图解多头注意力机制详解Transformer核心组件
图解多头注意力机制(Multi-head Attention),它像模型的“多副眼睛”,能同时从多个角度去理解输入信息。
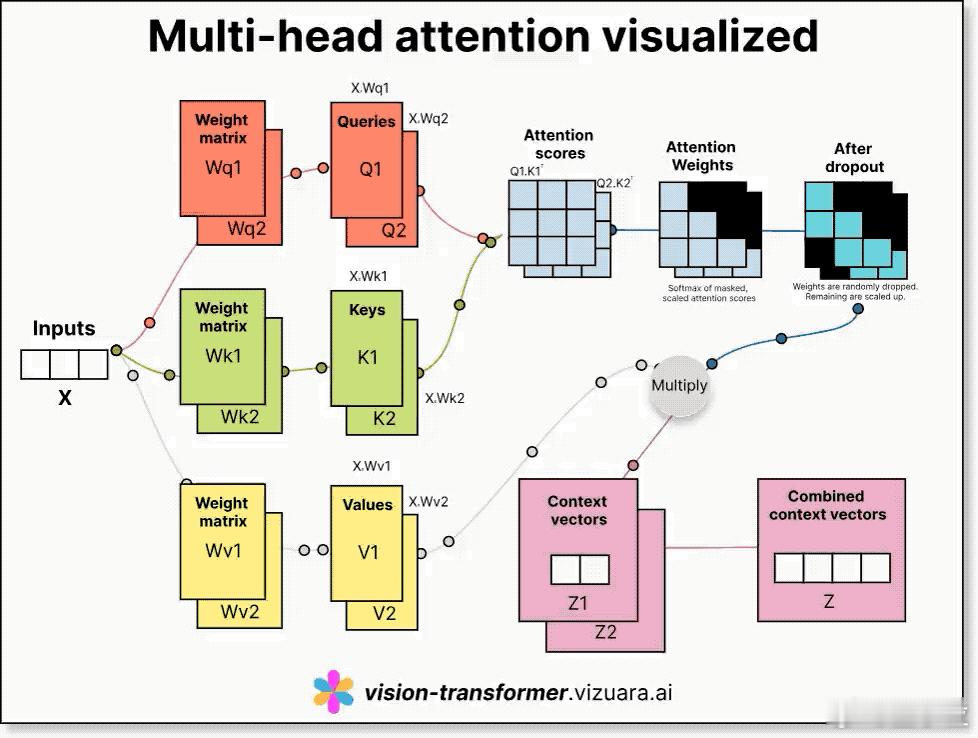
1. 输入X通过三套不同的权重矩阵,分别生成Query(Q)、Key(K)、Value(V)三个向量序列。
- Query表示“我要看什么”,Key是“可以被看什么”,Value是“我真正要拿的信息”。
- 每一套QKV都用不同的权重矩阵(Wq、Wk、Wv)从输入X中线性映射生成。
2. 计算注意力分数(Attention Scores):通过Q乘以K的转置,再除以缩放因子sqrt(dk),得到每个词与其它词的相似度评分。
3. 应用Softmax生成注意力权重(Attention Weights):将分数归一化为概率形式,决定每个词该关注哪些其它词。
4. Dropout做正则化:防止模型过拟合,有一部分权重会被随机丢弃。
5. 加权求和得出上下文向量:把注意力权重和V相乘,得到这个词在当前上下文下的理解表示。
6. 多个头并行处理,输出拼接后再投影:
- 多头注意力中,每个“头”会用不同的权重矩阵处理同样的输入,各自从不同角度获取信息;
- 最后拼接所有头的输出,再通过线性变换统一为模型需要的输出维度。
这个机制的优势在于:
- 并行捕捉多种语义关系:不同的头可以分别学语法结构、实体指代、长距离依赖等;
- 提升学习效率与表达能力;
- 增强模型鲁棒性,减少对单一关注模式的依赖。
多头注意力不仅支撑了NLP模型的“理解力”,也广泛应用于Vision Transformer、语音模型等多个AI领域,是现代深度学习架构的基础模块之一。