DeepSeek新模型被硅谷夸疯DeepSeek颠覆长文本处理方式
DeepSeek放大招:一个OCR模型,硅谷夸疯了。
项目刚上线,就已经斩获3.7K GitHub star,HuggingFace热榜第二,X平台好评刷屏,连卡帕西都说“图像比文字更适合LLM输入”。
别看它只有3B参数,用的却是文字压缩的独特思路——让语言模型看图识字,把文字“压缩”进图像里处理。
说白了就是,大模型处理长文本会特别耗算力,如果换个方式,把文字变成图像,用视觉模型处理,就能节省大量token,降低计算开销。
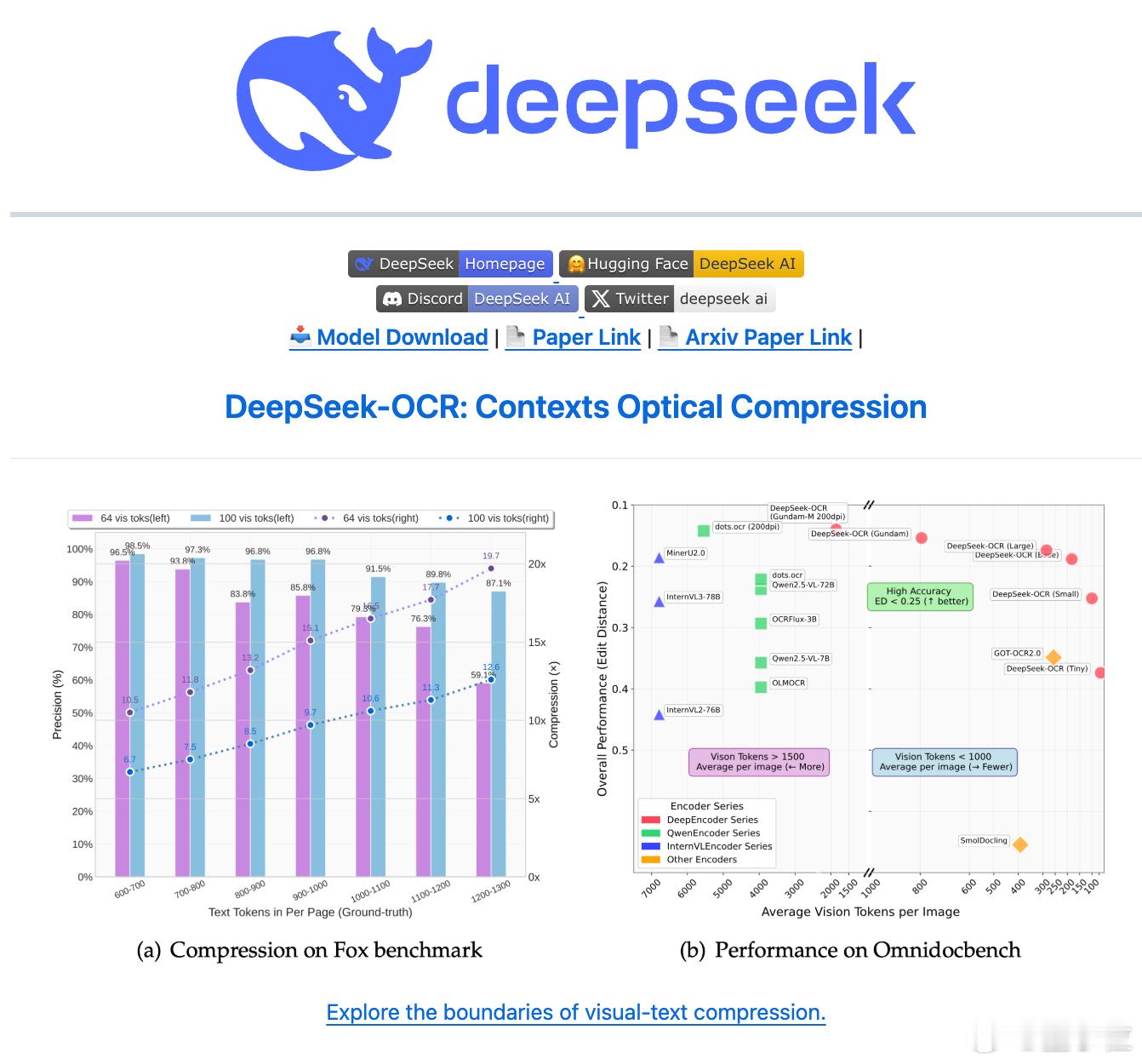
比如一篇1000字的文章,传统模型可能需要1000个token,但用DeepSeek这套方法,压缩成图片后只需100个视觉token,还原时准确率能达到97%。
背后的核心思想是“上下文光学压缩”:
- 把文字画成图,图再压缩成高密度视觉token;
- 最后再用语言模型从这些token里“解码”出原文。
就像人类看一页书不是逐字逐句念,而是扫一眼大致理解。DeepSeek做的事也是这个思路。
关键是,这种方法极其高效,单卡(A100-40G)每天能生成20万页训练数据。
他们还顺带提出了一个新脑洞:用视觉压缩来模拟人类记忆的“遗忘机制”。
- 近期内容就像眼前的东西,清晰、需要精细处理;
- 远期内容就像模糊的背景,只需要简单留个印象;
- 所以可以用不同分辨率的图像来保存不同“时期”的信息,实现有选择的记忆衰减。
这个设想对AI处理超长上下文非常关键。之前大模型“记不住几页纸”的问题,很可能在这被撬开突破口。
很多人都惊了,有网友直接说:这是“AI的JPEG时刻”。
甚至有人猜,这思路和谷歌Gemini的核心结构非常接近,像是把谷歌机密直接开源了。
这次DeepSeek不止是提出新方法,更像是打开了一个全新的AI认知路径。
目前这个模型已经开源,在GitHub和HuggingFace上热度都爆了。
传送门在此:
GitHub:github.com/deepseek-ai/DeepSeek-OCR
HF页面:huggingface.co/deepseek-ai/DeepSeek-OCR