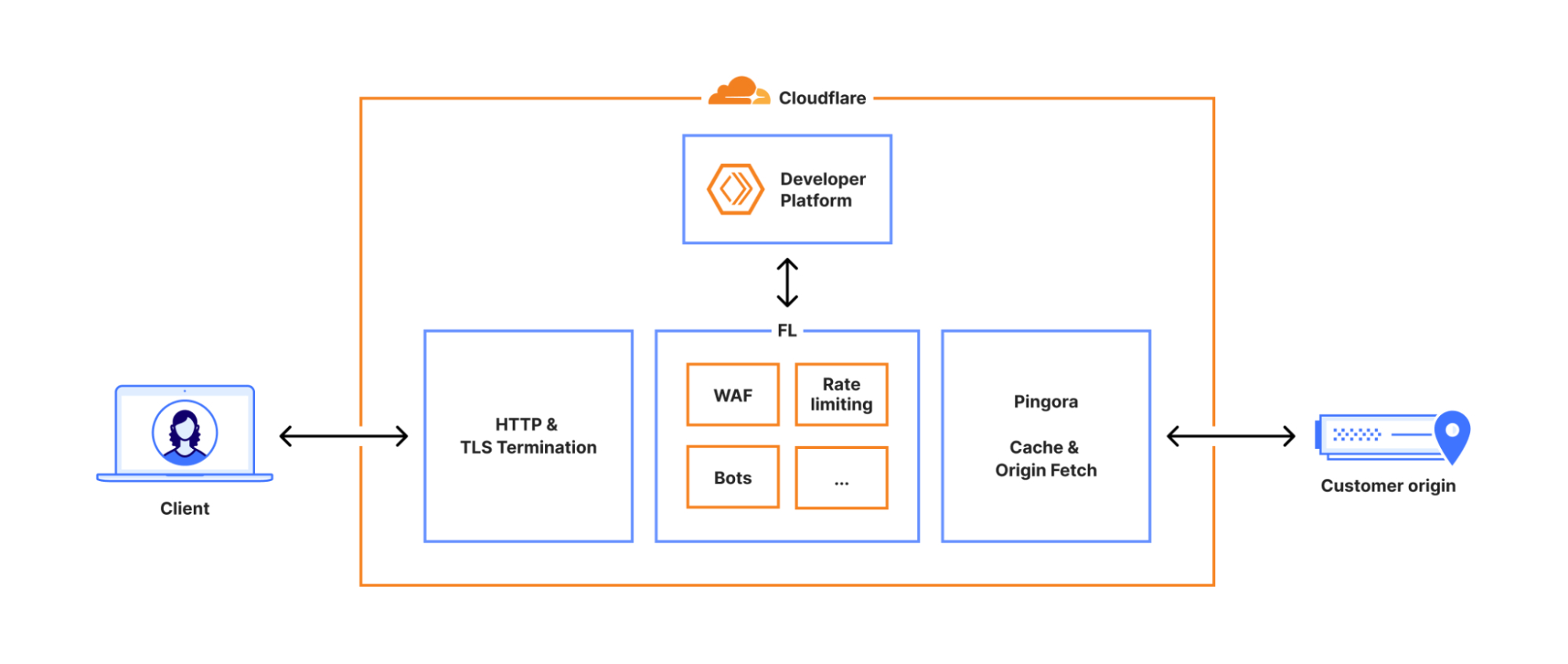
Cloudflare 官方发了该事故的复盘报告。简单来说,是Cloudflare 有一个维护着机器学习模型用来判断网络请求是否为“恶意机器人”的各项指标定义。系统每 5 分钟会对该数据库执行一次 SQL 查询,提取最新的特征列表,生成配置文件并下发到全球边缘节点,以实时更新全网的自动化威胁识别模型。Cloudflare 为了改进 ClickHouse 数据库的权限管理,调整了访问控制后,生成特征配置文件所依赖的一条元数据查询语句写错了,让特征文件中的特征数量和文件体积意外翻倍。这个超大特征文件被自动分发到全球代理节点后,触发了 Bot Management 模块中的内存预分配上限检查,加载该文件时直接 panic,导致核心代理(FL/FL2)在处理依赖该模块的请求时大量返回 5xx 错误。由于特征文件是每 5 分钟重新生成并推送一次,而且集群中只有部分分片一开始应用了权限变更,系统在一段时间内呈现“好配置”和“坏配置”交替生效的抖动状态,最终当所有节点都开始生成坏文件后,全网大范围宕掉。整个过程完全是由数据库权限变更与特征文件生成逻辑之间的隐含假设不匹配,加上配置文件大小/特征数量缺乏严格防御性校验共同触发的链式故障,而非任何外部攻击。 下面是核心部分的翻译,有兴趣的可以搜Cloudflare outage on November 18, 2025看原文。--------------------------2025年11月18日 UTC 时间 11:20(本文所有时间均为 UTC),Cloudflare 网络在传输核心网络流量时开始出现严重故障。对于试图访问我们客户网站的互联网用户来说,这表现为显示 Cloudflare 网络内部故障的错误页面。本次故障并非由网络攻击或任何形式的恶意活动直接或间接引起。相反,它是由于我们某个数据库系统的权限变更引发的,该变更导致数据库向我们的 Bot Management系统使用的“特征文件”输出了多重条目。这导致该特征文件的大小翻倍。随后,这个超出预期大小的特征文件被分发到了构成我们要网络的所有机器上。运行在这些机器上用于路由流量的软件会读取此特征文件,以保持机器人管理系统能够应对不断变化的威胁。该软件对特征文件的大小设定了一个限制,而翻倍后的文件超过了这个限制,导致软件崩溃。起初,我们曾错误地怀疑这些症状是由超大规模 DDoS 攻击引起的,但随后我们正确识别了核心问题,并停止了那个过大特征文件的传播,将其替换为该文件的早期版本。核心流量在 14:30 基本恢复正常。在接下来的几个小时里,随着流量重新涌入,我们致力于缓解网络各部分增加的负载。截至 17:06,Cloudflare 的所有系统均已恢复正常运行。对于给我们的客户以及整个互联网造成的影响,我们深表歉意。鉴于 Cloudflare 在互联网生态系统中的重要性,我们任何系统的任何中断都是不可接受的。在这段时间里,我们的网络无法路由流量,这对我们团队的每一位成员来说都是极其痛苦的。我们知道今天让大家失望了。本文将深入复盘究竟发生了什么,以及哪些系统和流程出现了故障。这也是我们为了确保此类故障不再发生而计划采取的一系列措施的开始,而非结束。------------------------------------每一个发送到 Cloudflare 的请求都会经过我们网络中一条定义明确的路径。它可能来自加载网页的浏览器、调用 API 的移动应用程序,或来自其他服务的自动化流量。