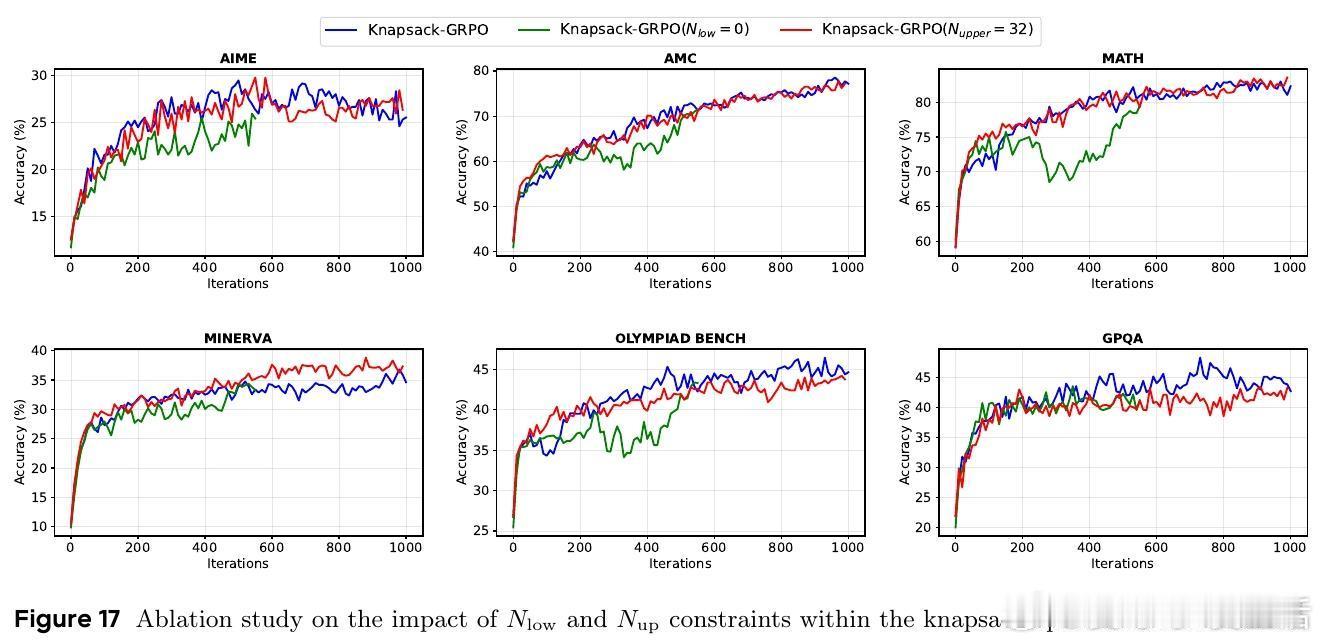
[LG]《Knapsack RL: Unlocking Exploration of LLMs via Optimizing Budget Allocation》Z Li, C Chen, T Yang, T Ding... [ByteDance