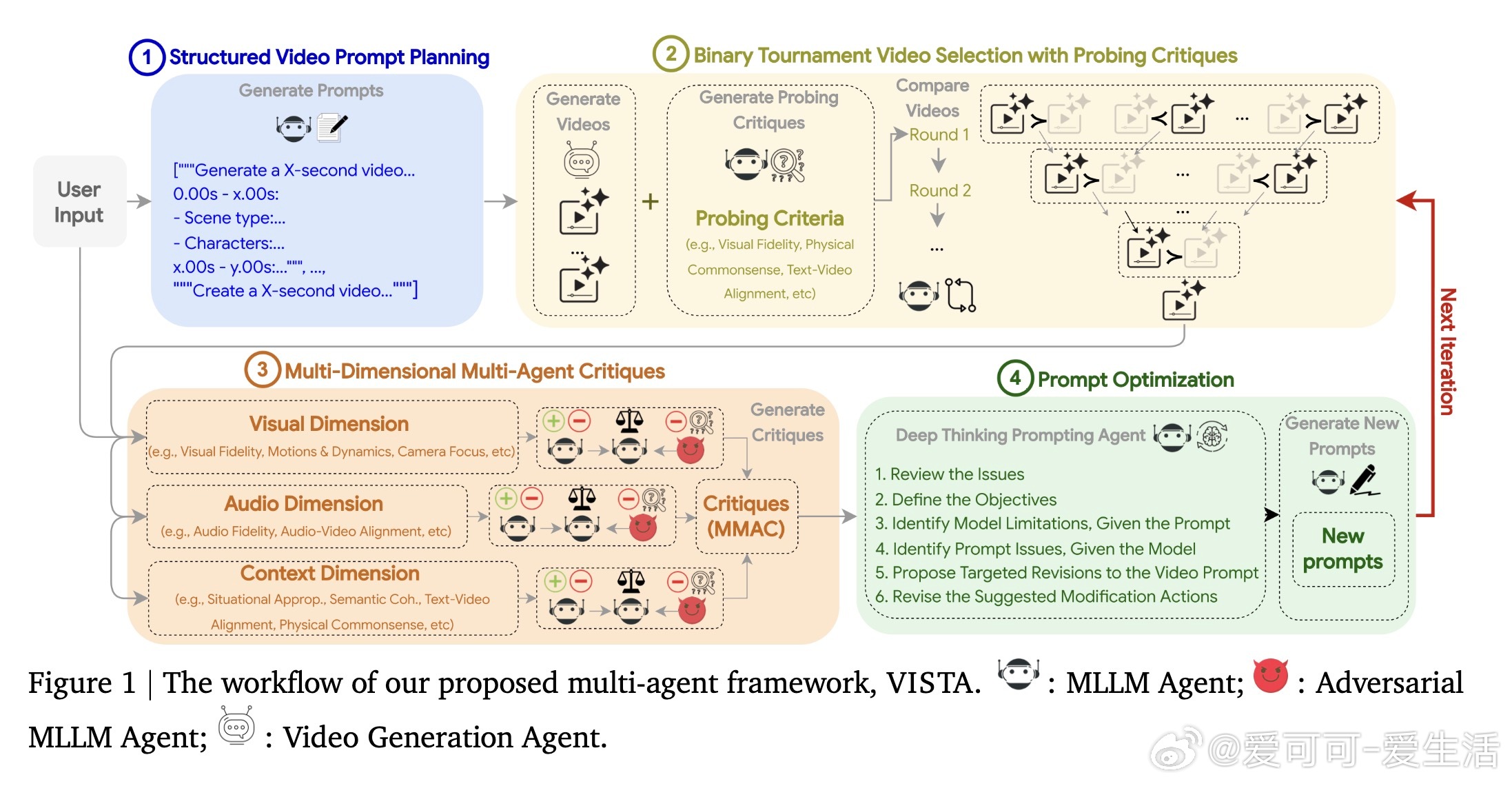
VISTA的核心流程包括两大阶段:
1. 初始化阶段
- 结构化视频提示规划:将用户的文本提示分解为时间序列的多场景描述,每个场景细分成持续时间、场景类型、角色、动作、对话、视觉环境、摄像机视角、声音及氛围等九大属性,支持多模态细粒度提示。
- 