[LG]《Short window attention enables long-term memorization》L Cabannes, M Beck, G Szilvasy, M Douze... [Ecole Normale Supérieure Paris Saclay & Johannes Kepler University Linz & Meta FAIR] (2025)
短窗口注意力如何助力模型实现长时记忆的突破
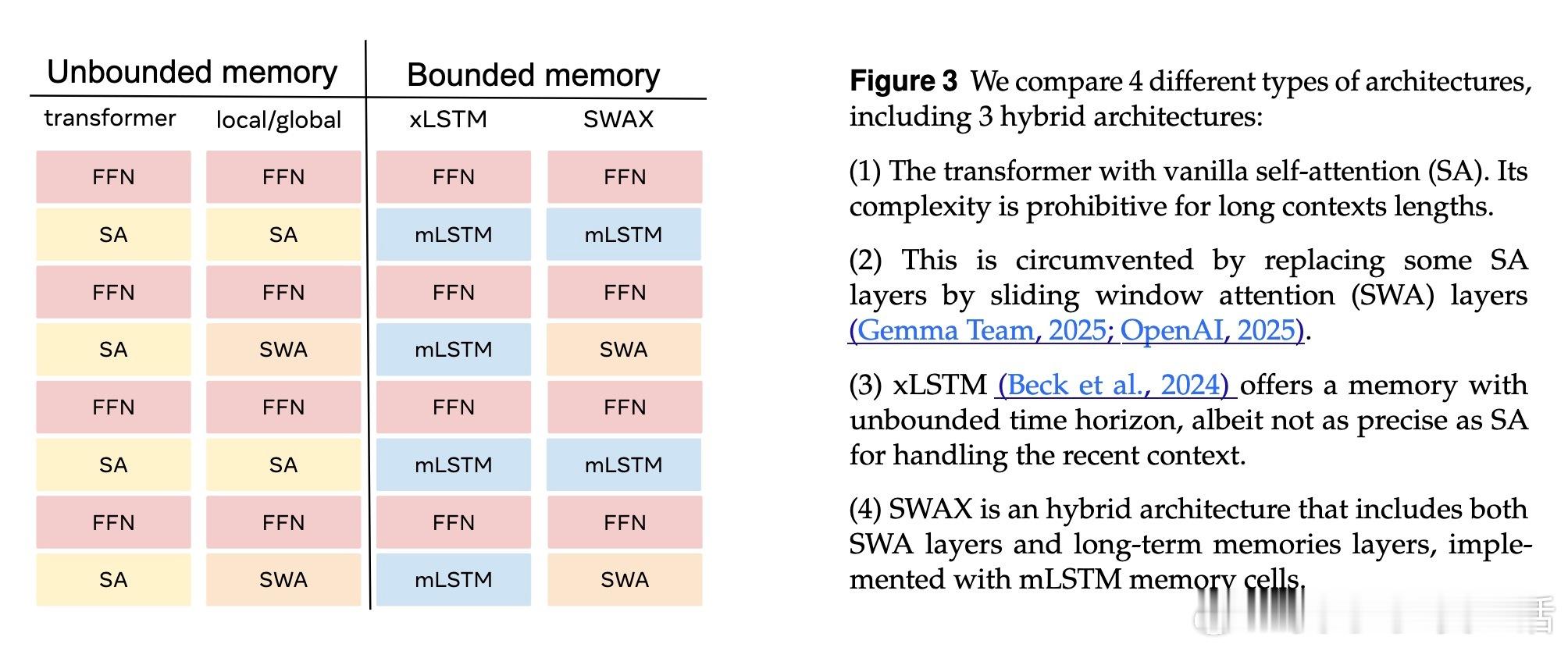
• SWAX架构创新地结合了滑动窗口软最大注意力(SWA)与xLSTM线性RNN层,固定状态大小确保计算成本稳定。
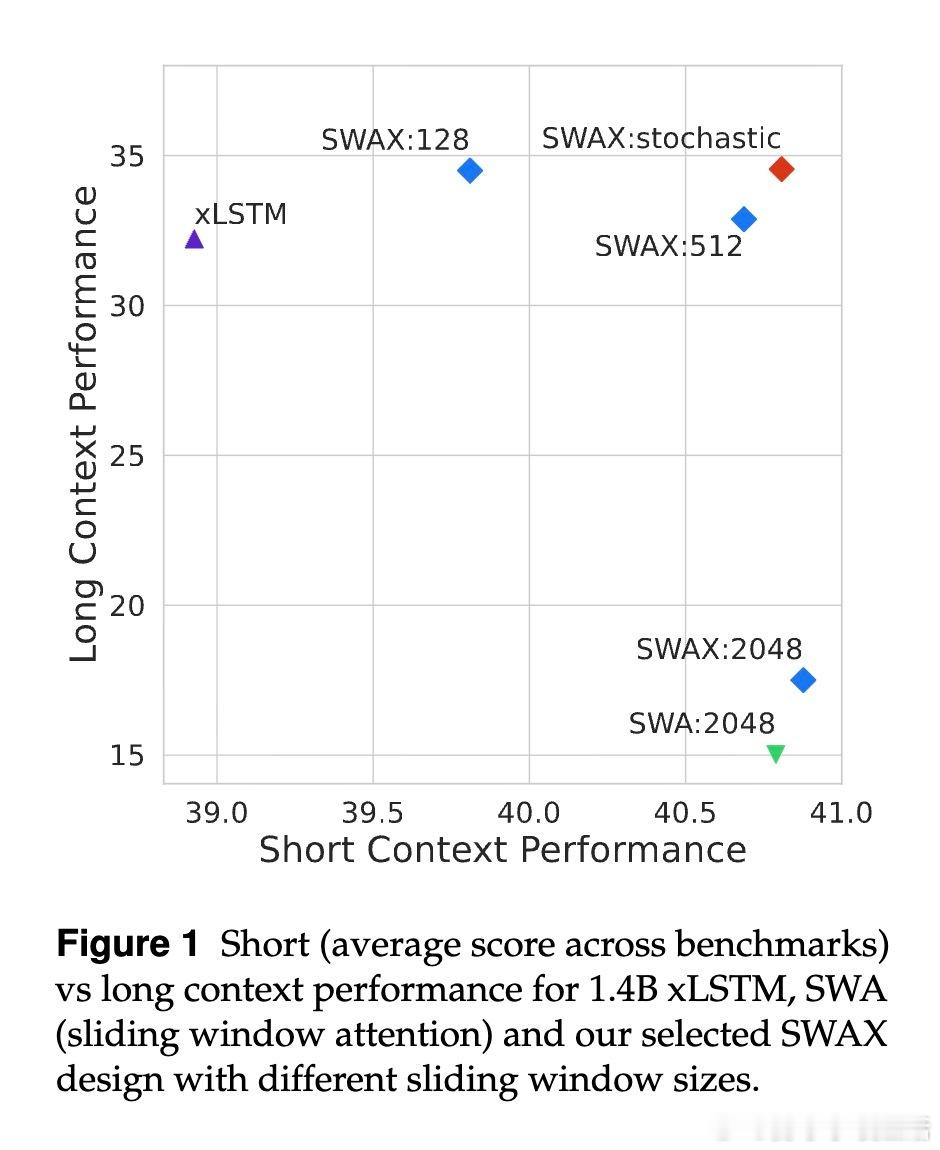
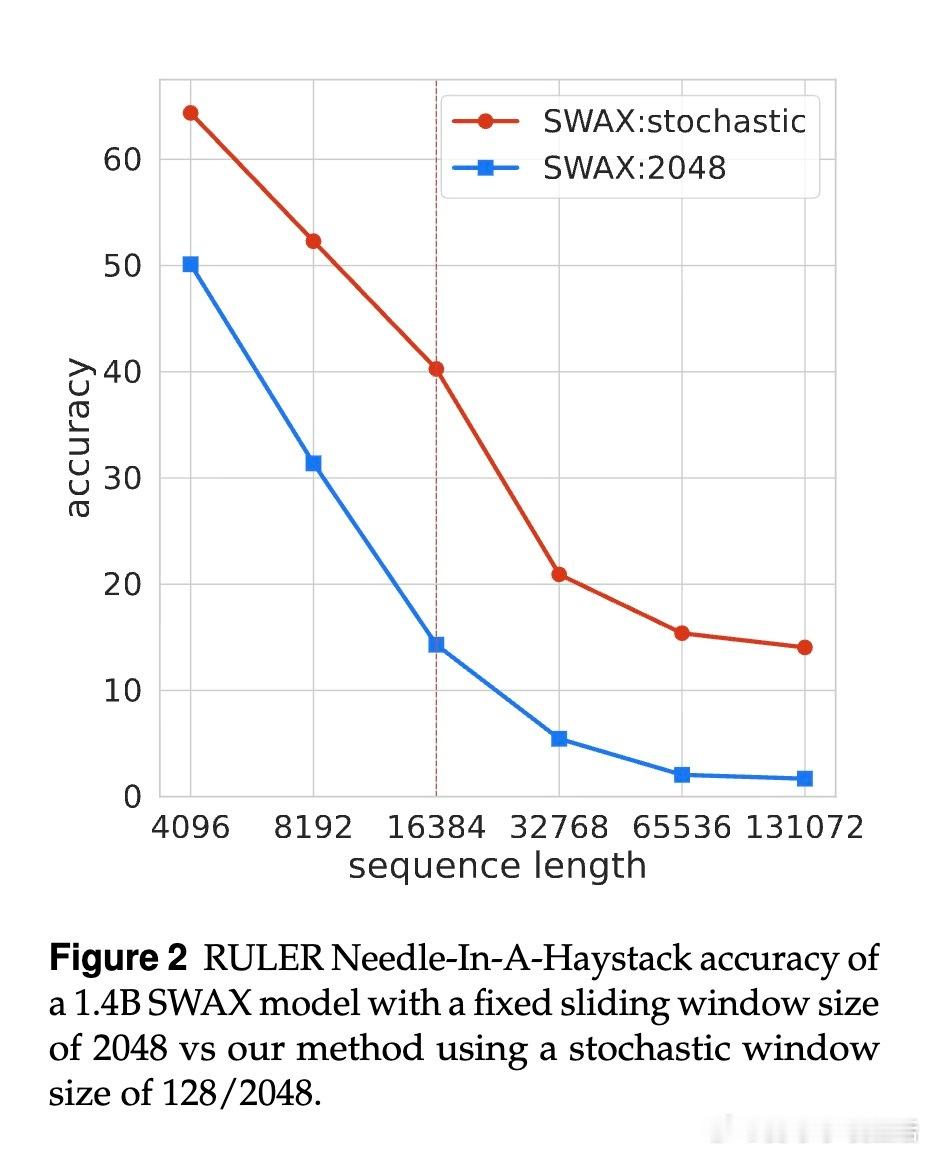