Seed & The Chinese University of Hong Kong] (2025)
论文《Knapsack RL: 通过优化预算分配释放大型语言模型探索潜力》亮点总结:
🔍背景:
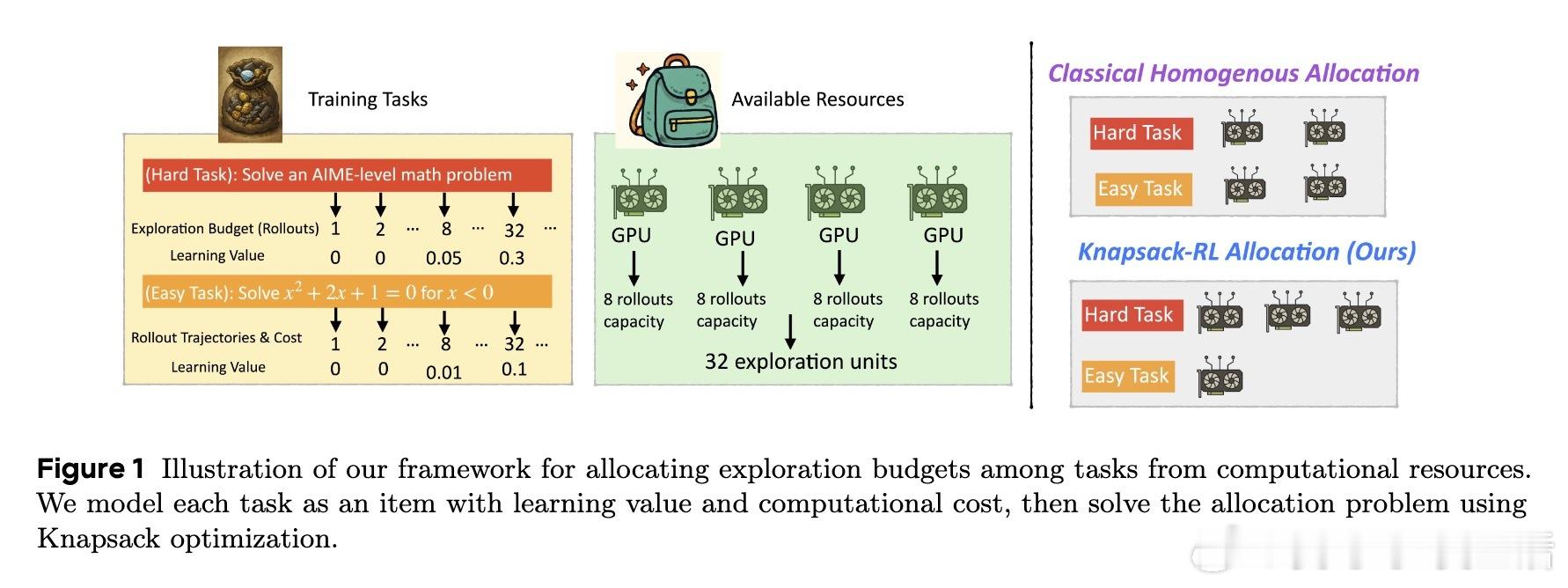
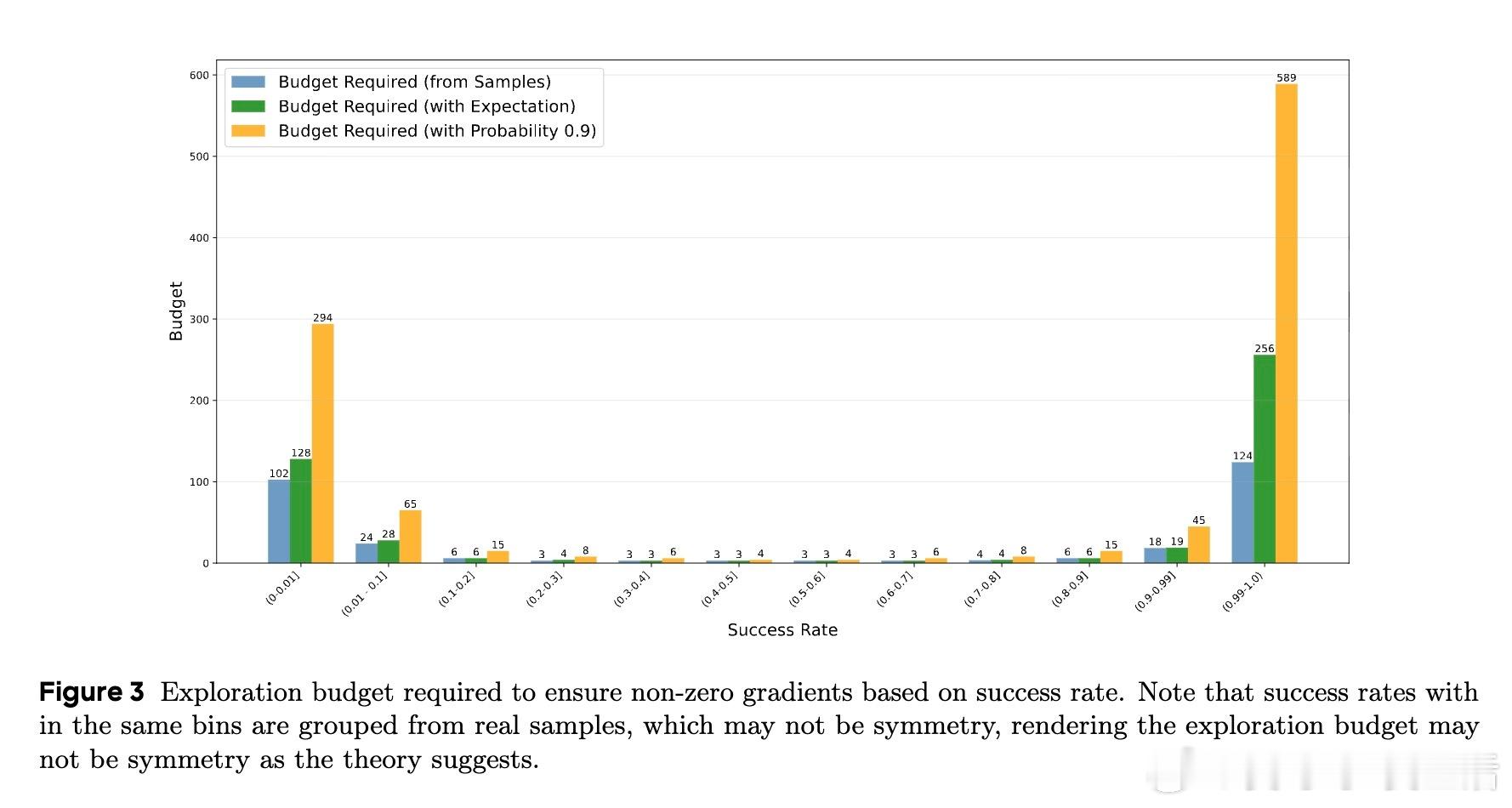