二元锦标赛式视频选择:基于多维评价标准(视觉真实感、物理常识、文本-视频对齐、音频-视频对齐、观赏性等),通过多轮成对比较和模型生成的探查性批评,选出最优视频-提示对。
2. 自我提升阶段
- 多维多智能体批评系统(MMAC):由视觉、音频和语境三个专门评审智能体组成,每个维度由一组正常评审、对抗评审和元评审联合产生细致且有深度的批评与评分,灵感来源于陪审团决策机制,能够发现常规评估忽略的细节问题。
- 深度思考提示优化代理(DTPA):结合批评反馈,通过结构化推理识别视频问题根源,明确成功标准,诊断提示中的模糊或冲突信息,提出针对性修改建议,并生成改进后的提示。
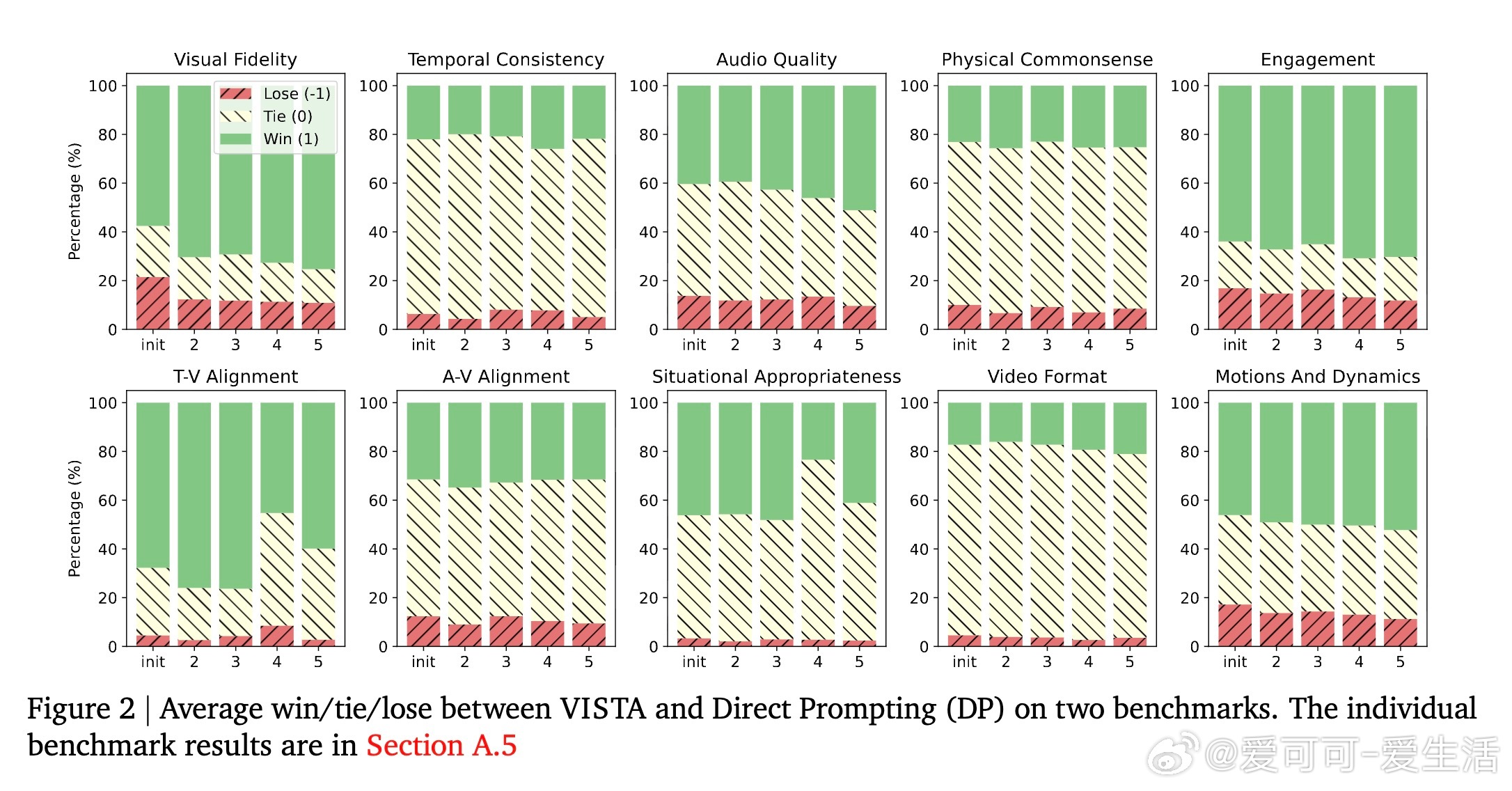
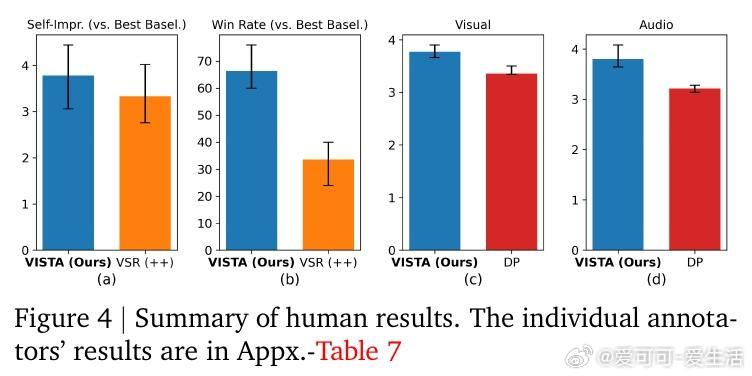
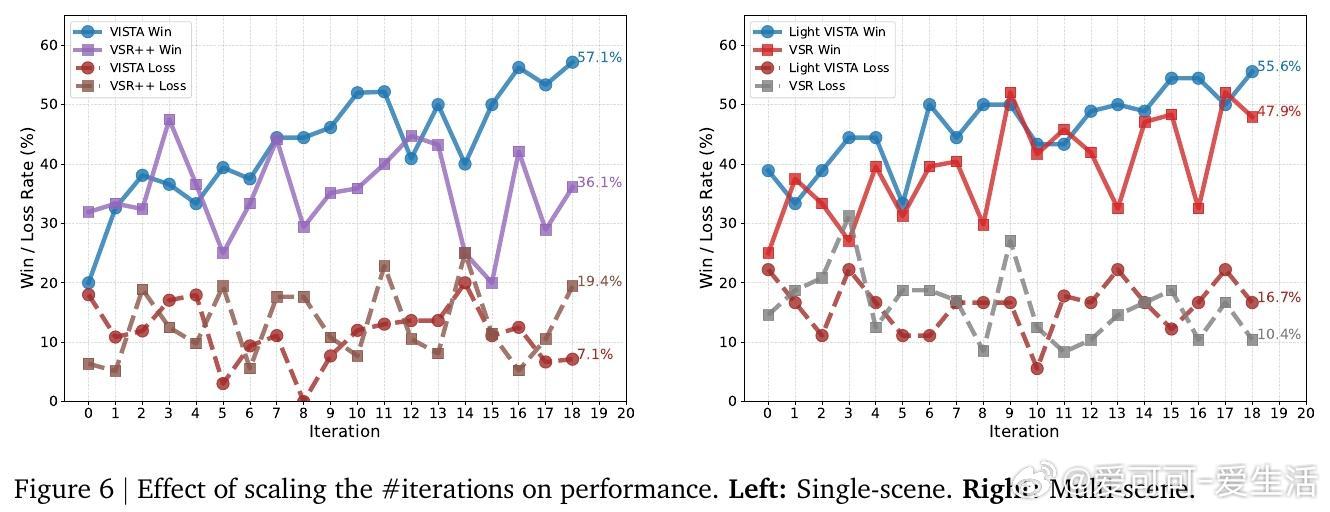
