[LG]《The Era of Real-World Human Interaction: RL from User Conversations》C Jin, J Xu, B Liu, L Tao... [FAIR at Meta] (2025)
真正的“人机共学”时代已来:RLHI——从真实用户对话中强化学习,开启模型个性化与持续进化新篇章🌐
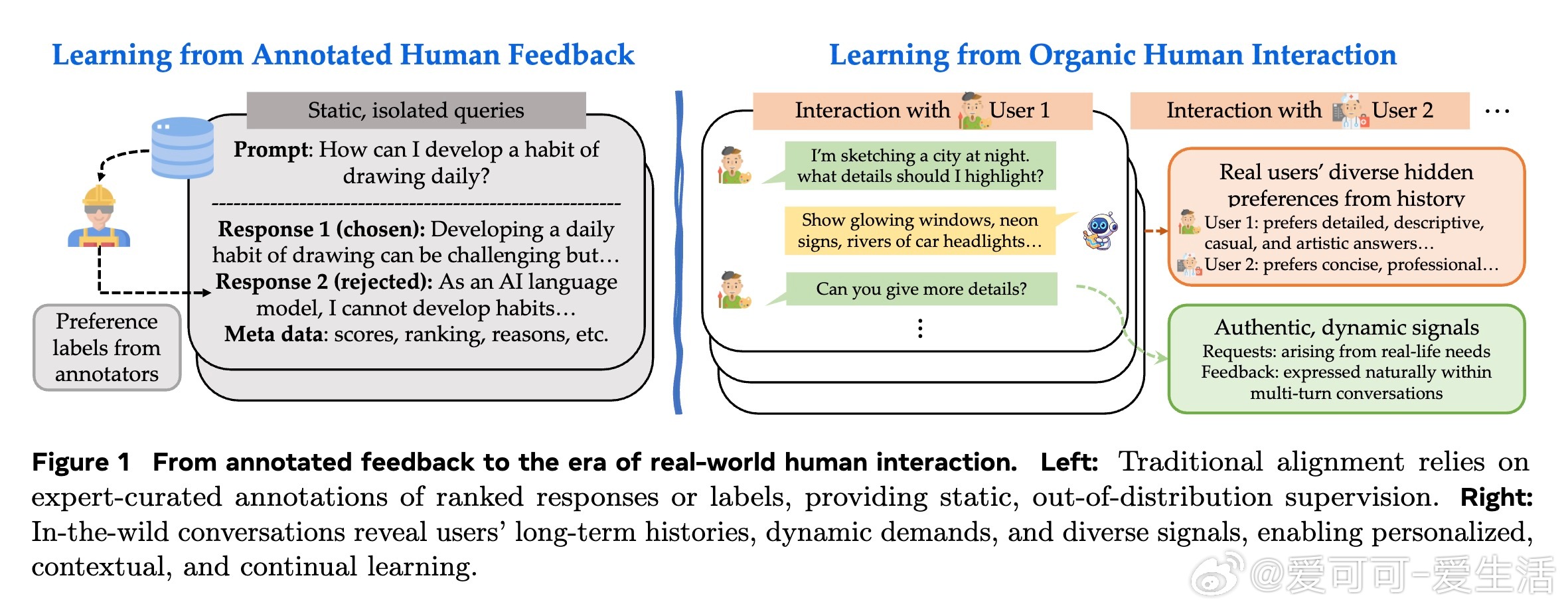
• 现有模型依赖专家标注反馈,难以捕捉用户真实、动态的长期需求;RLHI直接从野外用户对话中提取信号,利用自然语言反馈实现个性化调整。
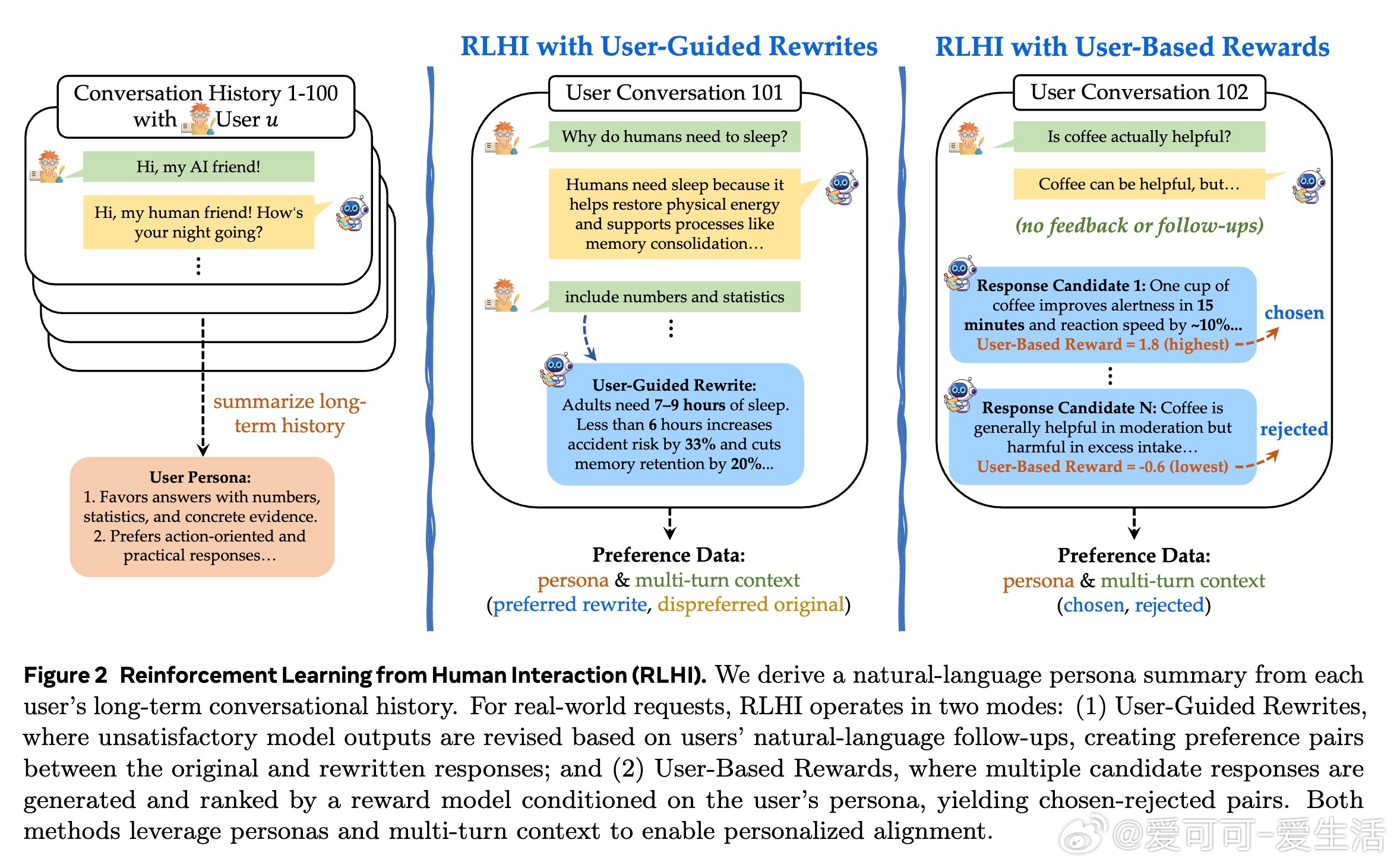