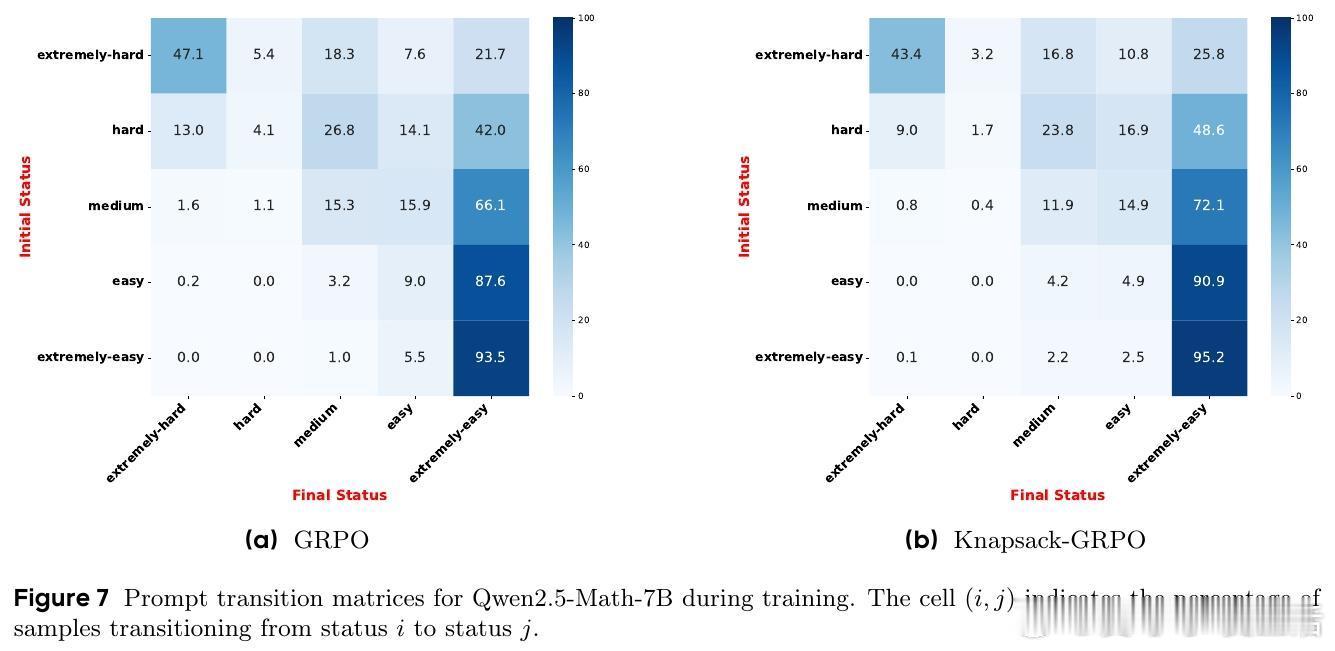
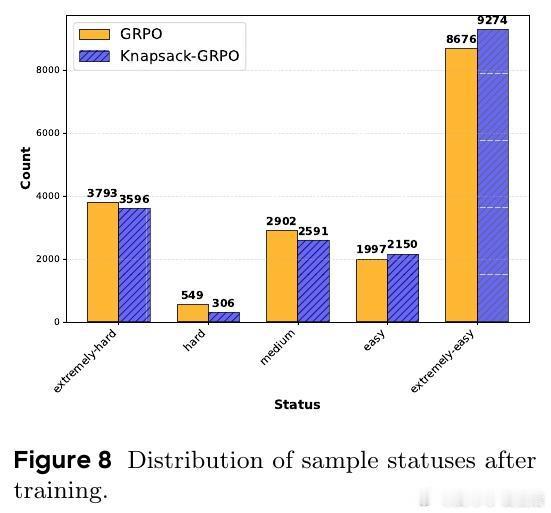
大型语言模型(LLMs)通过强化学习(RL)自我提升,但探索阶段计算成本极高。传统均匀分配探索预算导致“简单任务过度探索,困难任务探索不足”,很多样本无法产生有效梯度,训练效率受限。