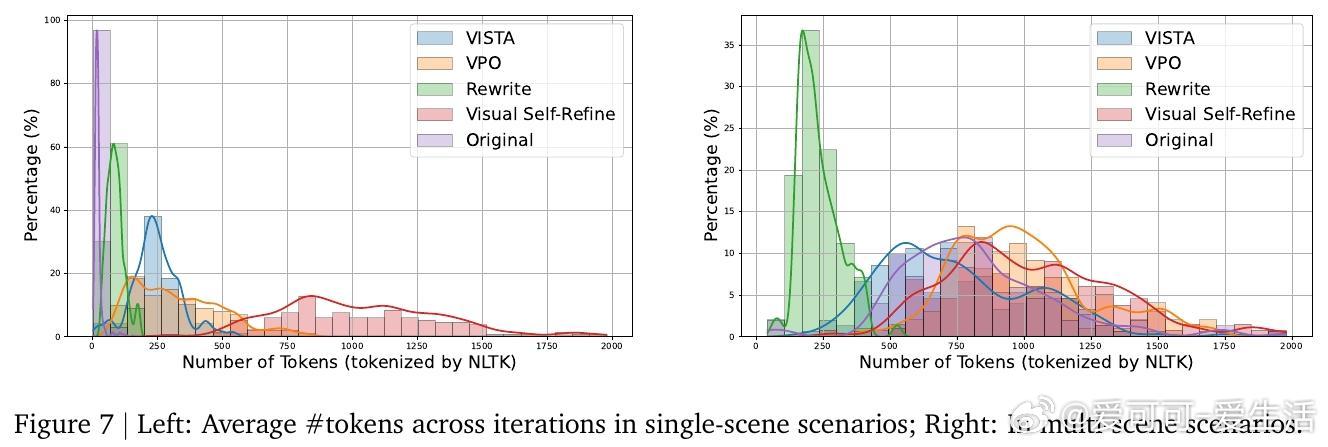
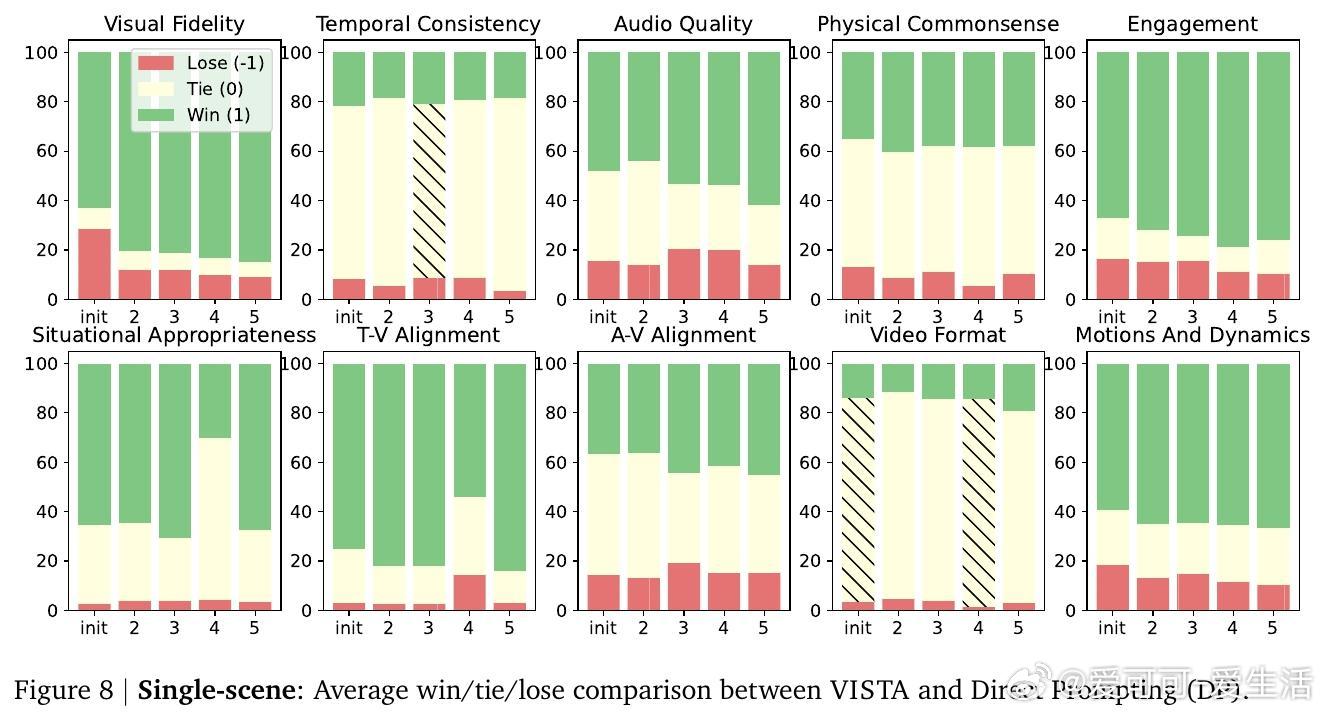
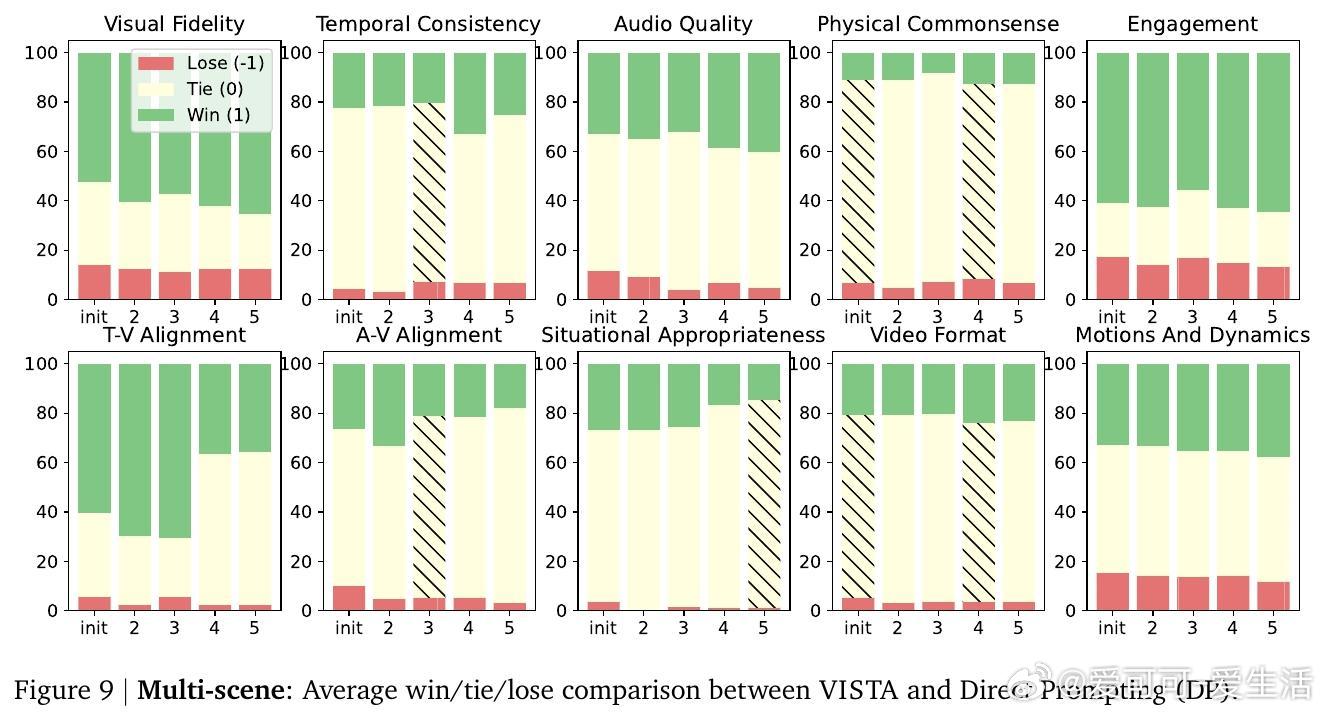
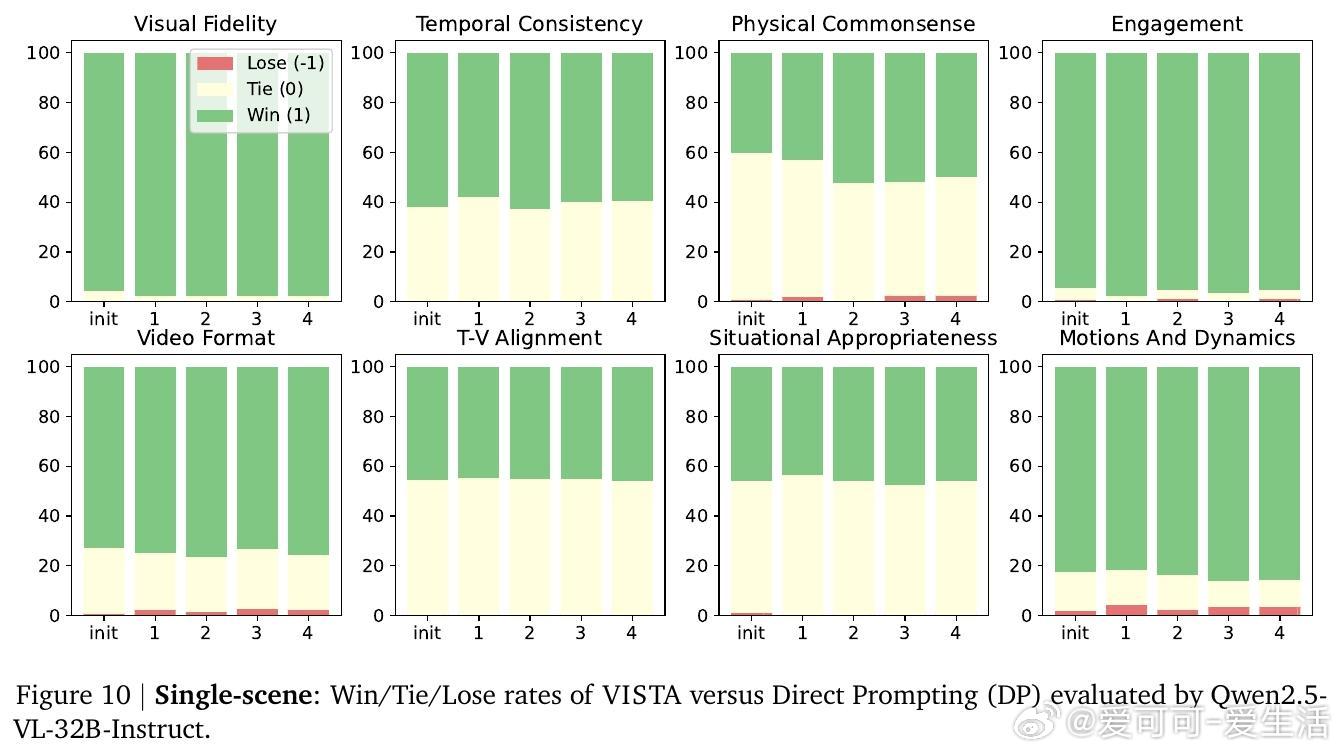
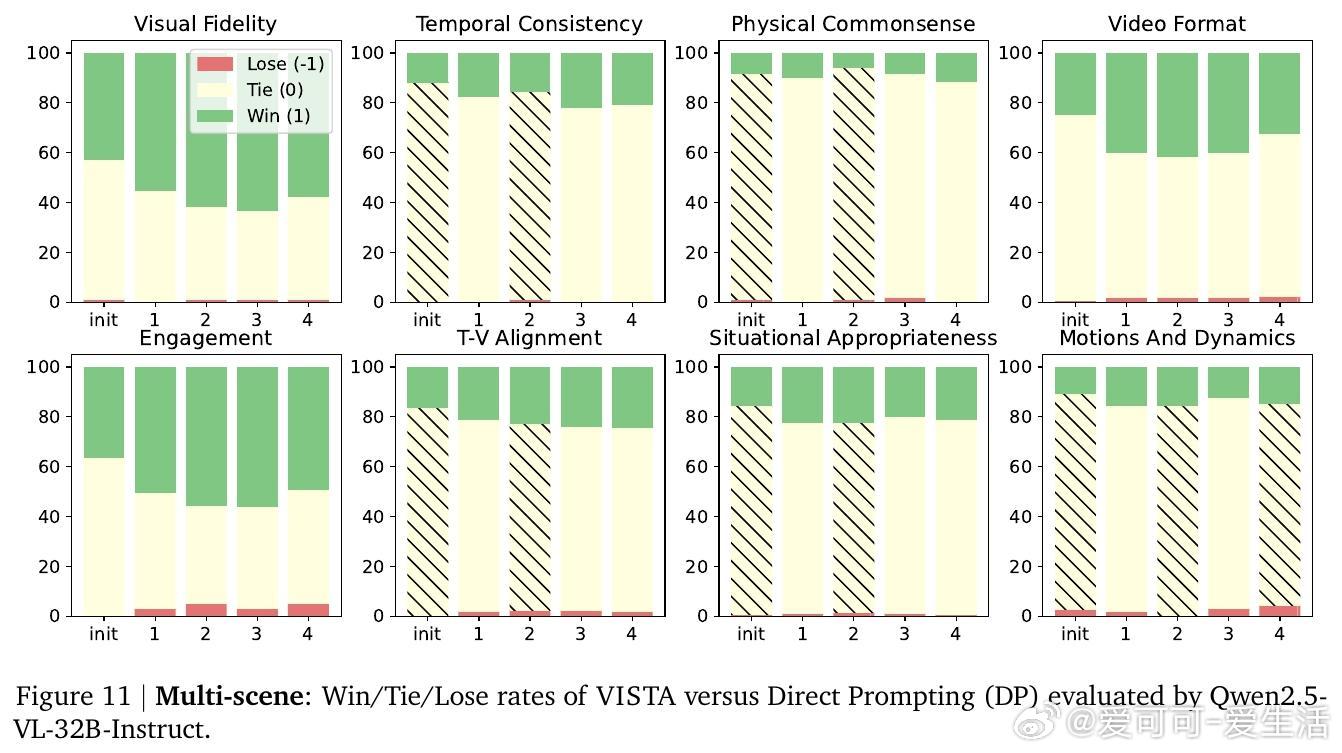
