[LG]《Hierarchical Self-Attention: Generalizing Neural Attention Mechanics to Multi-Scale Problems》S Amizadeh, S Abdali, Y Li, K Koishida [Microsoft] (2025)
层级自注意力(HSA)为多尺度、多模态数据的Transformer开启新篇章:
• 传统Transformer虽广泛适配语言、图像、视频、音频等多种数据,但难以有效处理多尺度、多几何域的层级结构数据。现有多模态与层级Transformer多基于经验性设计,缺乏统一理论支撑,难以推广。
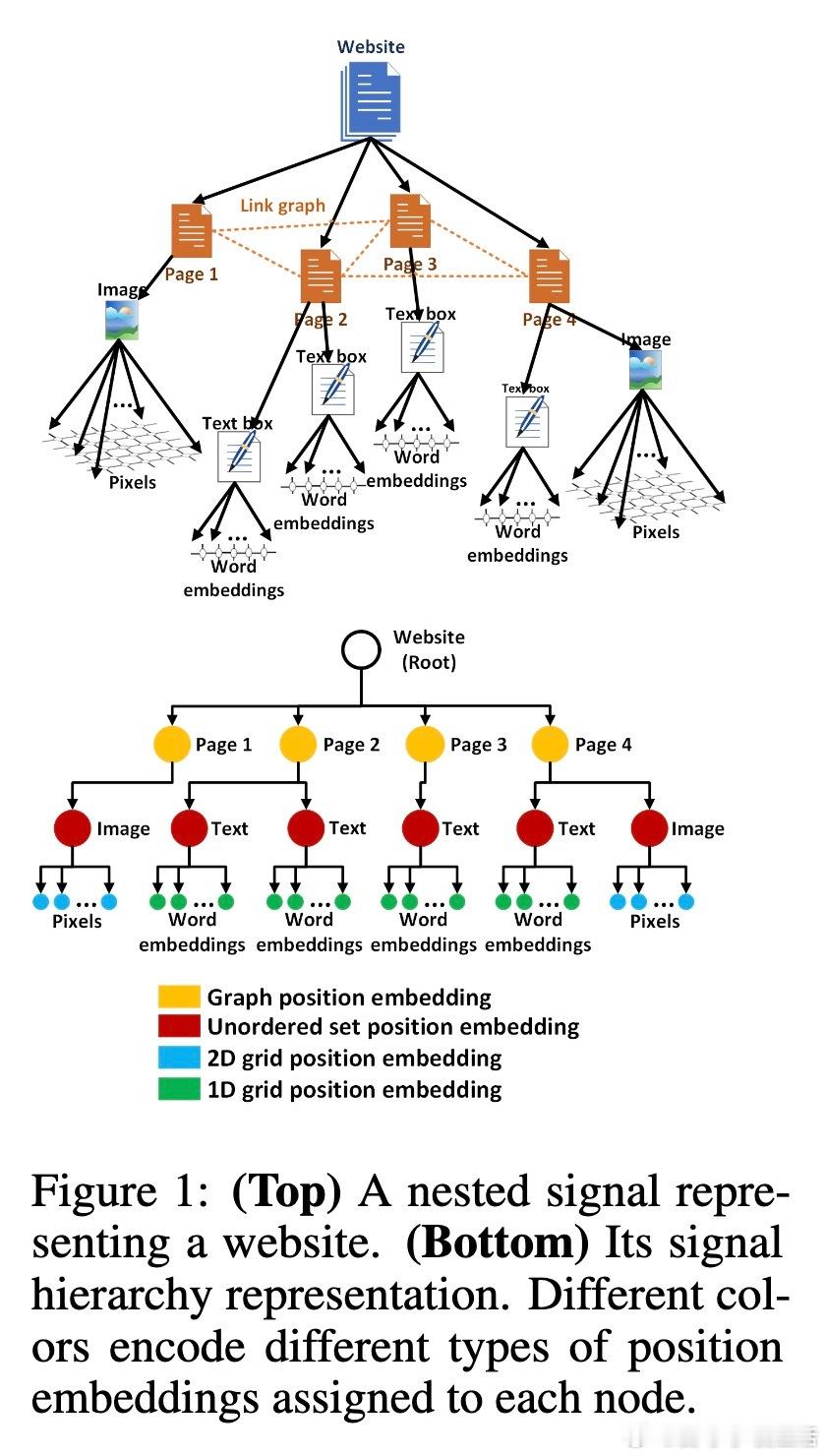