🎯核心贡献:
- 创新提出将探索预算分配视作“背包问题”,将每个任务看作具有不同价值和成本的“物品”;
- 设计最优分配策略,动态调整每个任务的探索预算,优先支持更具学习价值的困难任务;
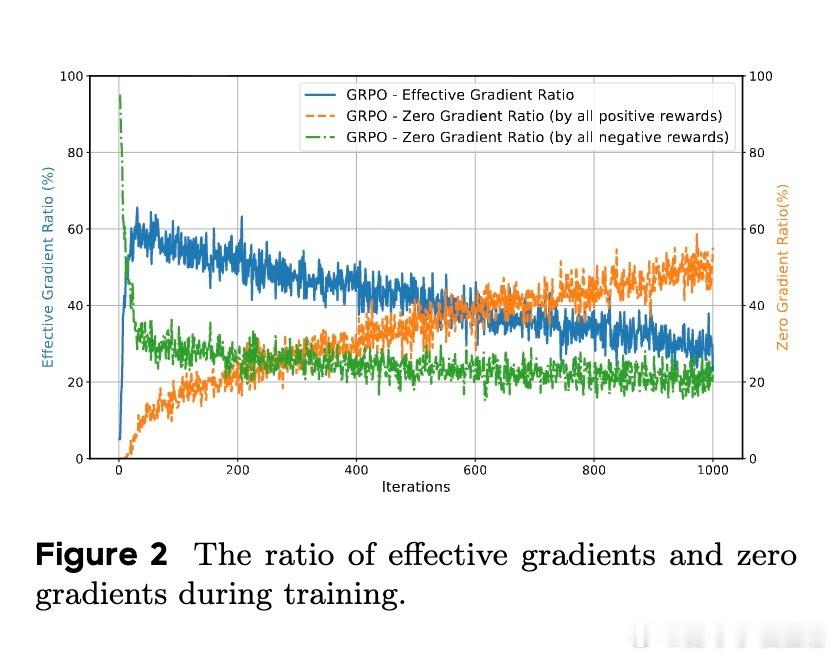
