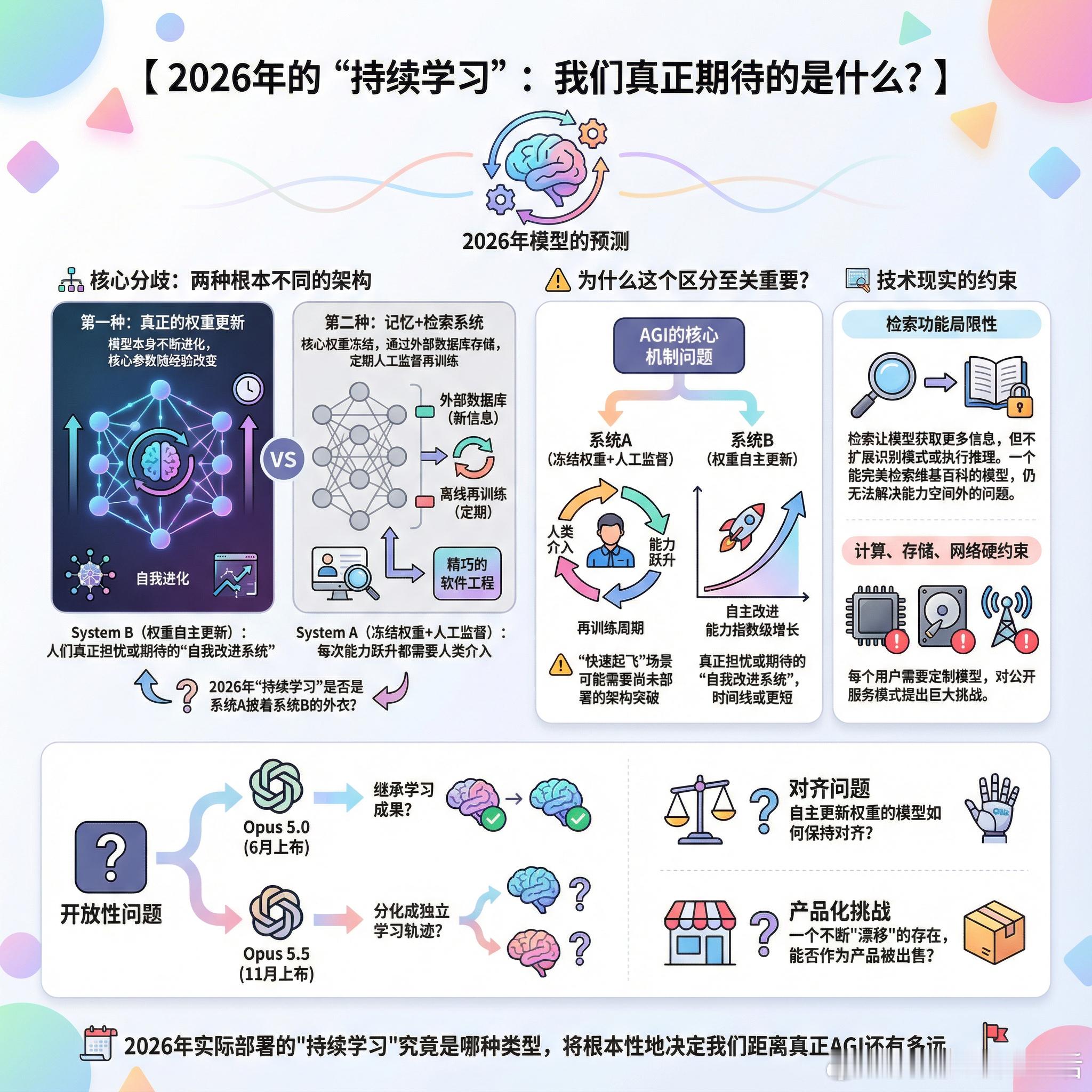
【2026年的“持续学习”:我们真正期待的是什么?】“持续学习”这个词在AI圈被频繁提及,尤其是关于2026年模型的预测。但这个看似简单的概念,实际上隐藏着截然不同的技术路径和深远影响。+ 核心分歧:两种根本不同的架构当我们谈论“持续学习”时,实际上在讨论两种完全不同的东西:第一种是真正的权重更新——模型的核心参数会随着使用和经验而改变,模型本身在不断进化。第二种是记忆+检索系统——核心权重保持冻结,通过外部数据库存储新信息,定期进行离线再训练。这本质上是更精巧的软件工程,而非真正的自我进化。+ 为什么这个区分至关重要?对于AGI而言,机制本身就是核心问题。考虑递归自我改进这个圣杯级能力:系统A(冻结权重+检索+人工监督的再训练周期)意味着每次能力跃升都需要人类介入。系统B(权重自主更新)才是人们真正担忧或期待的“自我改进系统”。如果2026年的“持续学习”主要是系统A披着系统B的外衣,那么自主自我改进的时间线可能比主流讨论认为的更长,“快速起飞”场景需要我们尚未部署的架构突破。+ 技术现实的约束检索让模型获取更多信息,但不扩展它能识别的模式或执行的推理。一个能完美检索整个维基百科的模型,仍然无法解决其能力空间之外的问题。只有真正的权重更新才有可能做到这一点。实践中,持续学习面临计算、存储和网络带宽的硬约束。每个用户需要自己的定制模型,这对公开服务模式提出巨大挑战。+ 开放性问题如果Opus 5.0在6月发布后持续学习,11月发布的5.5是否继承了这些学习成果?还是它们会分化成独立的学习轨迹?自主更新权重的模型如何保持对齐?一个不断“漂移”的存在,能否作为产品被出售?这些问题目前没有确定答案。但2026年实际部署的“持续学习”究竟是哪种类型,将根本性地决定我们距离真正AGI还有多远。x.com/singularity/comments/1q6attw/continual_learning_in_2026_what_does_continual