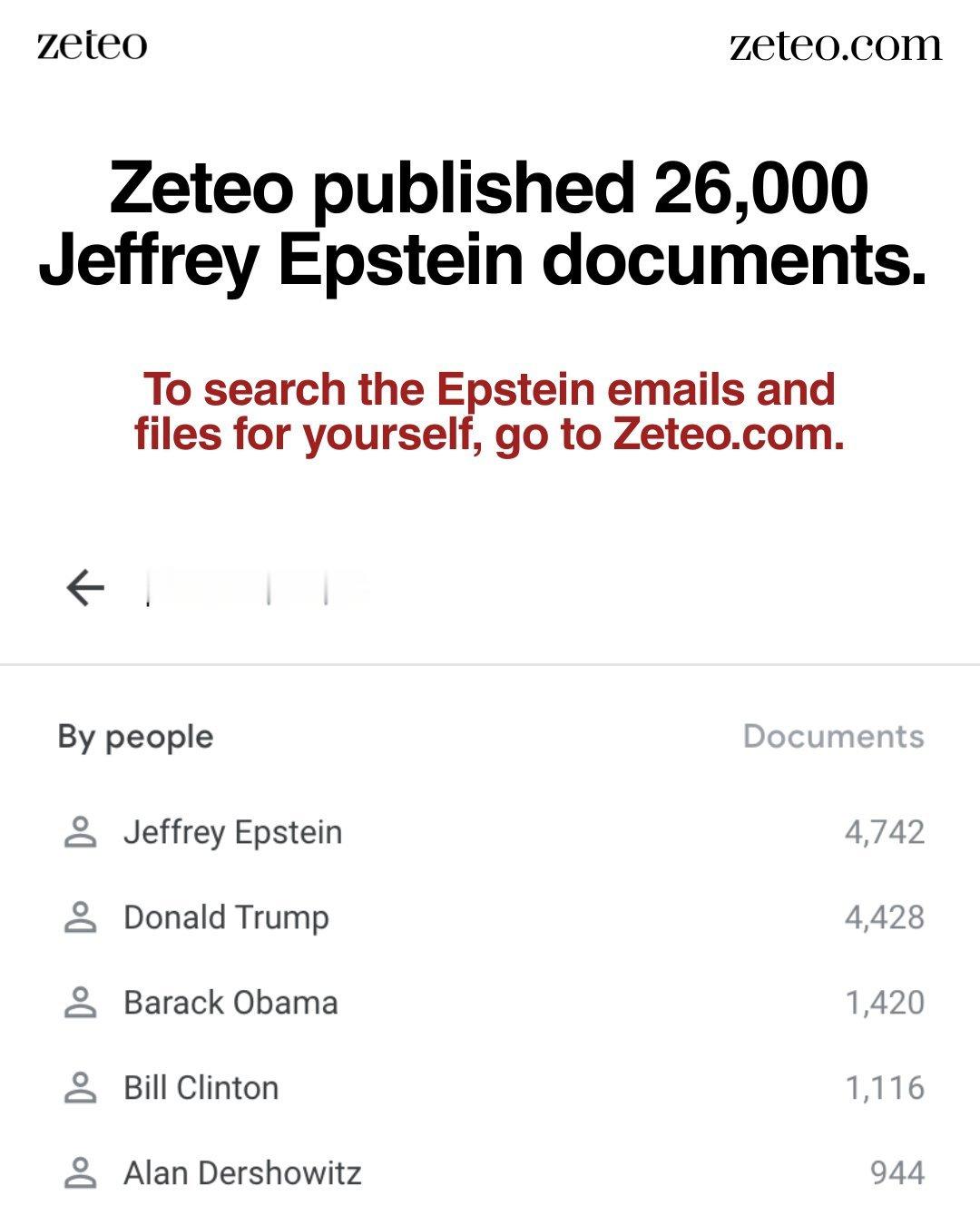
Taelin 对 Gemini 3 的深度评测,值得每个关注 AI 编程和调试的人细读。这款模型在我最难的测试题上,轻松超越 GPT-5 Pro、Gemini 2.5 Deep Think 等竞品,堪称新一代旗舰。尤其擅长:- 复杂编译器 Bug 调试 - 大型文件无误重构 - 难度极高的 λ 演算问题 - ASCII 艺术(首次接近可用水平) - 以及一场私下的 Gen 3 竞赛但它毕竟还是 LLM,短板明显:- 理解用户意图较差 - 容易“用力过猛”写出超出要求的代码 - 一次性生成文件不如 GPT-5.1 - 创意写作和医疗健康问答表现不佳 我还怀疑这次公开的版本并非谷歌最强模型。举个例子,几周前一条卡住我多时的 HVM4 编译器 Bug(栈下溢),被社区用旧版本模型解决了,可 Gemini 3 反而没识别出问题所在。在 λ 演算的“n-tuple-rotl”测试中,Gemini 3 交出一行代码的简洁完美解法,远超其他模型五倍规模的失败尝试,令我震惊。它解题速度是我自己的五倍,这种“微观优雅”堪称艺术。真实项目中,它调试旧代码效率惊人,曾几小时的难题一两分钟搞定。重写 HVM4.hs 这样的核心文件,它精准无误,证明了对细节的超强把控——这是此前模型的短板。不过,它在“一次成型”生成网页应用时表现逊色,输出文件体积更小但缺功能且有多处漏洞,远不如 GPT-5.1。创意写作和健康问答不靠谱,且常常在简单修改任务中写出整篇文件,反而效率低。总结来说:- 复杂调试、代码重构首选 Gemini 3,无疑 - 一次成型文件生成首选 GPT-5.1 - 大规模简单修改推荐 Claude Code + Sonnet 4.5 - 其他领域依旧聊聊 ChatGPT - 如果只能选一个订阅,OpenAI $200 方案目前仍是最优平衡 这只是第一天体验,未来表现还有待观察。Gemini 3 已展现极强技术实力,但“人性化”的细节仍需打磨。选择 AI 助手,别只看基准测试,真实场景才是终极考验。更多细节: x.com/VictorTaelin/status/1990844923994886282