• 本文提出“嵌套信号”(nested signal)数学构造,统一表示跨多几何域和多尺度的层级数据,突破不同模态间位置编码不一致的难题。
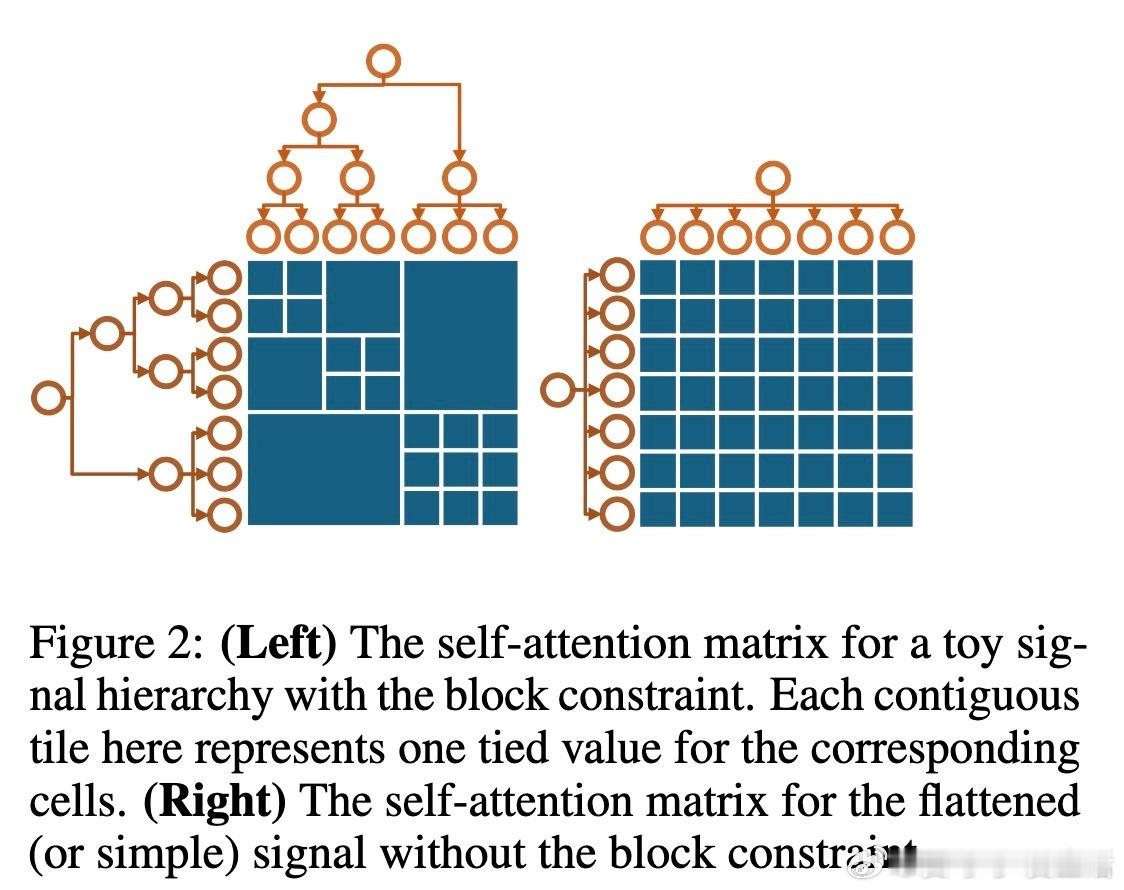
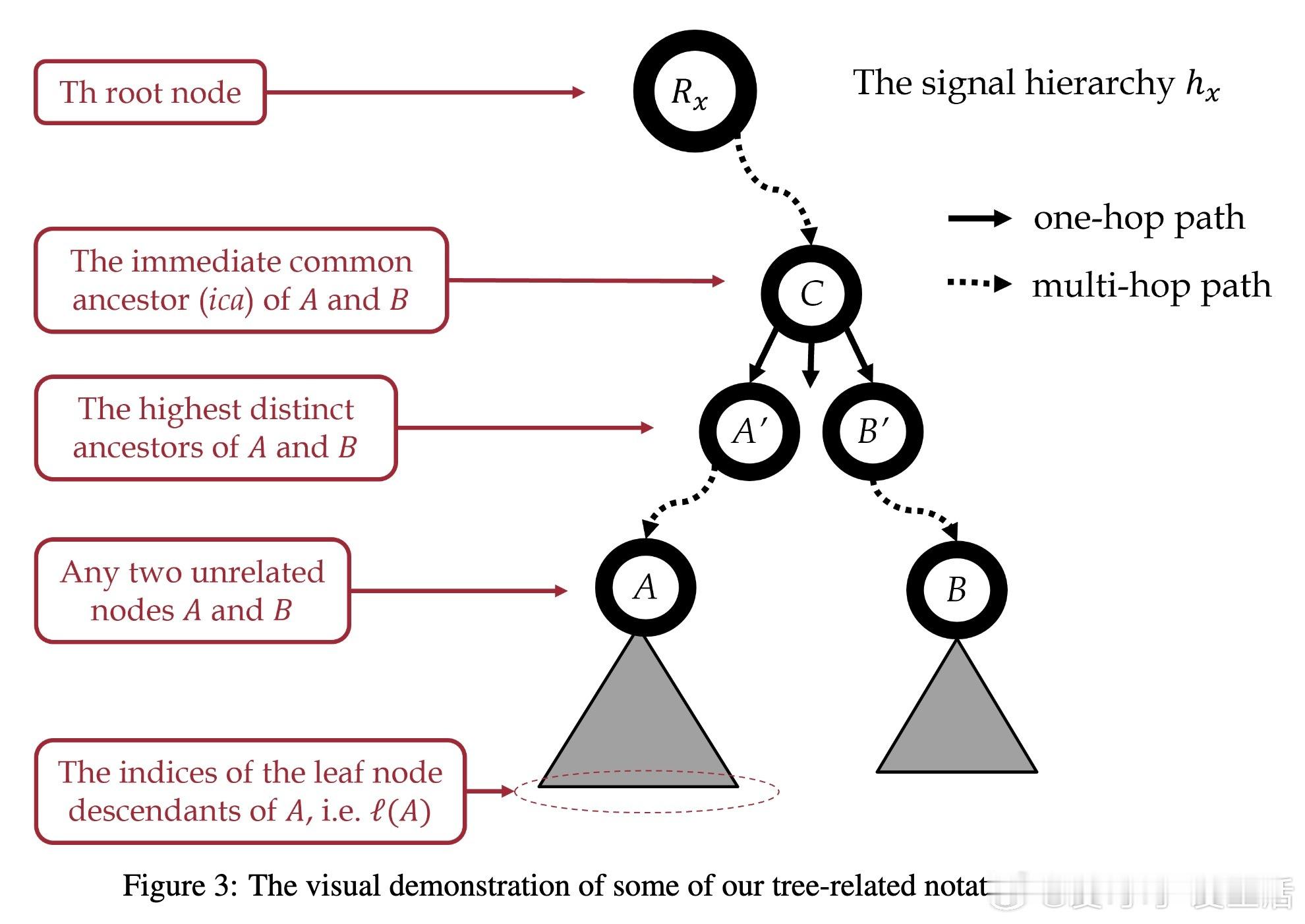
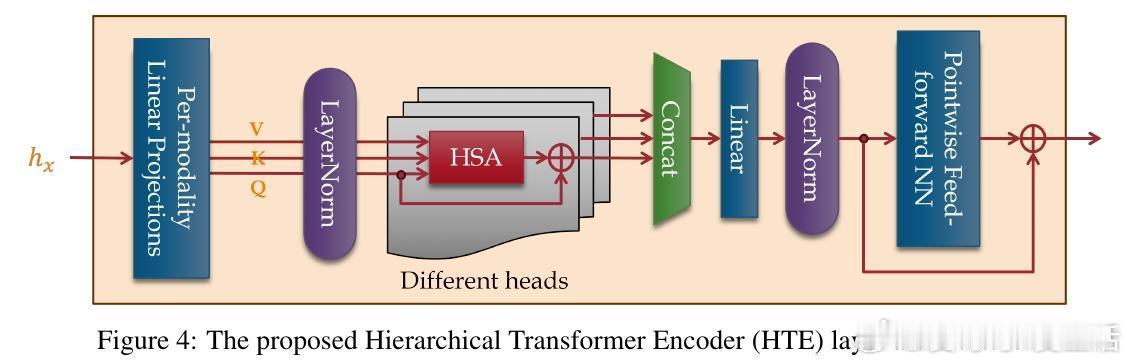
