科学大语言模型(Sci-LLM)正引领科学研究范式变革,其核心驱动力来自对多模态、多尺度、跨领域科学数据的深度理解与整合。
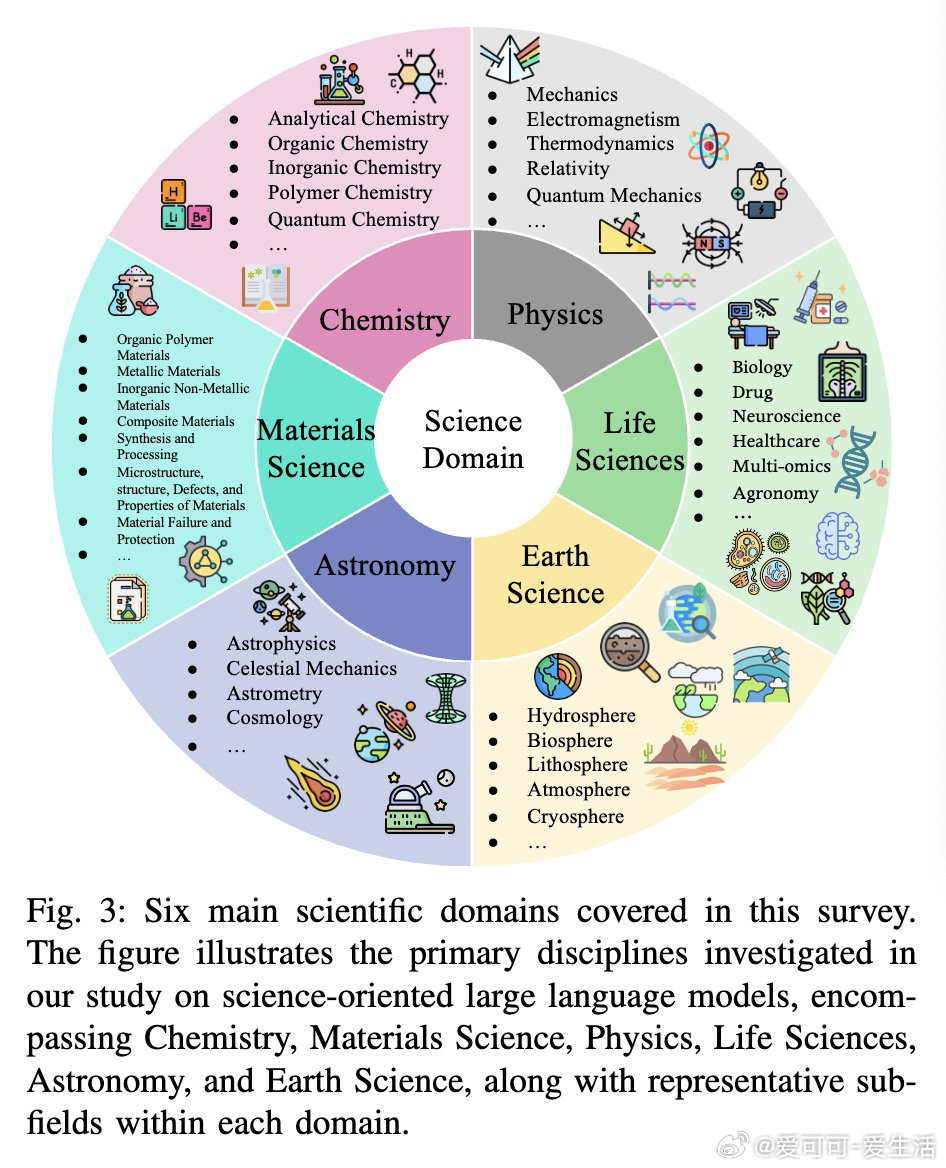
• 科学数据类型丰富:涵盖文本(论文、报告)、视觉(显微、天文影像)、符号(化学分子式、数学方程)、结构化数据(数据库、知识图谱)、时间序列(神经电信号、气象数据)及多组学整合(基因组、蛋白质、代谢组)等,要求模型具备跨模态融合能力。
• 科学知识呈多层次结构:从客观事实、理论框架、方法技术,到模拟建模,最终达至跨学科洞察,模型需理解并贯穿这些层级,实现从数据到洞见的科学推理。
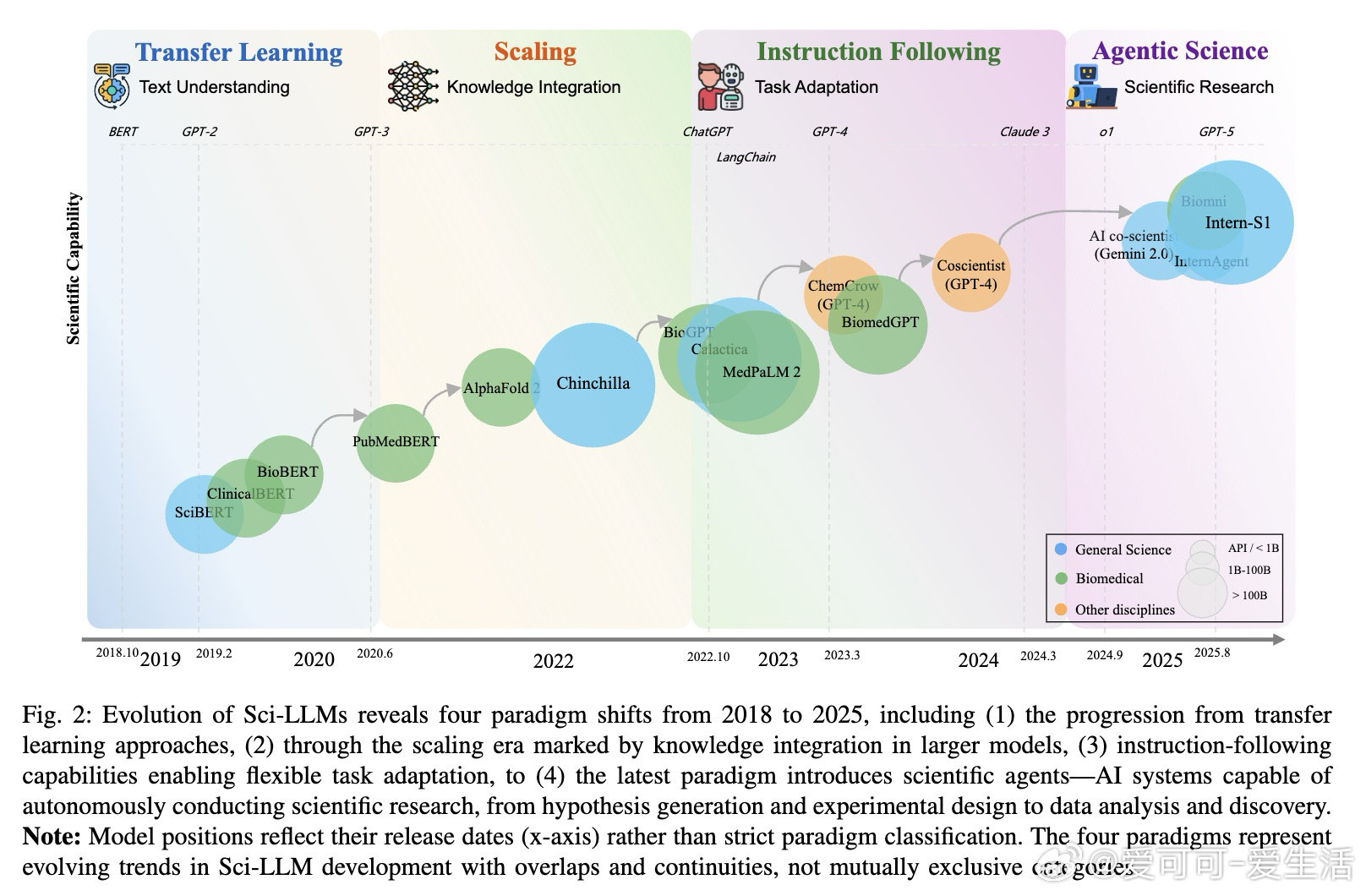
• Sci-LLM发展历程:经历转移学习(2018-2020)、参数与数据规模扩展(2020-2022)、指令微调(2022-2024)到智能科学代理(2023至今),后者具备自主规划、实验设计、数据分析与多智能体协作能力。
• 数据质量与挑战:强调准确性、完整性、时效性与可追溯性,当前面临实验数据稀缺、文本数据过度依赖、静态知识难以反映动态科学过程、以及多层次偏见等问题。
• 评估体系变革:从传统静态考试转向过程导向、协同工作流和科学发现能力的综合评估,采用多样化指标结合领域专属标准,推动模型科学认知与推理能力的提升。
• 未来趋势聚焦:构建具备操作系统级交互协议的数据生态,推动自动化科学数据标准化,强化模型的持续更新与版本控制,发展具备高级科学推理和自主发现能力的智能科学代理,实现闭环科学探索。
心得:
1. 科学数据的异质性和层次性要求模型不仅是语言理解者,更是跨模态、跨尺度知识的整合者,推动AI成为科学发现的活跃参与者。
2. 当前Sci-LLMs的性能瓶颈多源于数据本身的不足和偏见,优质、AI-友好且多模态的科学数据生态系统是未来突破的关键。
3. 评价体系的转型强调科学过程的透明性与可验证性,促使模型从静态答案生成走向动态推理与实验验证,体现科学精神的本质。
了解更多详情🔗arxiv.org/abs/2508.21148
科学人工智能 大语言模型 多模态学习 科学发现 自主智能代理