Kimi员工“黑”谈他们是如何优化推理性能的。还有提示玩小龙虾的朋友尽可能避免把 cronjob 设置在整点来避免高峰期响应能力下降。---------------------------Kimi K2.5 发布半个月以来,我们的推理服务接受了前所未有的挑战,为了应对持续增长的请求数,我们想尽办法从各种地方掠夺了 GPU 资源,同时也在尝试新的推理方案和调度策略。现在,我们已经能“稳稳接住”这泼天的富贵,从推理速度、到 API 稳定性、再到资源利用率都是前所未有地好,好上加好。
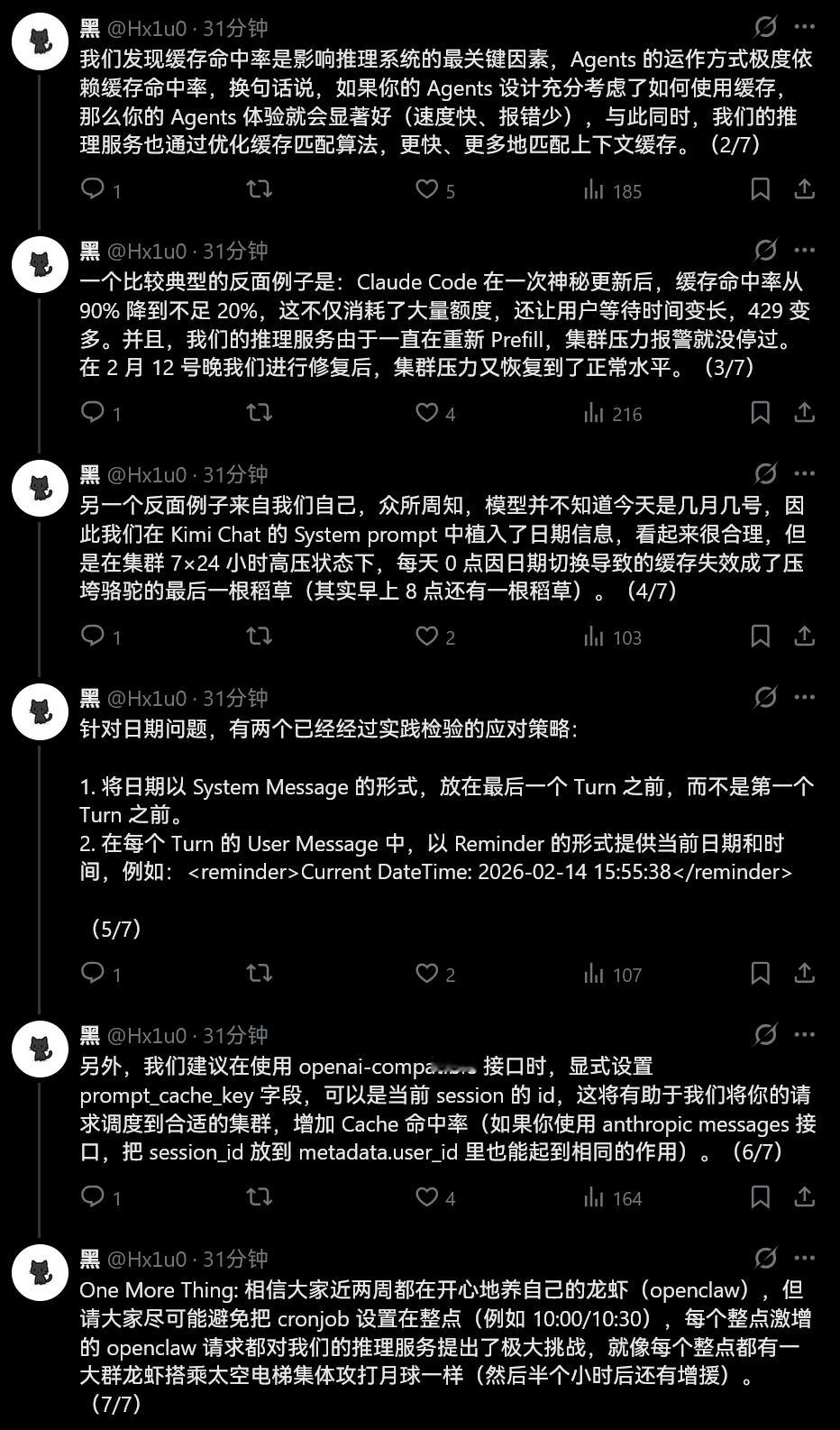
我们发现缓存命中率是影响推理系统的最关键因素,Agents 的运作方式极度依赖缓存命中率,换句话说,如果你的 Agents 设计充分考虑了如何使用缓存,那么你的 Agents 体验就会显著好(速度快、报错少),与此同时,我们的推理服务也通过优化缓存匹配算法,更快、更多地匹配上下文缓存。
一个比较典型的反面例子是:Claude Code 在一次神秘更新后,缓存命中率从 90% 降到不足 20%,这不仅消耗了大量额度,还让用户等待时间变长,429 变多。并且,我们的推理服务由于一直在重新 Prefill,集群压力报警就没停过。在 2 月 12 号晚我们进行修复后,集群压力又恢复到了正常水平。
另一个反面例子来自我们自己,众所周知,模型并不知道今天是几月几号,因此我们在 Kimi Chat 的 System prompt 中植入了日期信息,看起来很合理,但是在集群 7×24 小时高压状态下,每天 0 点因日期切换导致的缓存失效成了压垮骆驼的最后一根稻草(其实早上 8 点还有一根稻草)。
针对日期问题,有两个已经经过实践检验的应对策略:1. 将日期以 System Message 的形式,放在最后一个 Turn 之前,而不是第一个 Turn 之前。2. 在每个 Turn 的 User Message 中,以 Reminder 的形式提供当前日期和时间,例如:Current DateTime: 2026-02-14 15:55:38
另外,我们建议在使用 openai-compatible 接口时,显式设置 prompt_cache_key 字段,可以是当前 session 的 id,这将有助于我们将你的请求调度到合适的集群,增加 Cache 命中率(如果你使用 anthropic messages 接口,把 session_id 放到 metadata.user_id 里也能起到相同的作用)。
One More Thing: 相信大家近两周都在开心地养自己的龙虾(openclaw),但请大家尽可能避免把 cronjob 设置在整点(例如 10:00/10:30),每个整点激增的 openclaw 请求都对我们的推理服务提出了极大挑战,就像每个整点都有一大群龙虾搭乘太空电梯集体攻打月球一样(然后半个小时后还有增援)。
HOW I AI