• 从熵最小化原理出发,严谨推导经典Softmax自注意力机制,继而推广至嵌套信号,得出层级自注意力(HSA)机制。HSA在KL散度意义下是最接近传统Softmax注意力同时满足层级结构约束的最优解。
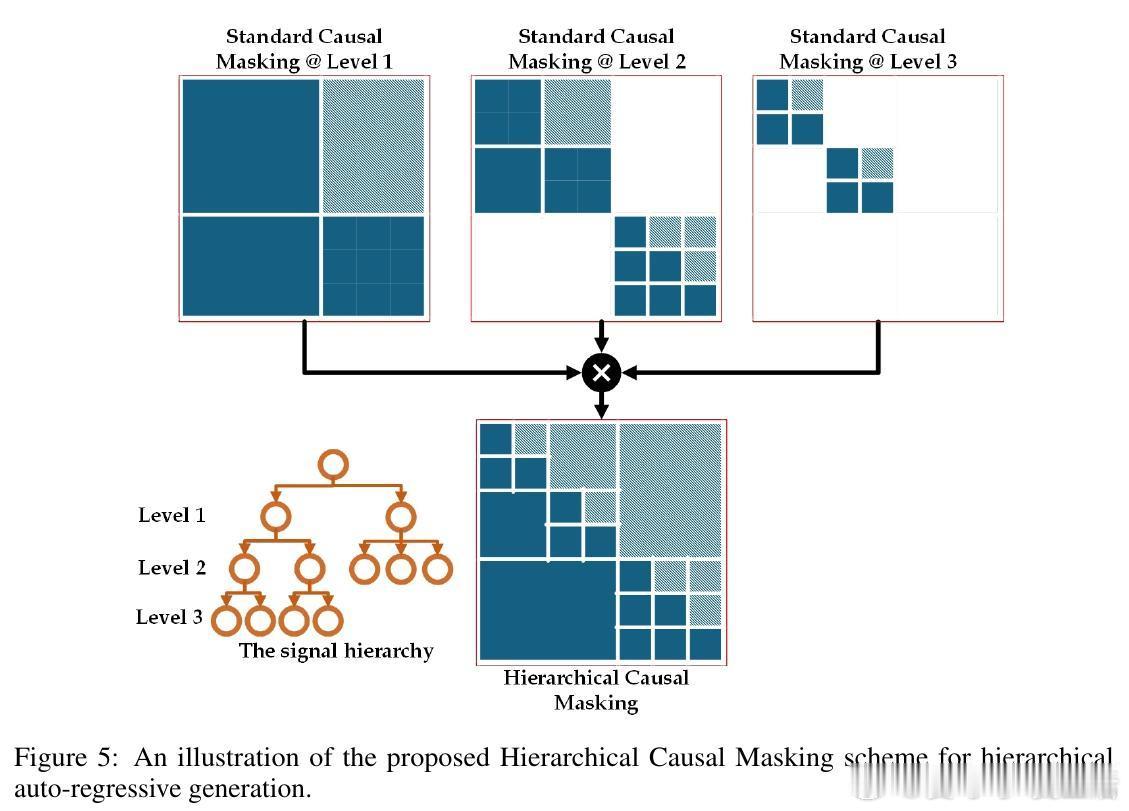