这些请求首先在我们的 HTTP 和 TLS 层终止,然后流入我们的核心代理系统(我们称之为 FL,意为“前线”),最后通过 Pingora,它负责执行缓存查找或在需要时从源站获取数据。我们之前在此处分享了更多关于核心代理如何工作的细节。(图2)当请求通过核心代理传输时,我们会运行网络中可用的各种安全和性能产品。代理应用每个客户独特的配置和设置,从执行 WAF 规则和 DDoS 保护,到将流量路由到开发者平台(Developer Platform)和 R2。它是通过一组特定领域的模块来实现的,这些模块将配置和策略规则应用于通过我们代理传输的流量。其中一个模块——Bot Management(机器人管理),就是今天故障的源头。Cloudflare 的机器人管理包括一个机器学习模型(以及其他系统),我们使用该模型为通过我们网络的每个请求生成机器人评分(bot scores)。我们的客户使用机器人评分来控制允许哪些机器人访问其站点——或者拒绝哪些。该模型将“特征(feature)”配置文件作为输入。在这里,“特征”是指机器学习模型用来预测请求是否为自动化的一个独立属性。特征配置文件是各个特征的集合。该特征文件每隔几分钟刷新一次并发布到我们的整个网络,使我们能够对互联网上流量流的变化做出反应。它允许我们对新型机器人和新的机器人攻击做出反应。因此,随着恶意行为者迅速改变策略,频繁且快速地推出该文件至关重要。我们底层的 ClickHouse 查询行为发生的一个变更导致该文件包含了大量重复的“特征”行。这改变了原本固定大小的特征配置文件的大小,导致机器人模块触发错误。结果是,核心代理系统在处理我们客户的流量时,对任何依赖机器人模块的流量都返回了 HTTP 5xx 错误代码。这也影响了依赖核心代理的 Workers KV 和 Access。与此事件无关的是,我们当时正在(且目前仍在)将客户流量迁移到新版本的代理服务,内部称为 FL2。两个版本都受到了该问题的影响,尽管观察到的影响有所不同。部署在新 FL2 代理引擎上的客户观察到了 HTTP 5xx 错误。使用我们旧代理引擎(FL)的客户没有看到错误,但机器人评分未能正确生成,导致所有流量收到的机器人评分为零。部署了阻止机器人规则的客户会看到大量误报。未在其规则中使用我们的机器人评分的客户未受到任何影响。另一个让我们分心并误以为这可能是一次攻击的表面症状是:Cloudflare 的状态页面(Status Page)挂了。状态页面完全托管在 Cloudflare 基础设施之外,不依赖于 Cloudflare。虽然这后来被证明是一个巧合,但它导致负责诊断问题的部分团队成员认为攻击者可能同时针对我们的系统和我们的状态页面。当时访问状态页面的访问者会看到一条错误消息。(图3)在内部事件聊天室中,我们要担心这可能是近期高流量 Aisuru DDoS 攻击的延续。时间线:🕐 11:05 - 部署数据库访问控制变更。 🕐 11:28 - 故障开始。变更到达生产环境,客户流量开始报错。 🕐 11:32 - 团队介入调查。最初怀疑是 DDoS 攻击或 Workers KV 问题。 🕐 13:05 - 实施缓解。对 Workers KV 和 Access 实施绕过策略,影响有所减轻。 🕐 13:37 - 定位方向。确信 Bot Management 配置文件是根源,开始尝试回滚该文件。 🕐 14:24 - 停止止血。停止自动生成新的配置文件,并测试旧版本文件。 🕐 14:30 - 主要恢复。正确的配置文件部署至全球,大多数服务恢复正常。 🕐 17:06 - 完全结束。所有下游服务重启完毕,系统完全恢复。