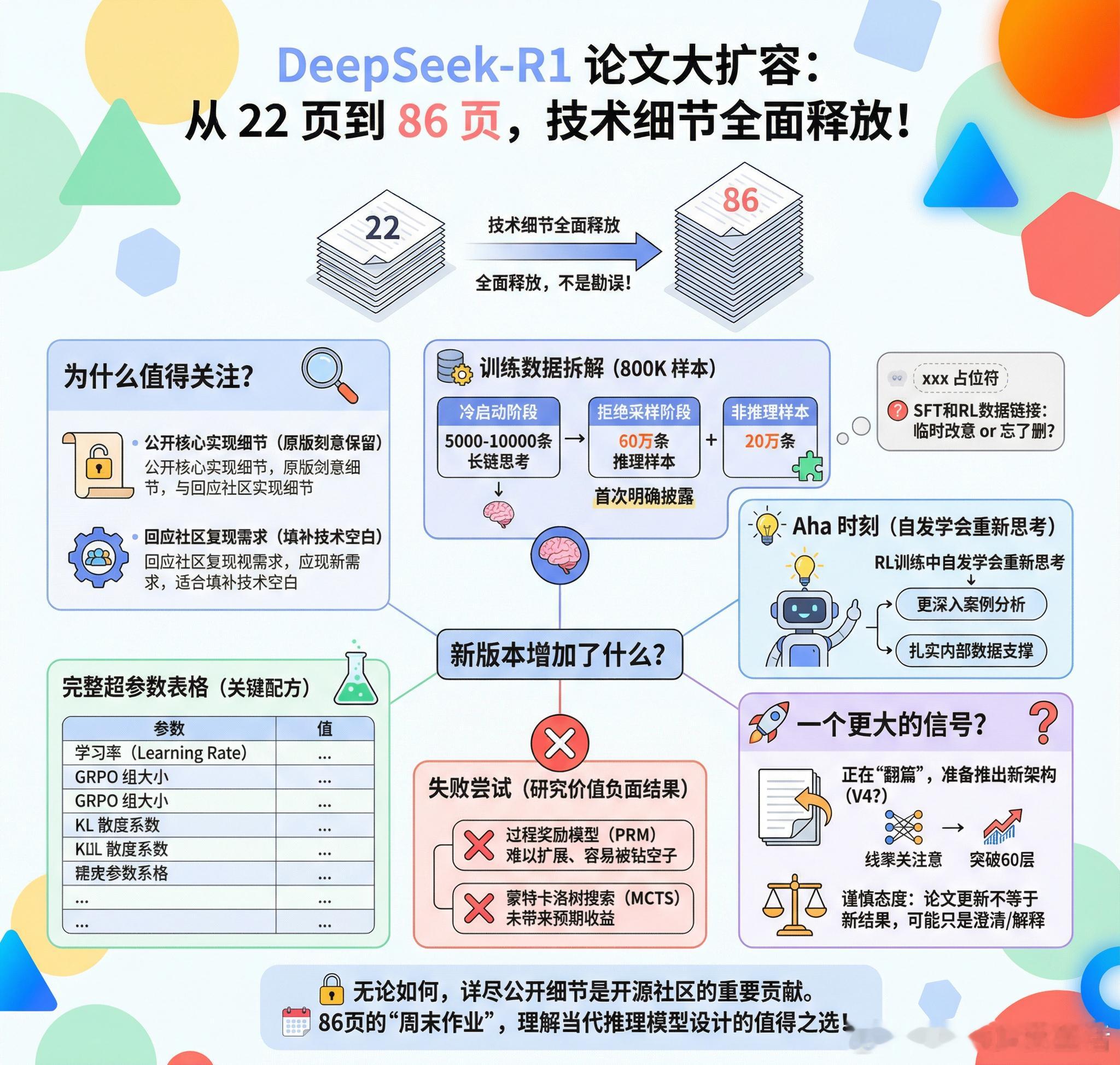
【DeepSeek-R1论文大扩容:从22页到86页,他们到底藏了什么?】DeepSeek-R1的论文悄悄更新了,篇幅从22页暴增至86页。这不是简单的勘误,而是一次技术细节的全面释放。+ 为什么值得关注?学术界的常规操作是论文发表后就画上句号,最多修个小错。但DeepSeek反其道而行之,补充了60多页的内容。这背后可能有两个原因:一是原版刻意保留了核心实现细节,现在觉得可以公开了;二是回应社区的复现需求,填补技术空白。无论哪种,对于想要复现或改进R1的研究者来说都是好消息。+ 新版本增加了什么?社区讨论指向几个关键扩展:训练数据方面出现了一个有趣的细节——论文末尾似乎有人留下了xxx占位符,原本可能是要发布SFT和RL训练数据的链接。是临时改了主意,还是单纯忘了删?800K训练样本的构成被详细拆解:冷启动阶段的5000-10000条长链思考样本、拒绝采样阶段的60万条推理样本和20万条非推理样本,这些数字首次明确披露。“Aha时刻”——模型在RL训练中自发学会重新思考的关键转折点,获得了更深入的案例分析。这个现象最初只是一笔带过,现在有了扎实的内部数据支撑。最珍贵的可能是“失败尝试”章节的扩展。过程奖励模型(PRM)为什么难以扩展、容易被模型钻空子?蒙特卡洛树搜索(MCTS)为什么没能带来预期收益?这些负面结果往往比成功经验更有研究价值。完整的超参数表格终于出现:学习率、GRPO组大小、KL散度系数,复现所需的关键配方。+ 一个更大的信号?有人猜测这次大规模文档化意味着DeepSeek正在“翻篇”,准备推出新架构。结合他们近期在线性注意力方面的研究进展,以及突破60层训练限制的新论文,V4可能会是一次架构层面的重大革新。当然也有人持谨慎态度:论文更新不等于新结果,这些可能只是澄清和解释。无论如何,一家公司愿意如此详尽地公开技术细节,本身就是对开源社区的重要贡献。86页的篇幅确实需要一个周末来消化,但对于想要理解当代推理模型设计的人来说,这份周末作业相当值得。reddit.com/r/LocalLLaMA/comments/1q6c9wc/deepseekr1s_paper_was_updated_2_days_ago