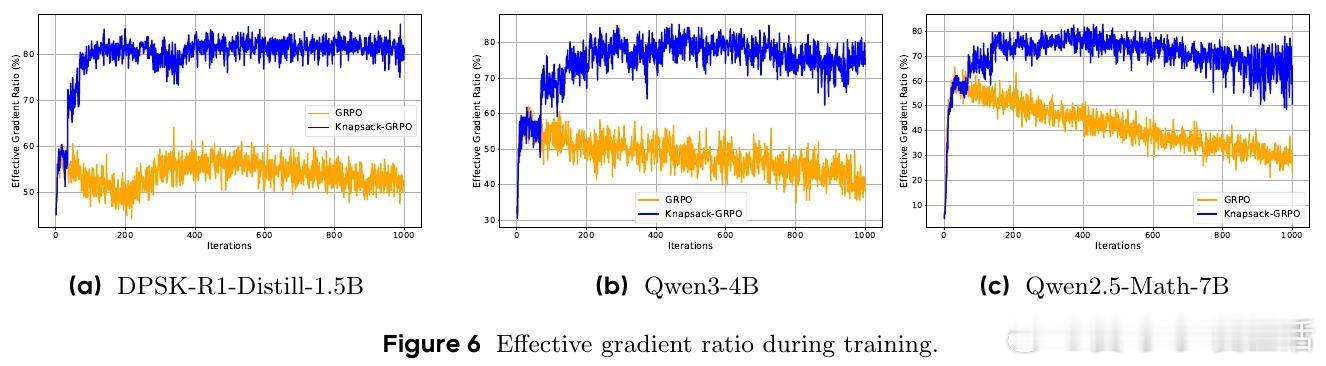
- 该方法在Group Relative Policy Optimization(GRPO)框架下,提升非零梯度比例20%-40%,相当于“免费午餐”,无需额外计算资源即可提升训练效率。
📊实验表现:
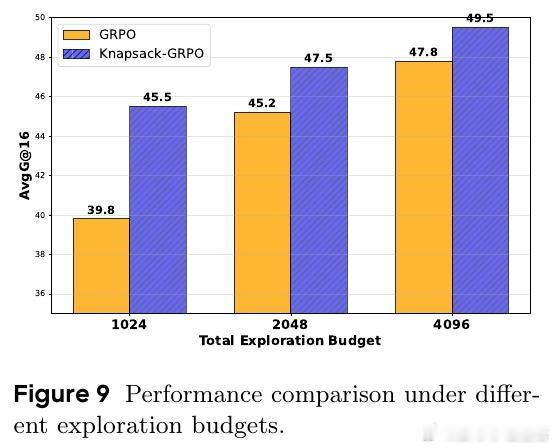
