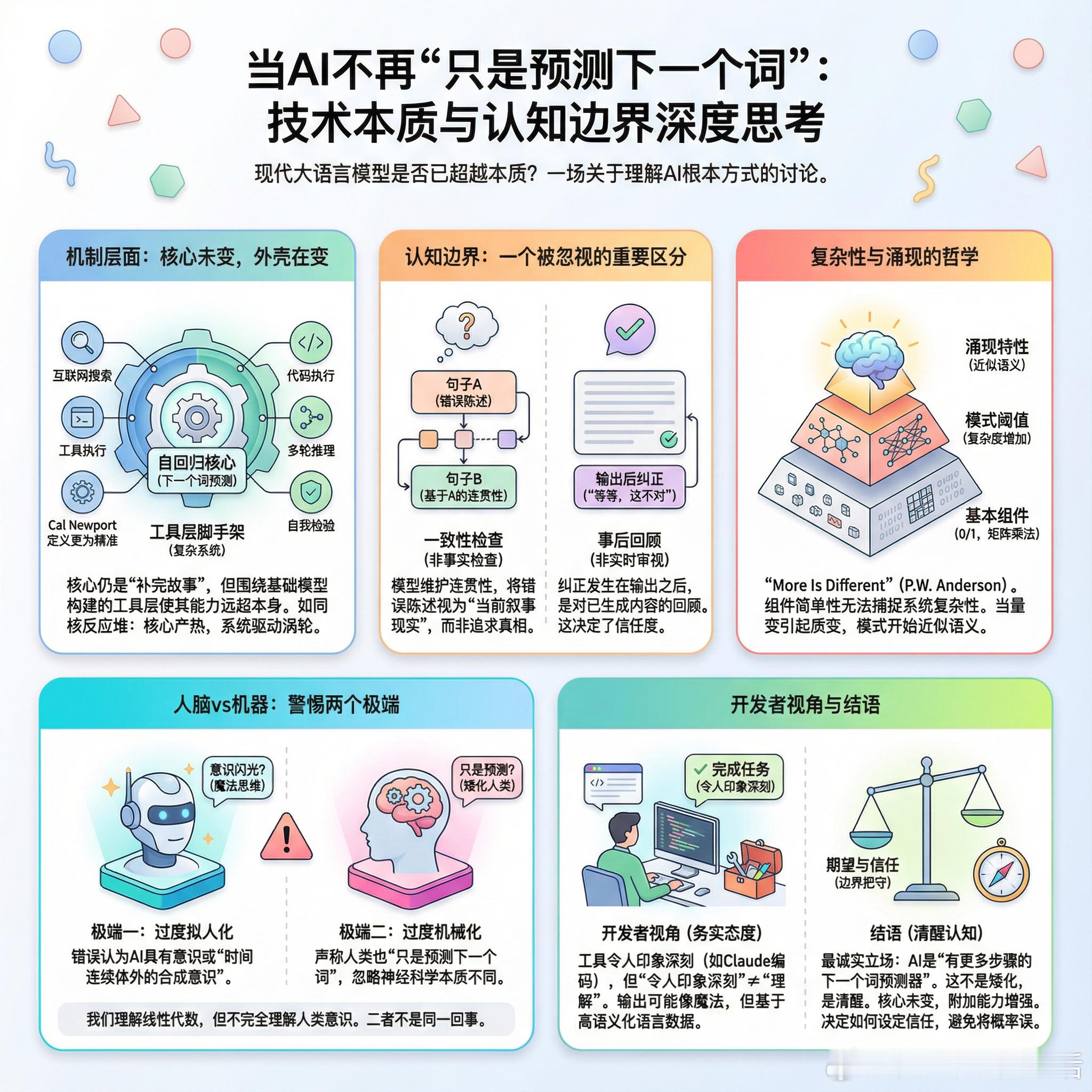
【当AI不再“只是预测下一个词”:技术本质与认知边界的深度思考】最近一篇关于AI能力边界的文章引发了广泛讨论,核心问题是:现代大语言模型是否已经超越了“预测下一个词”的本质?这场争论触及了我们理解AI的根本方式。+ 机制层面:核心未变,外壳在变从技术机制上看,LLM确实仍在做“下一个词预测”——这是自回归模型的本质。但这个表述容易产生误导。正如一位开发者所言,Cal Newport的定义更为精准:它们是在“补完你提供的故事”。关键在于“只是”二字。现代AI系统围绕基础模型构建了复杂的脚手架:互联网搜索、代码执行、多轮推理、自我检验。这些工具层使系统能力远超基础模型本身。就像核反应堆的核心机制只是“产生热量驱动蒸汽涡轮”,但这个简单描述显然无法涵盖整个系统的复杂性。+ 一个被忽视的重要区分值得注意的是,这些系统进行的是“一致性检查”而非“事实检查”。如果模型在句子A中产生错误陈述,它会将此视为“当前叙事的现实”,以此为基础生成句子B——它在维护连贯性,而非追求真相。这不意味着模型永远不会自我纠正。实际使用中,模型确实会说“等等,这不对”。但这种纠正发生在输出之后,是对已生成内容的回顾,而非生成过程中的实时审视。这个区别决定了我们应该对这些系统投入多少信任。+ 复杂性与涌现的哲学有一个有趣的观察:人们总是通过聚焦于最小组件来矮化复杂系统。计算机“只是”零和一,机器学习“只是”矩阵乘法,爱情“只是”化学反应。这种表述技术上正确,但忽略了涌现特性——当模式复杂度达到某个阈值,它们开始近似语义本身。物理学家P.W. Anderson在1970年代写过一篇关于涌现的经典论文《More Is Different》,凝聚态物理处理的正是由基本构件组成但表现出独立行为的准粒子。组件的简单性无法捕捉系统的复杂性。+ 人脑vs机器:警惕两个极端讨论中出现了两种令人担忧的倾向。一种是将AI过度拟人化,认为它们具有意识甚至“时间连续体之外的合成意识闪光”。另一种是将人脑过度机械化,声称人类也“只是预测下一个词”。两者都忽略了关键区别。人脑与LLM的预测机制在神经科学上有本质不同。我们不完全理解人类意识,但我们确实理解线性代数——它们不是同一回事。一位评论者敏锐地指出:对于许多人来说,迫切需要将意识和大脑简单化,可能是为了缓解关于“困难问题”的存在性恐惧。+ 开发者视角:既不神化也不矮化作为实际使用者,开发者群体的态度更为务实。这些工具确实令人印象深刻——当你给Claude一个编码任务,它不仅理解需求,还会添加你没想到的便利功能。但“令人印象深刻”和“理解”是两回事。对于非编码人员来说,这些输出可能看起来像魔法。但正如克拉克所言,“任何足够先进的技术都与魔法无异”。考虑到投入的成本和数据规模,模型能做到这些完全合理——毕竟代码本身就是高度语义化和结构化的语言。+ 结语也许最诚实的立场是:现代AI是“有更多步骤的下一个词预测器”。这不是矮化,而是清醒。核心机制未变,但附加能力使其表现远超基础模型。理解这一点很重要,因为它决定了我们如何设定期望、如何配置信任、如何避免将概率输出误认为确定性真相。技术在进步,但“魔法思维”与清醒认知之间的边界,仍需我们自己把守。reddit.com/r/artificial/comments/1q6hfyai_isnt_just_predicting_the_next_word_anymore