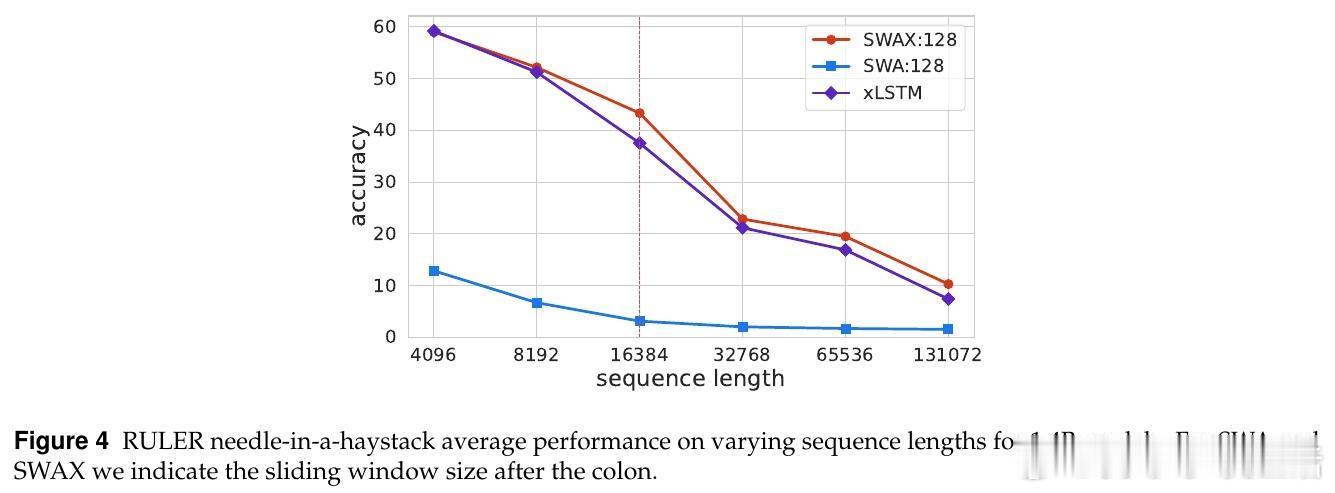
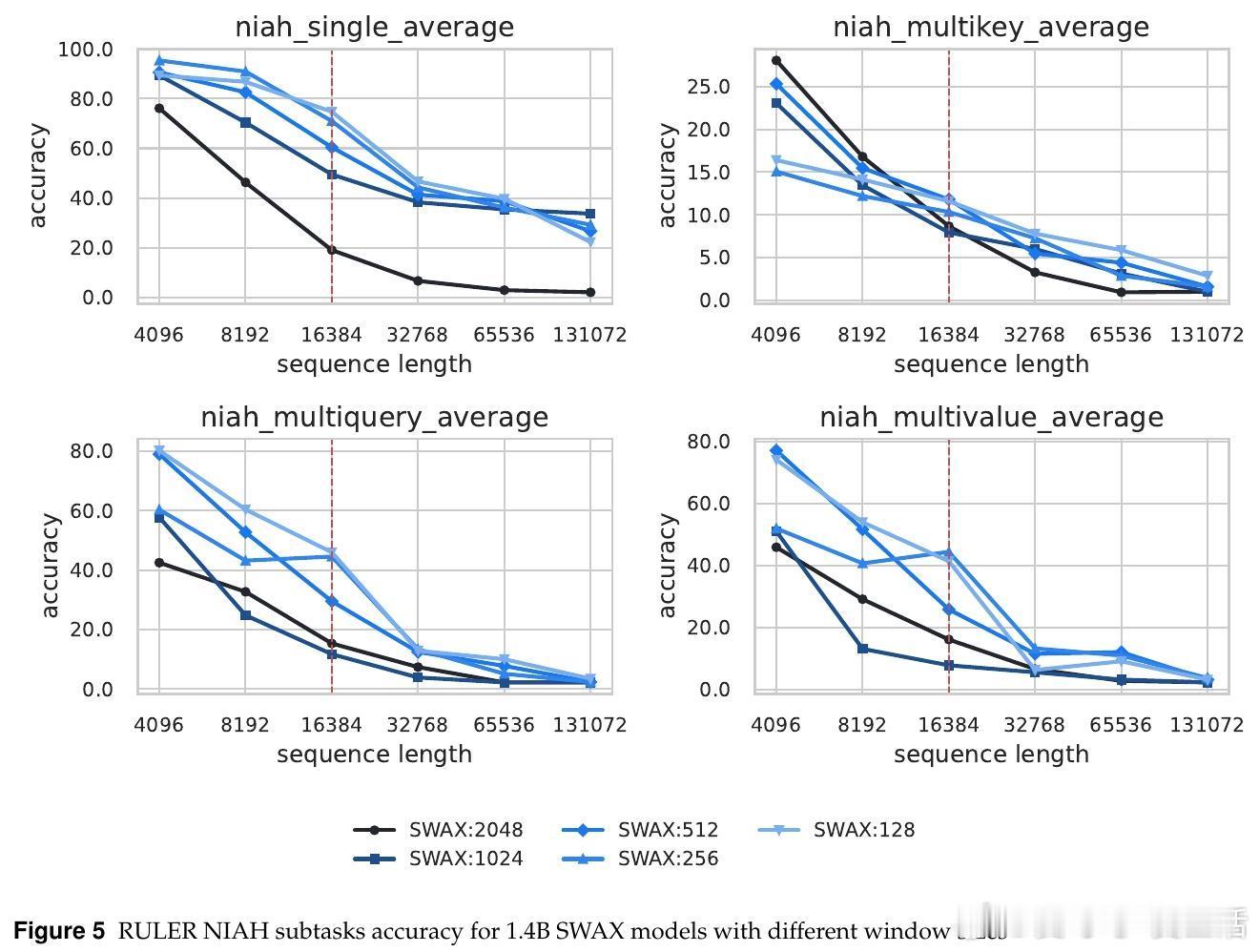
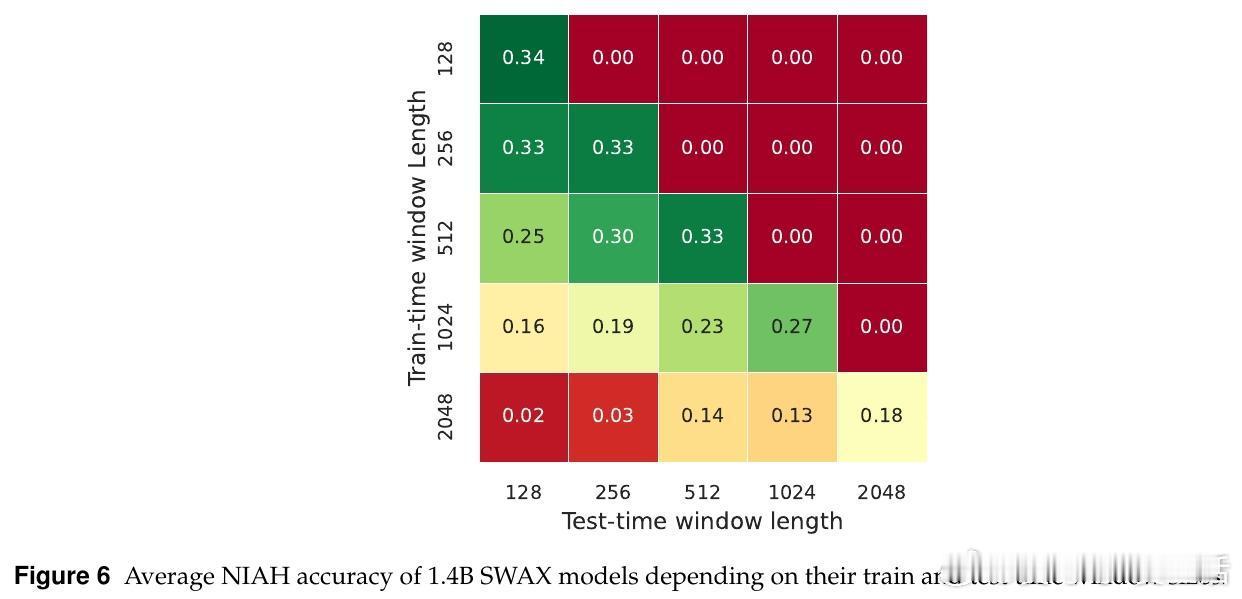
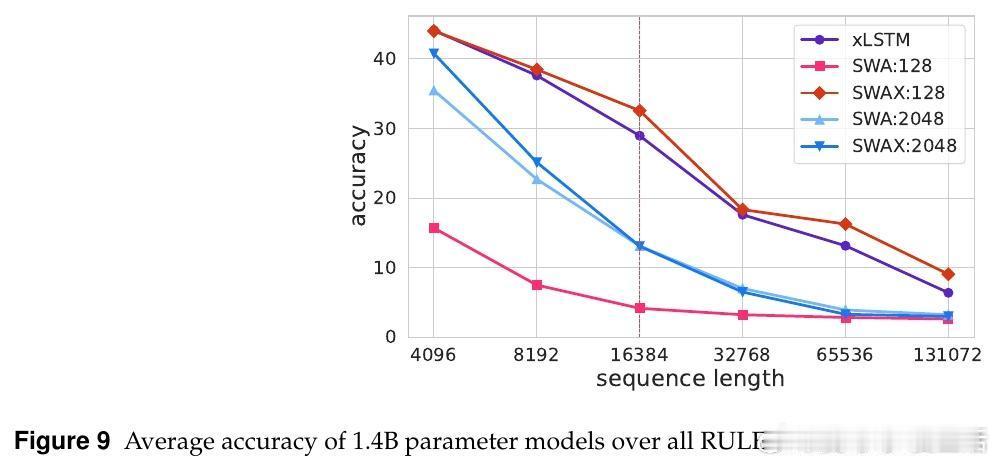
• 反直觉发现:增大滑动窗口长度不提升长上下文性能,反而短窗口促进xLSTM强化长时记忆,减少对软最大注意力的依赖。
