8000行代码学会LLM训练全流程卡帕西教你4小时训练大模型
只需4个小时、8000行代码,就能学会LLM训练全流程!
这就是大神卡帕西发布的从零构建LLM项目。
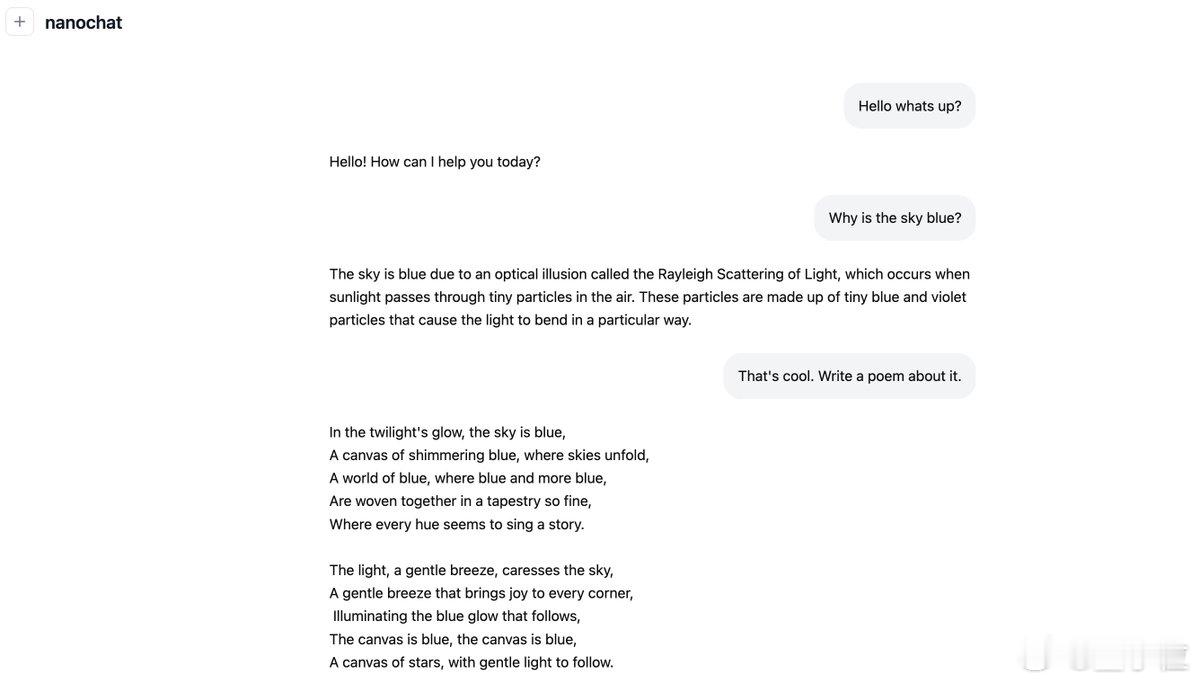
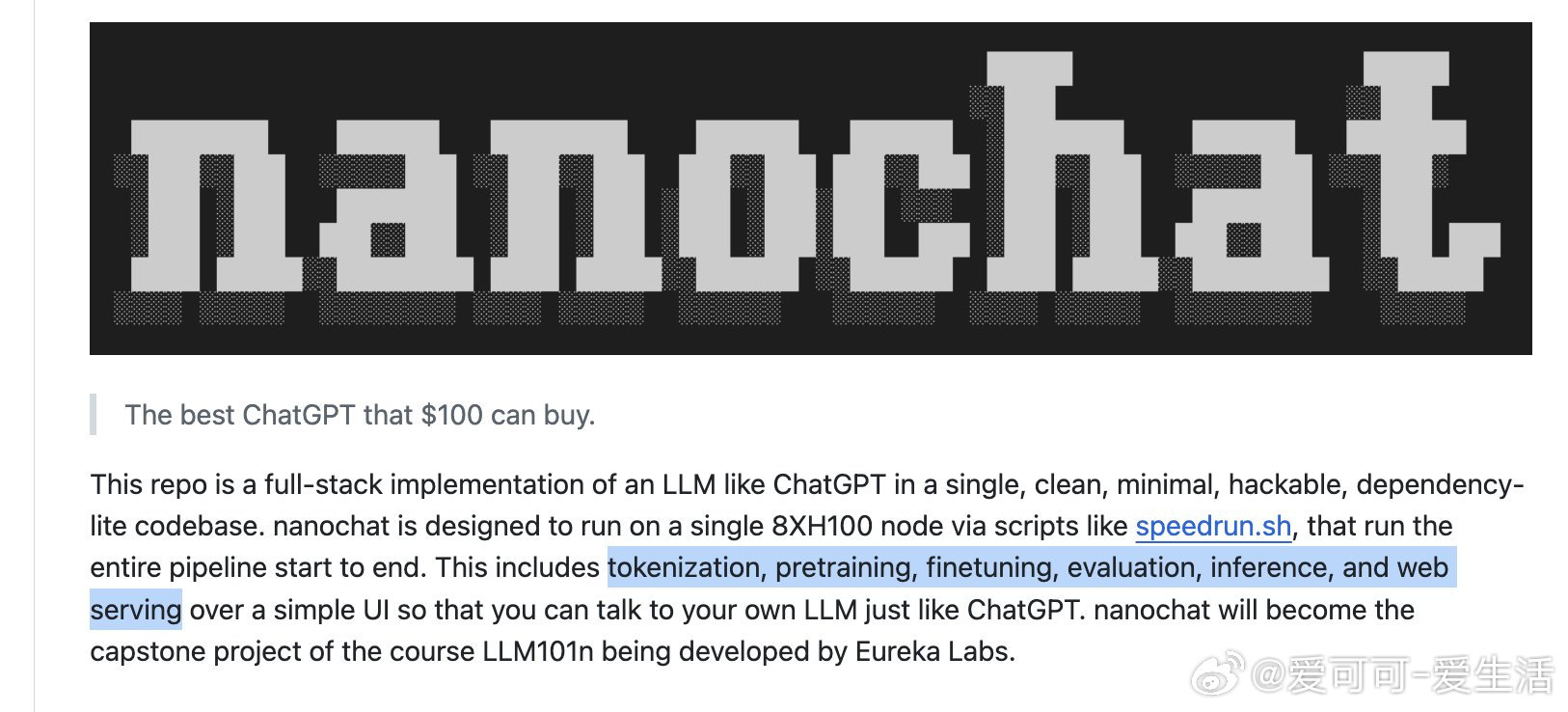
项目名为nanochat,跟着做就能跑通大模型训练的全流程,包括分词、预训练、对齐、推理,还附带WebUI界面。
这也是他LLM101n课程的“毕业项目”,卡帕西自己都说,这是他写得最“精神错乱”的一次,几乎是全身心放飞了。
一、什么是nanochat?
- 一个完整的类ChatGPT训练和推理系统
- 用最少代码构建训练闭环,全流程hackable
- 能在8×H100上单脚本一键启动,从训练到部署只需4小时
训练出来的小模型能写故事、写诗、简单答题。12小时版本在CORE指标上超过GPT-2,继续投入时间和预算(1000美元/41小时),还能进一步提升到能解数学题、写代码。
二、怎么实现的?
1. 从头训练分词器:用Rust写了全新分词器
2. 预训练:基于FineWeb语料训练Transformer架构
3. 中期训练:引入SmolTalk数据(用户助手对话、多选题)
4. SFT阶段:覆盖常识、数学、代码测试
5. 强化学习(可选):支持在GSM8K上用GRPO进行RL
6. 推理引擎:支持KV cache、工具调用,带CLI和网页聊天界面
7. 自动生成报告卡:训练后自动输出评估结果的Markdown报告
核心模型结构参考LLaMA,做了大量精简调整,像是取消位置编码、使用Multi-Query Attention、ReLU²激活函数等,优化了性能和成本。
三、普通人就能跑
只要有GPU资源,执行`scripts/speedrun.sh`就能启动训练过程。4小时后,访问项目提供的网页地址,就能像ChatGPT一样和你自己训练的模型对话。
如果没有8×H100,也能在A100甚至单卡上跑,只是时间会翻倍,batch需要调整。
对普通开发者来说,这意味着:
- 不再只能调用大模型,而是能自己训练一个
- 不需要庞大基础设施,也能上手完整训练逻辑
- 哪怕不追求模型性能,也能看清楚大模型背后的所有步骤
网友评价道:“这是LLM世界的Hello World”。
GitHub项目地址:github.com/karpathy/nanochat





只是讨厌屈服
留用感谢