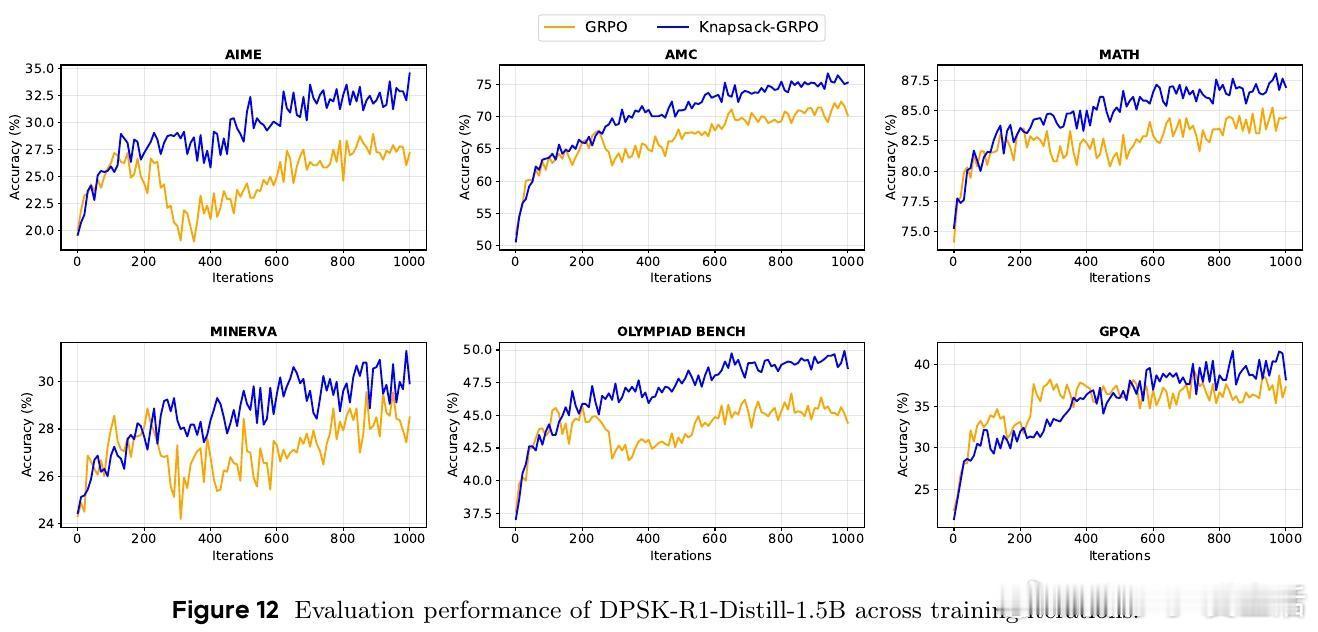
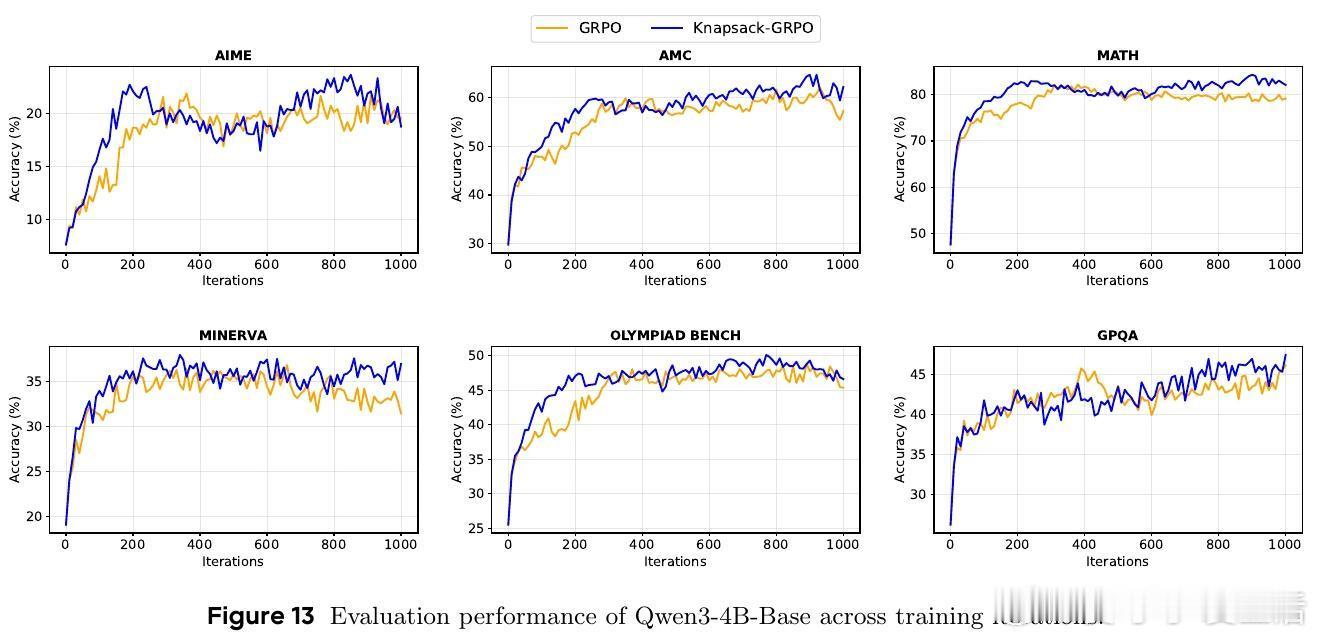
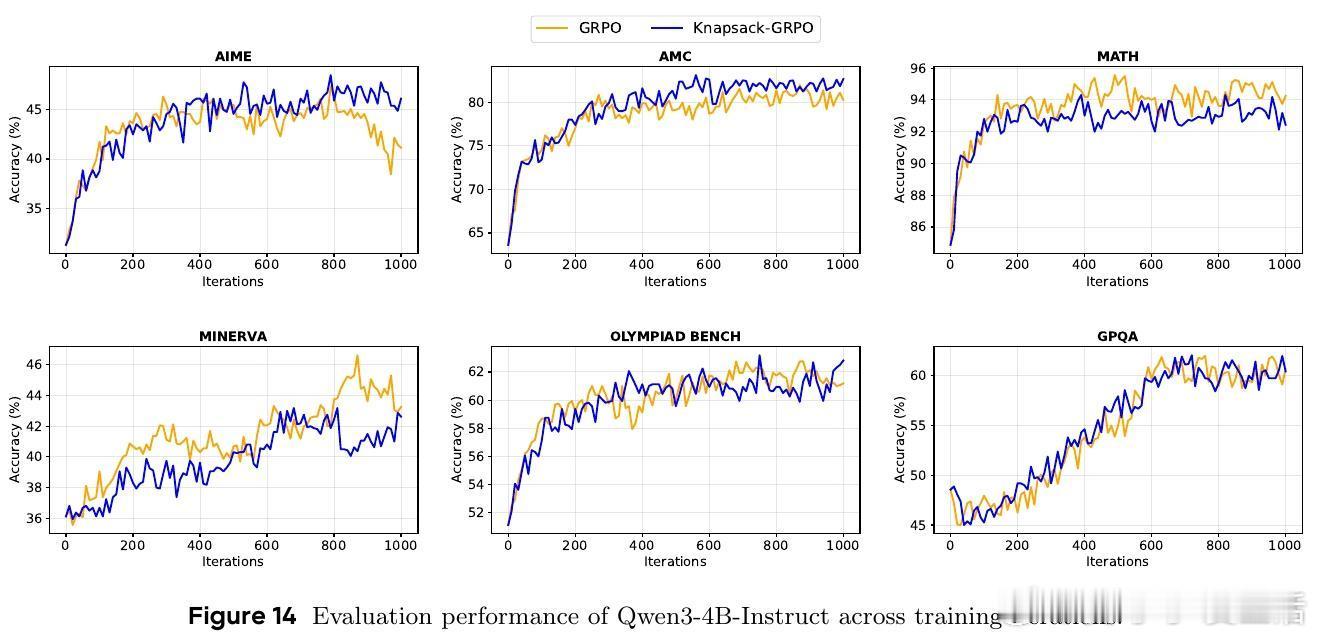
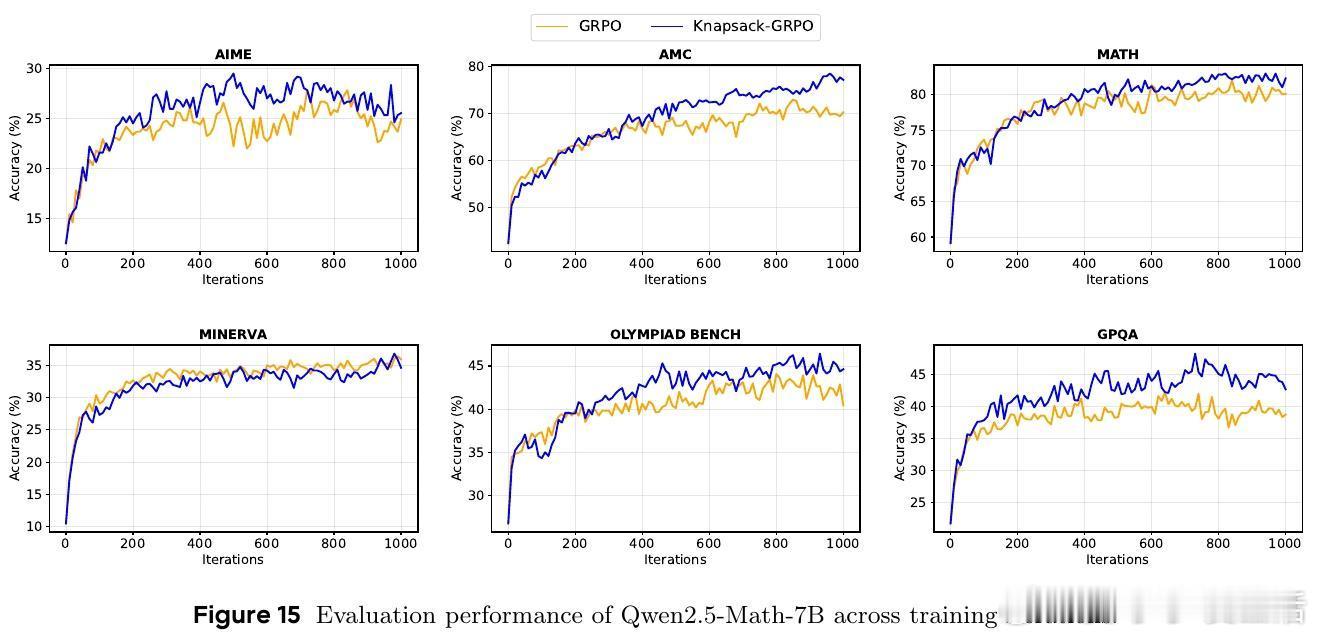