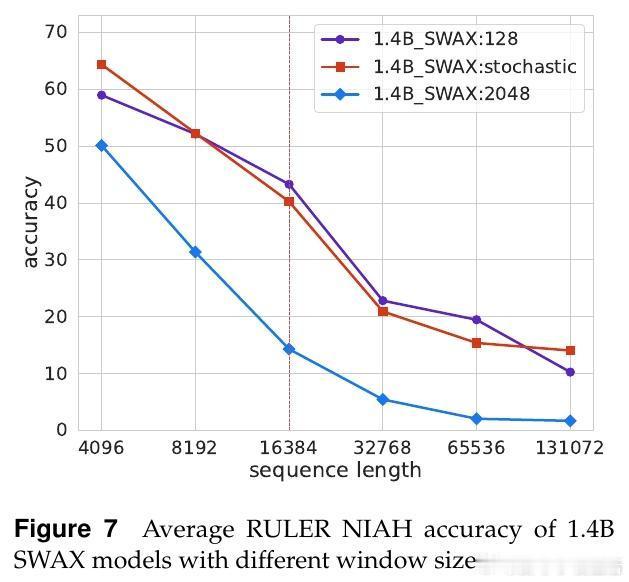
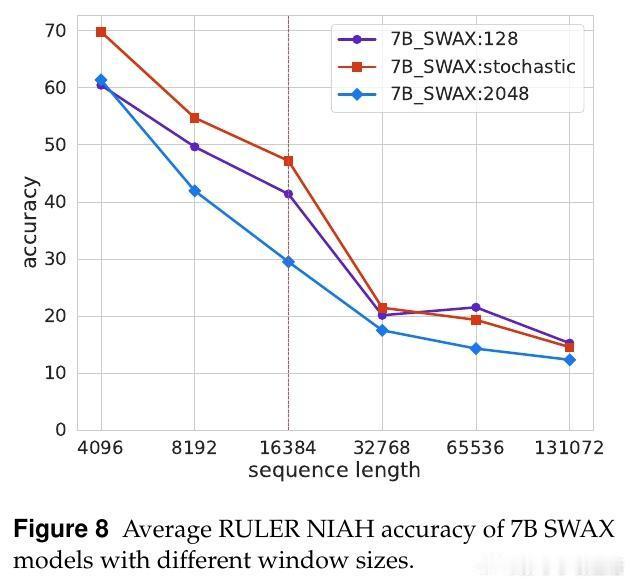
• 短窗口虽损害短上下文任务表现,但通过训练时随机切换窗口大小(128与2048之间)策略,模型兼顾长短期表现,显著超越固定窗口模型。
• 纯SWA模型难以处理超出窗口的长依赖,混合架构让软最大注意力负责高精度局部建模,线性注意力专注长期依赖,提升整体表现。
• 训练时过度依赖长窗口软最大注意力会抑制线性层的长时记忆学习,导致长序列外推能力下降。
• 采用随机窗口训练相当于对注意力机制进行一种“随机失活”,增强模型对长依赖的鲁棒性,同时保留短上下文的推理能力。
• 7B参数规模实验验证随机窗口训练策略不仅适用小模型,也能提升更大模型的长短上下文表现。
心得:
1. 长窗口并非万能,模型性能受训练策略深刻影响,短窗口能激发长期依赖机制的学习。
2. 软最大注意力与线性RNN的合理分工是关键——前者精准处理局部,后者承担全局记忆。
3. 训练过程中的随机性可视为对模型能力的正则化,促使模型在多场景下均表现优秀,避免过拟合某一窗口尺度。
了解更多🔗arxiv.org/abs/2509.24552
自然语言处理长上下文建模注意力机制混合架构机器学习深度学习