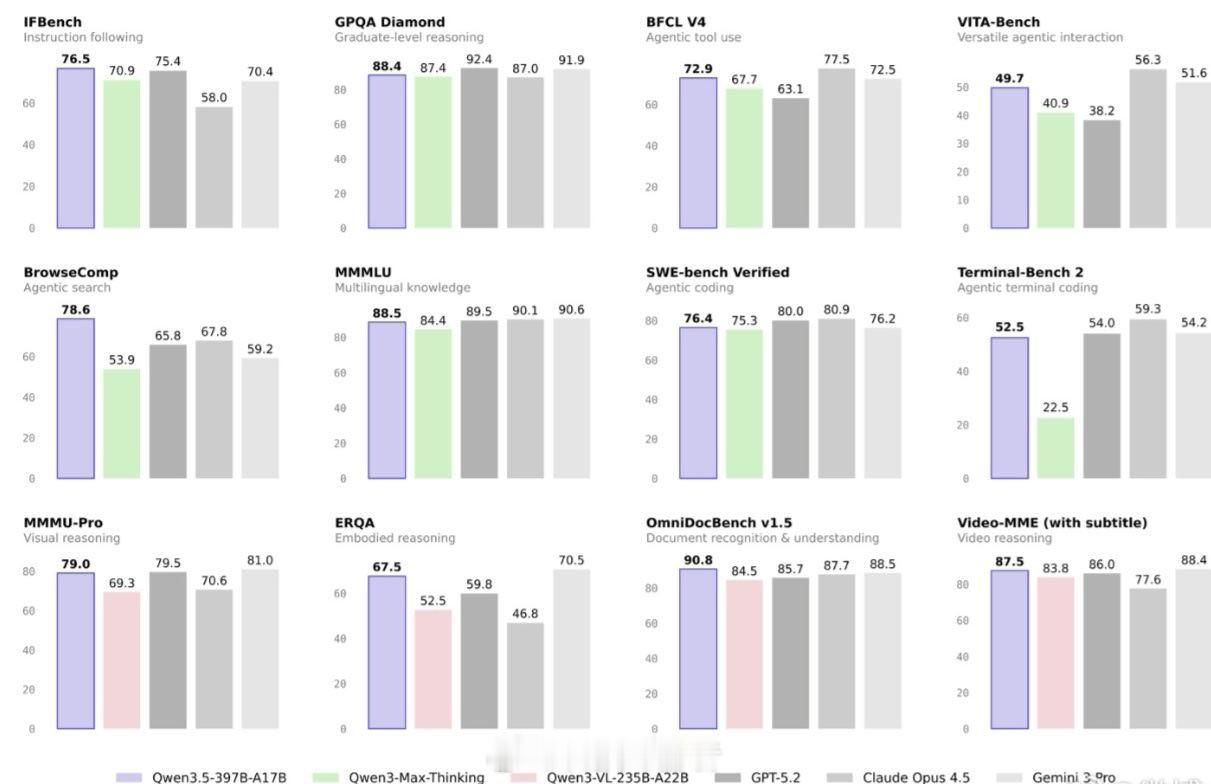
千问Qwen3.5大模型发布 聊到千问3.5,我觉得最值得聊的其实是它的“巧劲”。它没有盲目追求万亿参数,反而在架构上动了大刀子。这次最大的亮点就是采用了混合架构,把去年获得NeurIPS最佳论文的自研门控技术与稀疏混合专家模型结合起来。这个设计很聪明,总参数虽然高达3970亿,但每次推理只激活170亿参数,像个“召之即来挥之即去”的专家团队,既保住了大模型的实力,又把运行成本大幅降了下来。
正因为底子打得好,它的效率提升很惊人。在长文本处理上,吞吐量最高能提升19倍,这意味着处理同样的任务,速度更快、显存占用更低。另一个让我印象深刻的点是它真正迈入了“原生多模态”的门槛。它不是简单的文本模型加个视觉插件,而是在预训练阶段就直接混入了视觉和文本数据,让模型天生就看得懂图、读得懂视频。这种融合带来的直接好处就是,它能干一些很实在的活,比如直接把草稿图变成前端代码,或者自主操作手机App去帮你下单。据说春节期间它的购物Agent就处理了上亿笔订单,这已经不是实验室里的玩具了。简单来说,千问3.5的技术路线指向了一个很明确的未来:大模型不再拼谁更“重”,而是比谁更“巧”、更能干实事。过个有AI年