- 多款Qwen系列模型上,平均提升2-4分,特定任务最高提升9分;
- 对比传统均匀分配,达到同等效果的计算资源需求减少约50%;
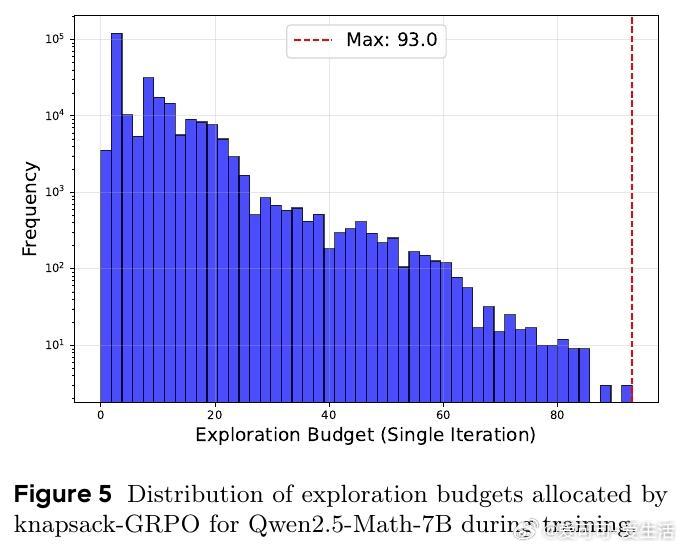
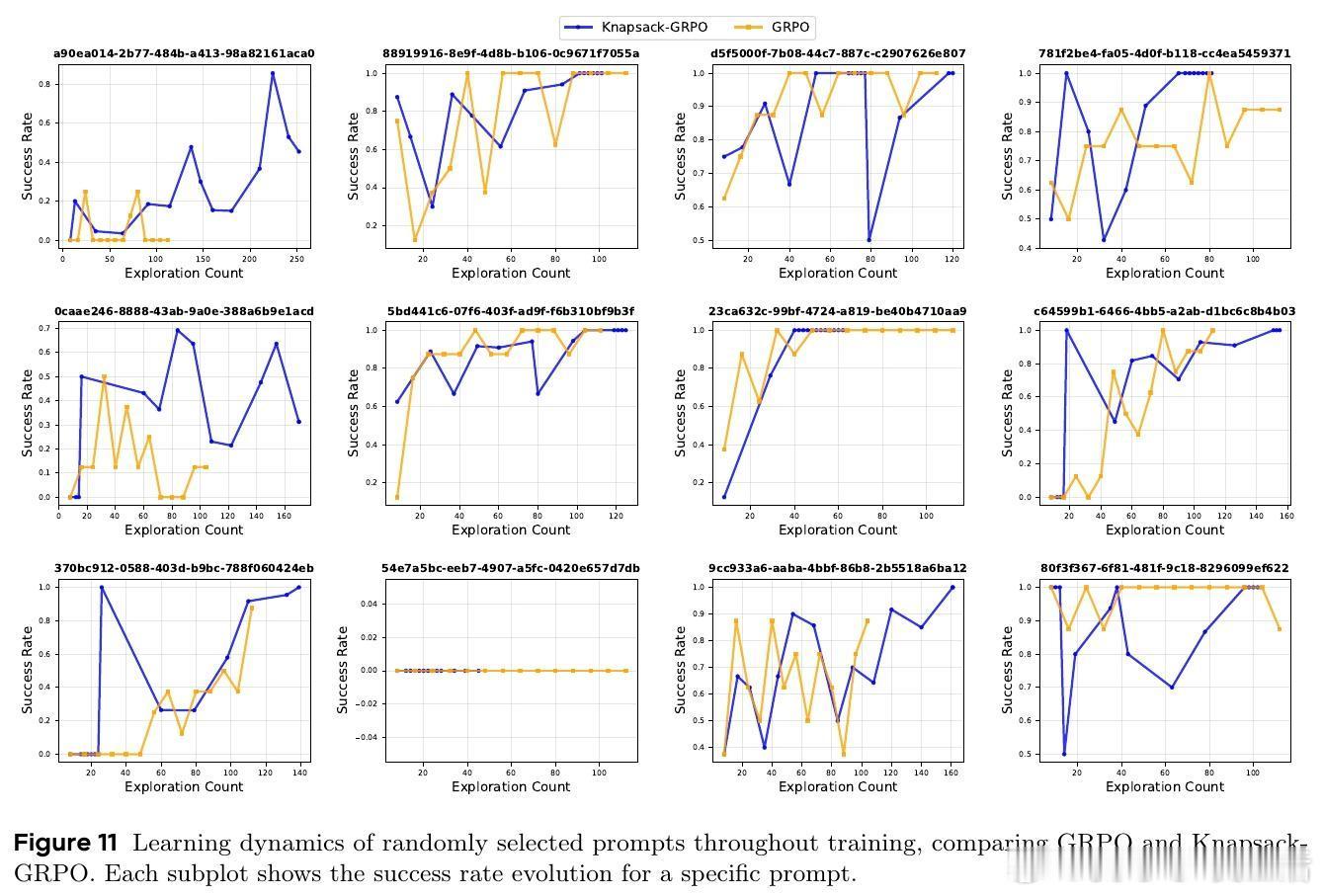
- 动态预算最高可支持单任务93次探索,极大增强困难任务的学习能力。