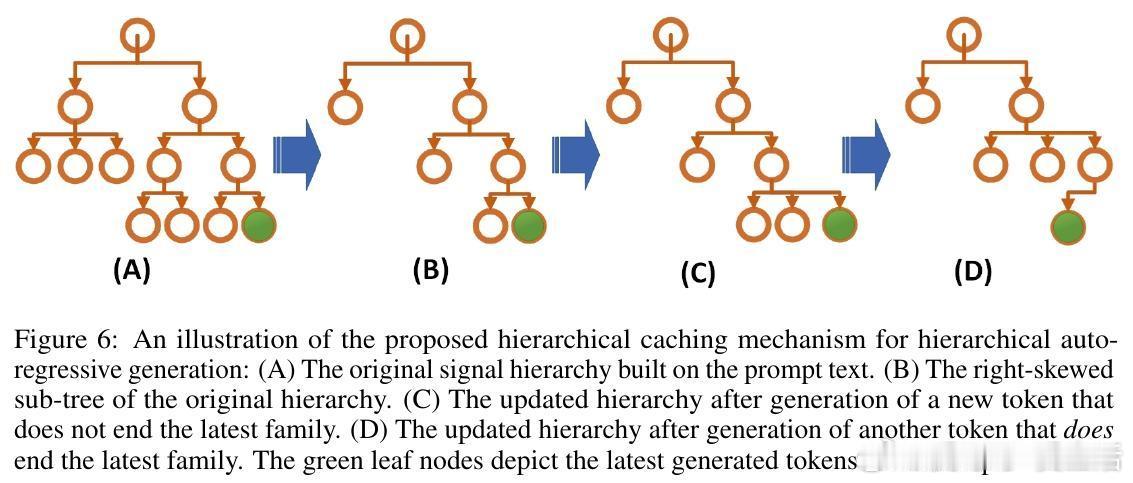
• 设计基于动态规划的高效算法,计算复杂度由传统的平方级降至线性级(相对于层级节点数),兼顾统计与计算效率。
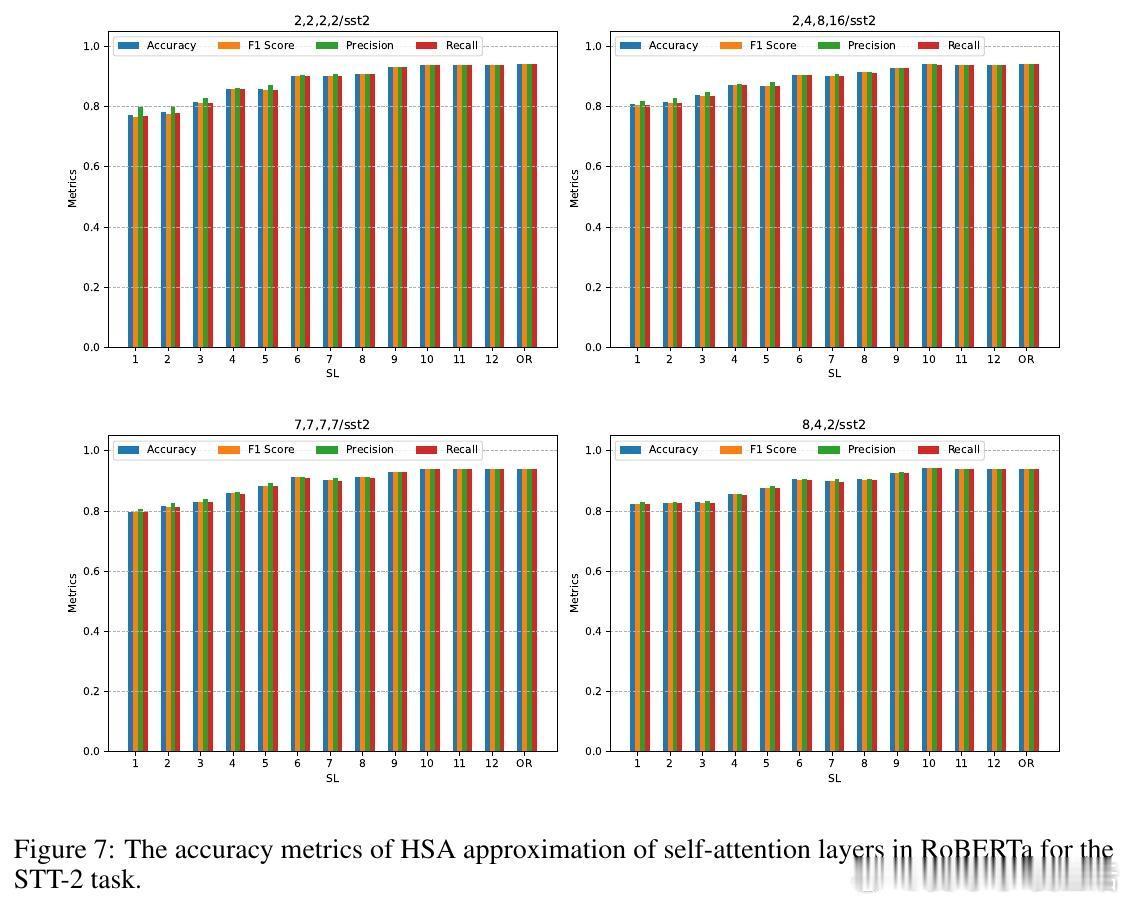
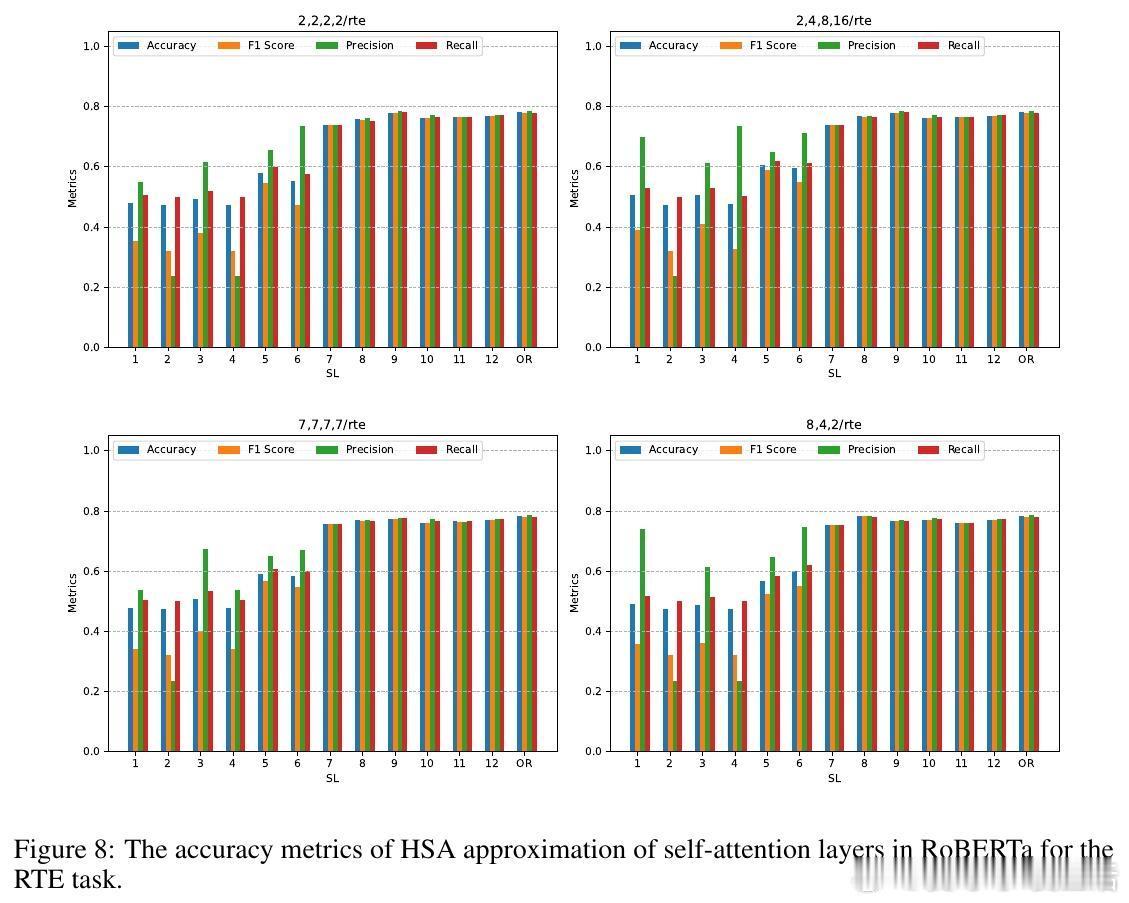