• 两大创新路径:1⃣ 用户引导改写——根据用户后续自然语言反馈修正模型输出,生成偏好对比对模型进行个性化训练;2⃣ 用户基于奖励——结合用户历史形成的 persona,利用奖励模型对多候选答案排序,实现长远偏好驱动的响应优化。
• 用户互动数据显示,26.5%为带反馈的重试请求,40.4%为新主题请求,真实反馈语义丰富且多样,较传统数据集显著提升上下文多样性(0.865 vs 0.751/0.848)。
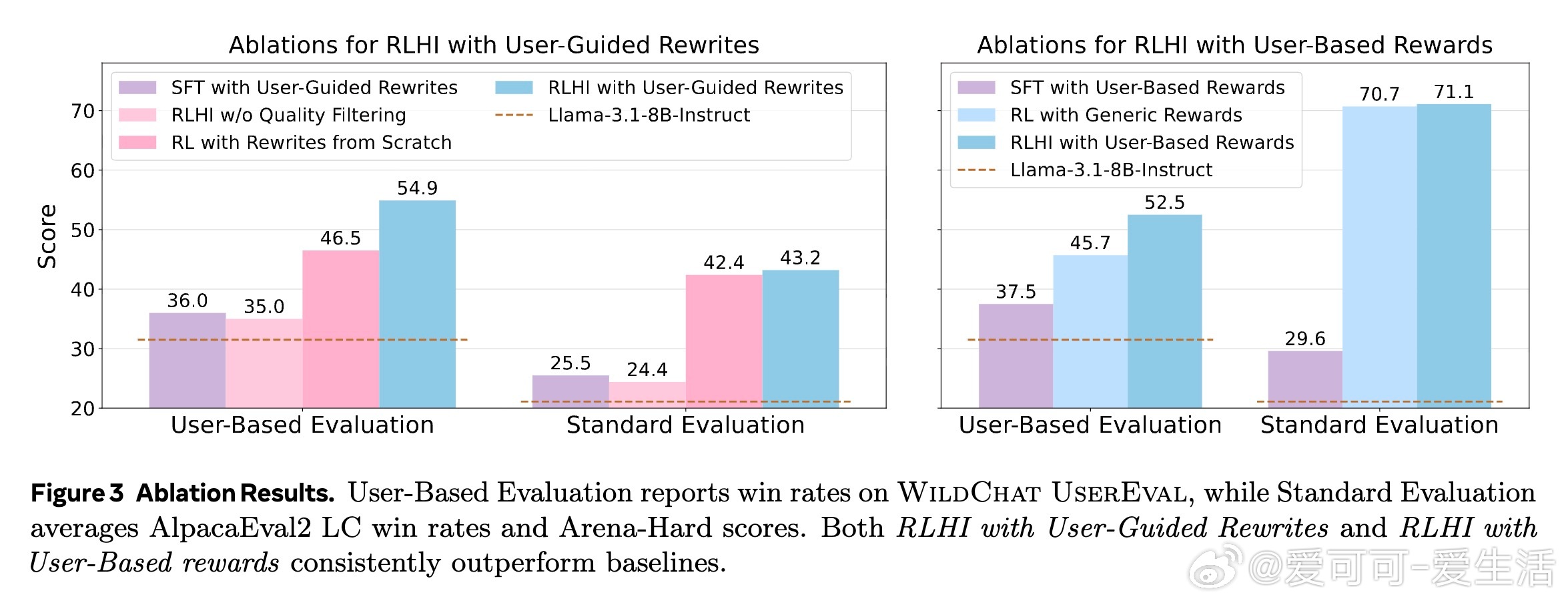
• RLHI在WildChat真实用户评测中,个性化提升高达24.3%,指令跟随提升14.1%,综合用户偏好提升22.4%;同时对数学及科学推理任务,用户引导改写提升准确率5.3个百分点。
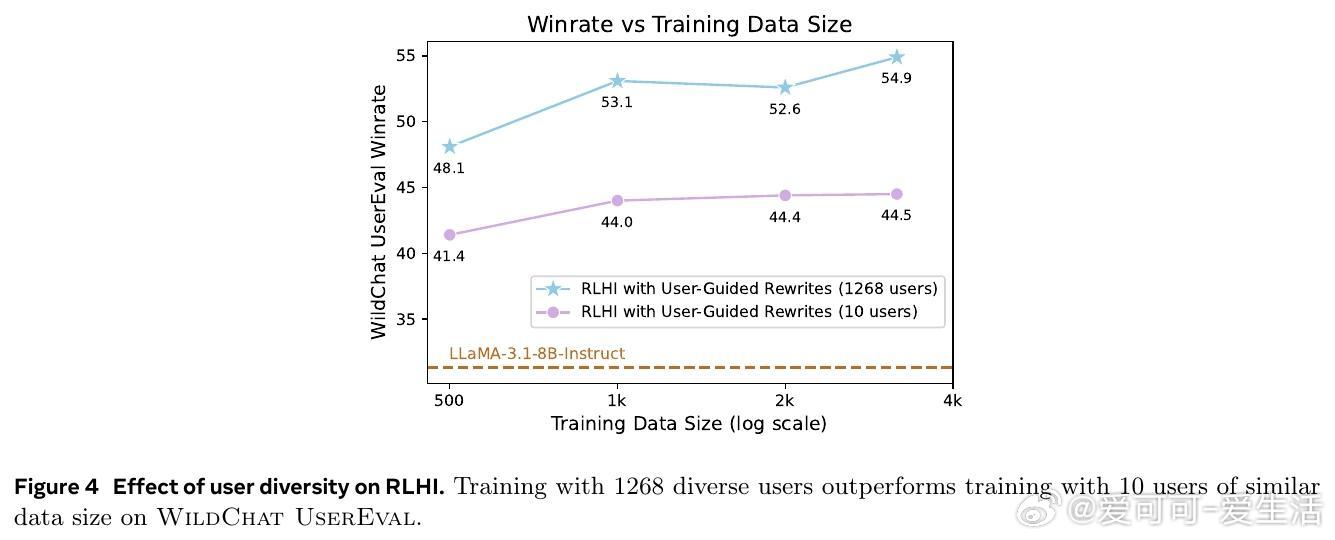
• 训练需严格过滤噪声,优质数据筛选是提升效果的关键,且多用户多样性训练远优于少数用户大量数据,强调广泛用户覆盖的必要性。
• RLHI优于传统监督微调,因强化学习能同时利用优劣示例区分反馈,捕捉细腻偏好,真正实现个性化对话系统的动态进化。
• 展望未来,RLHI将结合人类在线反馈、隐私保护及多模态输入,推动模型从静态数据时代迈向持续体验学习,塑造真正懂你、会进步的智能助手。
心得:
1. 真实的人机对话远比静态标注更能反映用户复杂且动态的需求,模型必需学会从多样且语义丰富的交互中持续自我优化。
2. 将用户长期历史抽象成persona,并结合即时反馈进行多层次偏好优化,是实现个性化和上下文敏感响应的关键。
3. 多样性训练远胜于单一用户深度训练,强调模型适应广泛用户群体的能力,才能真正具备普适价值和个性化兼顾的能力。
了解详情🔗arxiv.org/abs/2509.25137
人工智能强化学习人机交互个性化模型自然语言处理持续学习