实验结果显示,VISTA在单场景和多场景视频生成任务中,均显著优于当前最先进基线方法,最高达60%成对胜率,且人类评审更偏好VISTA生成的视频,胜率达66.4%。细粒度指标涵盖视觉清晰度、运动自然性、文本对齐度及音频质量等多方面,均有明显提升。消融研究验证了各模块(提示规划、锦标赛选择、双评审机制、深度提示优化)对整体性能的重要贡献。
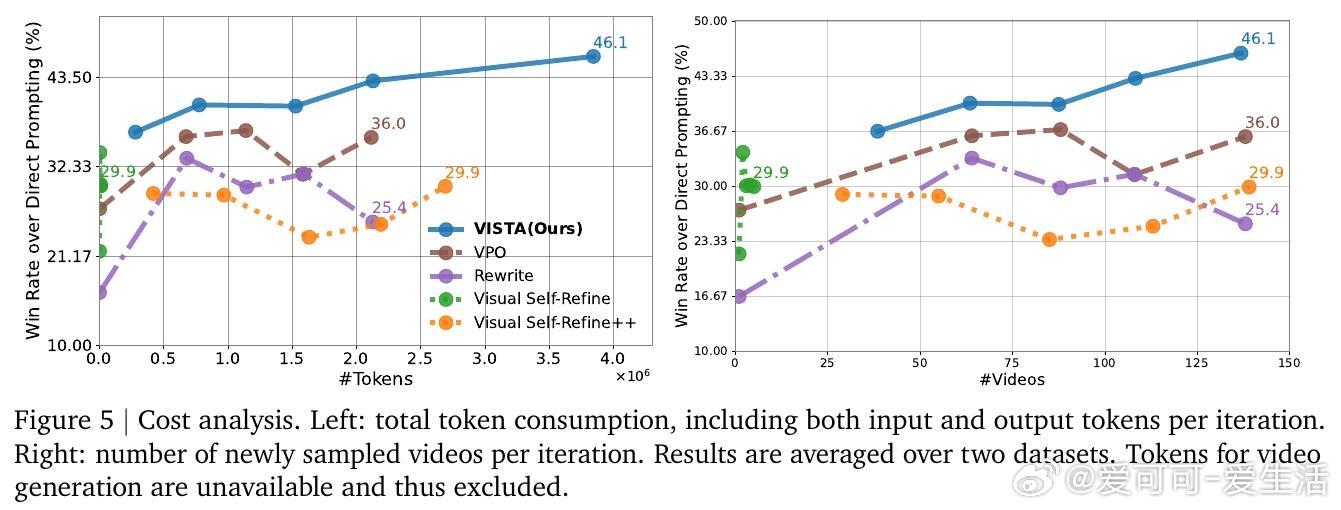
此外,VISTA具备良好的扩展性,可支持更多迭代优化,且对性能稍弱的生成模型同样有效。用户亦可自定义评价指标及约束,实现符合个性化需求的视频生成。此框架为实现更智能、交互性强且高度贴合用户意图的视频生成系统奠定了基础。
总结而言,VISTA创新性地将多智能体评审与结构化提示优化结合,通过模拟人类评判与反思机制,实现了测试时自动提升视频生成质量的突破,对推动文本驱动视频合成技术的实用化和普及具有重要意义。
更多详情及示例请见论文:
VISTA 视频生成 多智能体 测试时优化 文本到视频 AI创作 多模态



![卖掉165万的卡宴换ES8?看到他的APP,才发现是自己格局小了[滑稽笑][思](http://image.uczzd.cn/2685988792395524589.jpg?id=0)