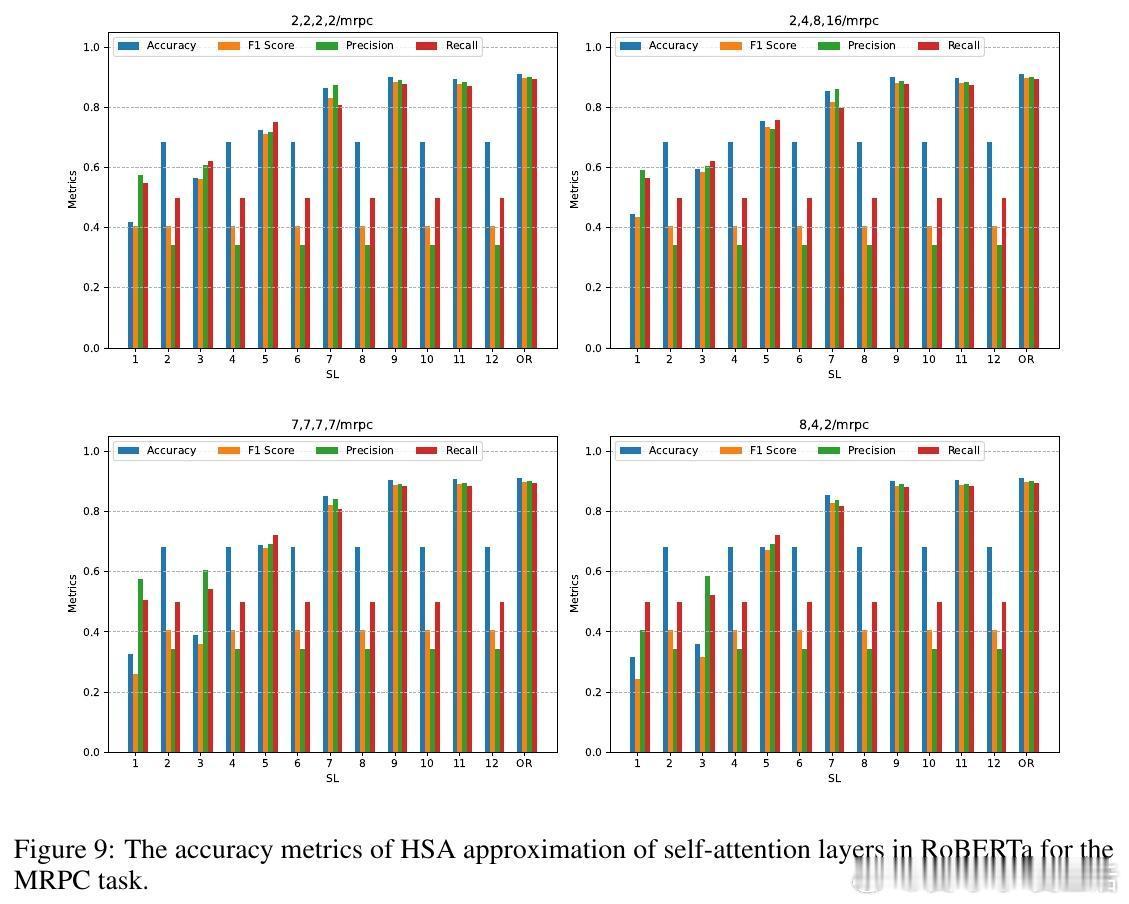
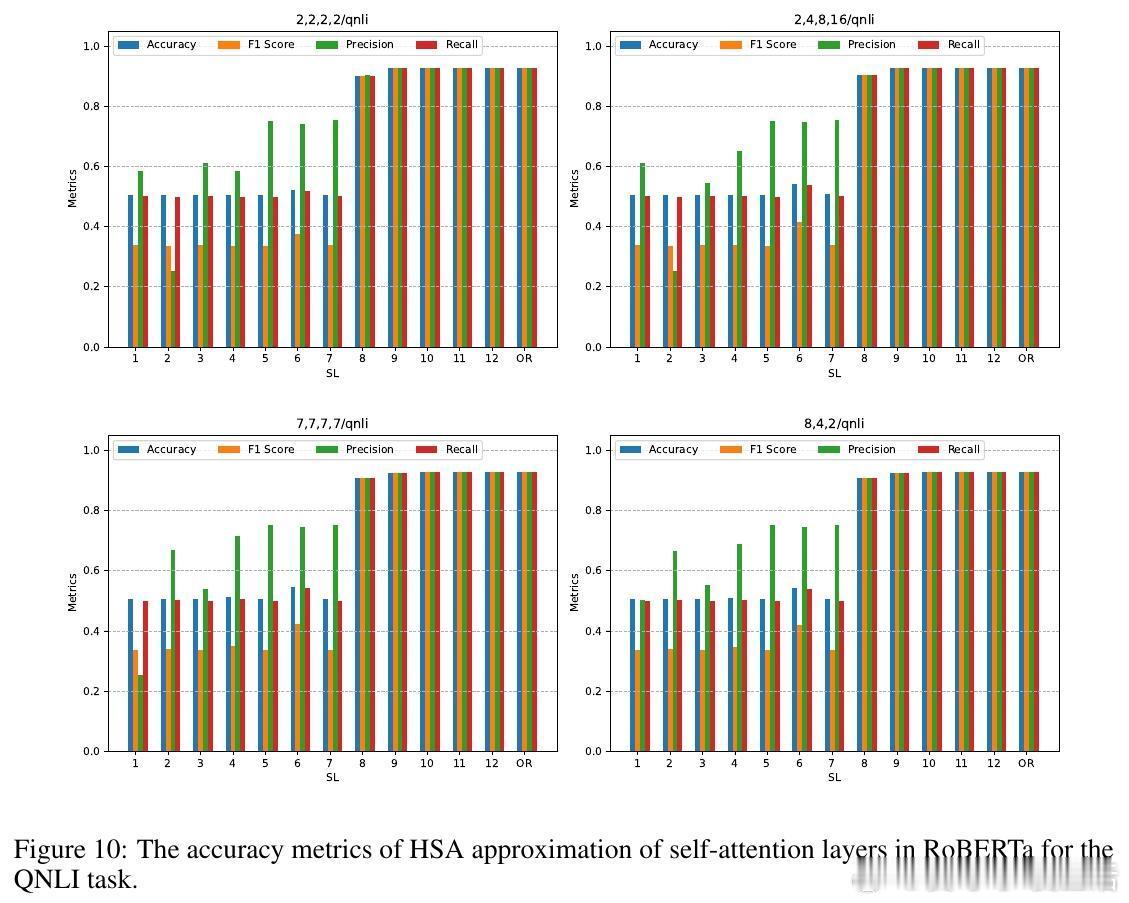
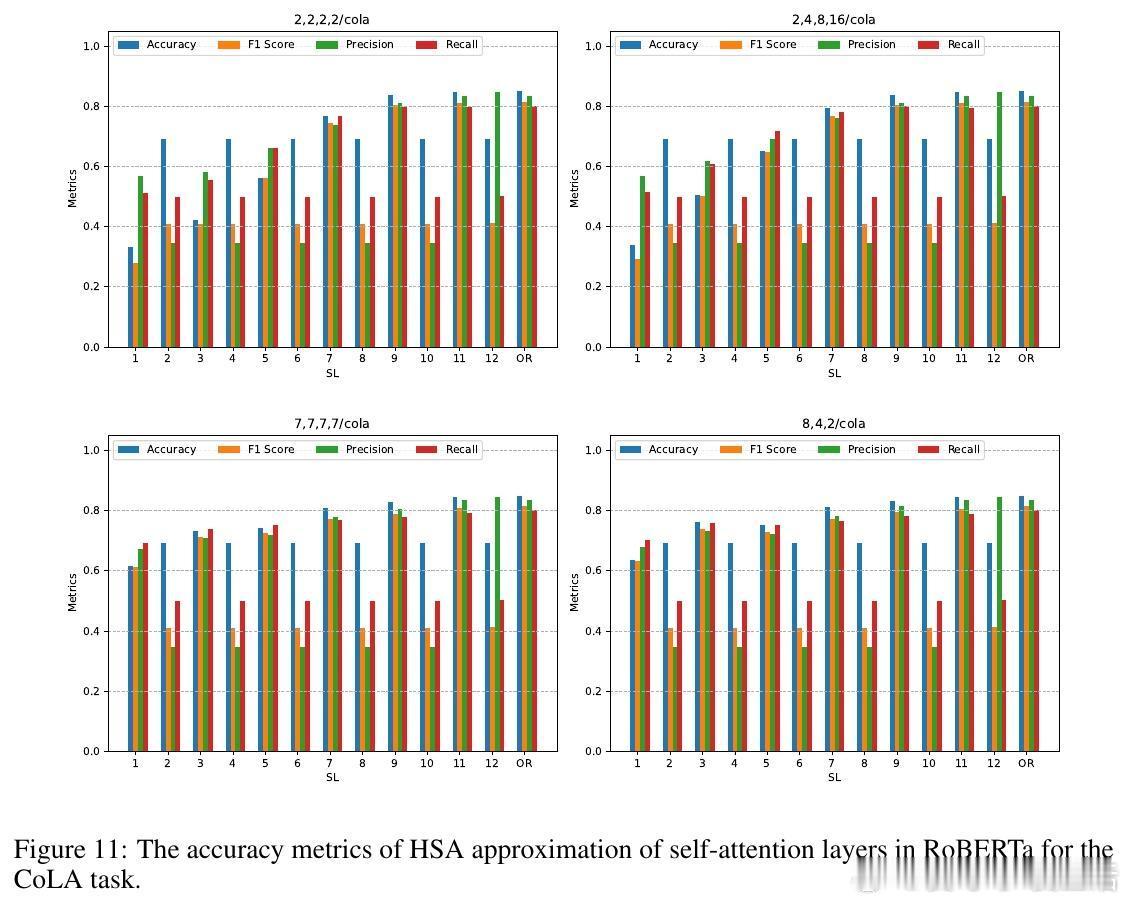
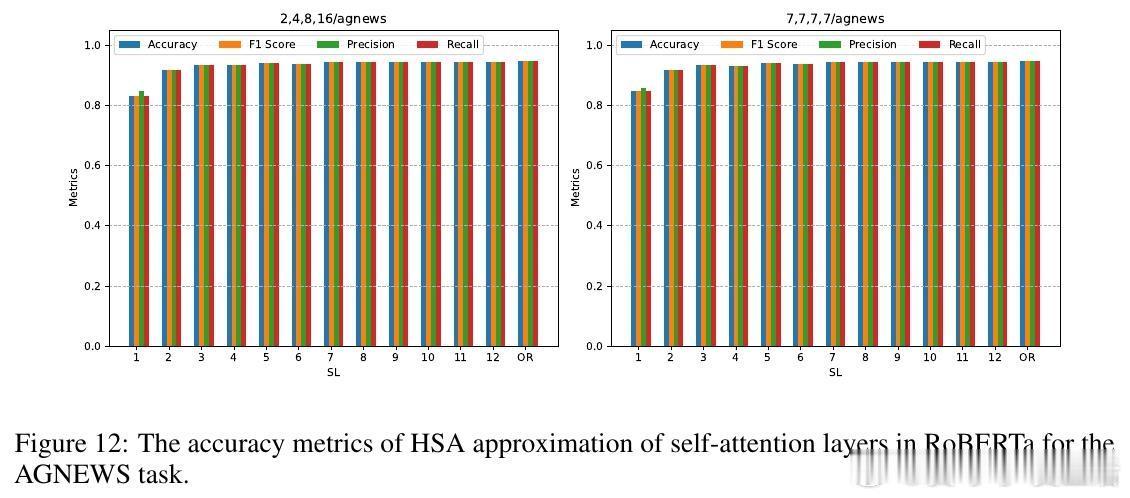
• 实验覆盖层级语言建模、跨模态新闻分类、预训练模型零样本层级近似替换等场景。HSA在长文本情感分类中显著提升准确率和F1分数,同时实现预训练RoBERTa模型部分层级替换,零样本条件下大幅降低自注意力计算FLOPs且几乎无性能损失。
心得:
1. 以数学形式统一多模态多尺度信号表达,解决了传统Transformer依靠位置编码难以兼容异构几何的问题,利于通用模型设计。
2. 层级结构作为天然的正则化,缓解长序列截断与过拟合,提升模型泛化能力,尤其在缺乏强预训练嵌入时优势明显。
3. 零样本层级替换开启Transformer后训练优化新思路,既能减小推理成本,又无需大规模再训练,极具实用价值。
详见🔗arxiv.org/abs/2509.15448
Transformer自注意力多模态学习层级建模深度学习算法优化