🔧技术细节:
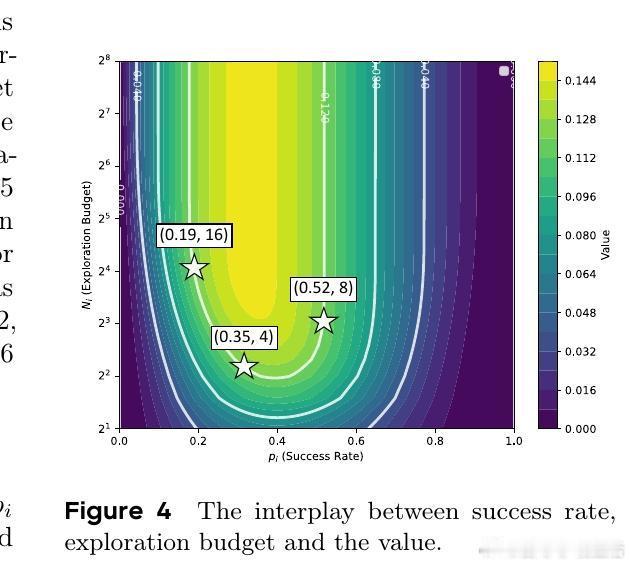
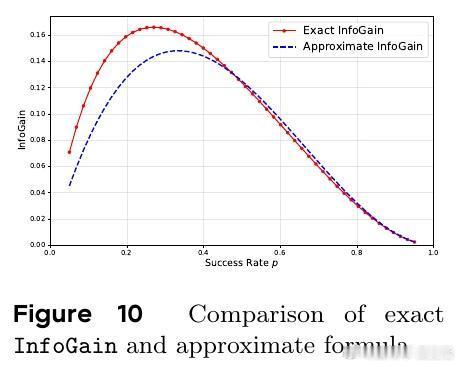
- 价值函数结合任务成功率和信息增益(近似为p(1-p)^2);
- 估计成功率采样上一轮数据,结合动态规划快速求解预算分配;
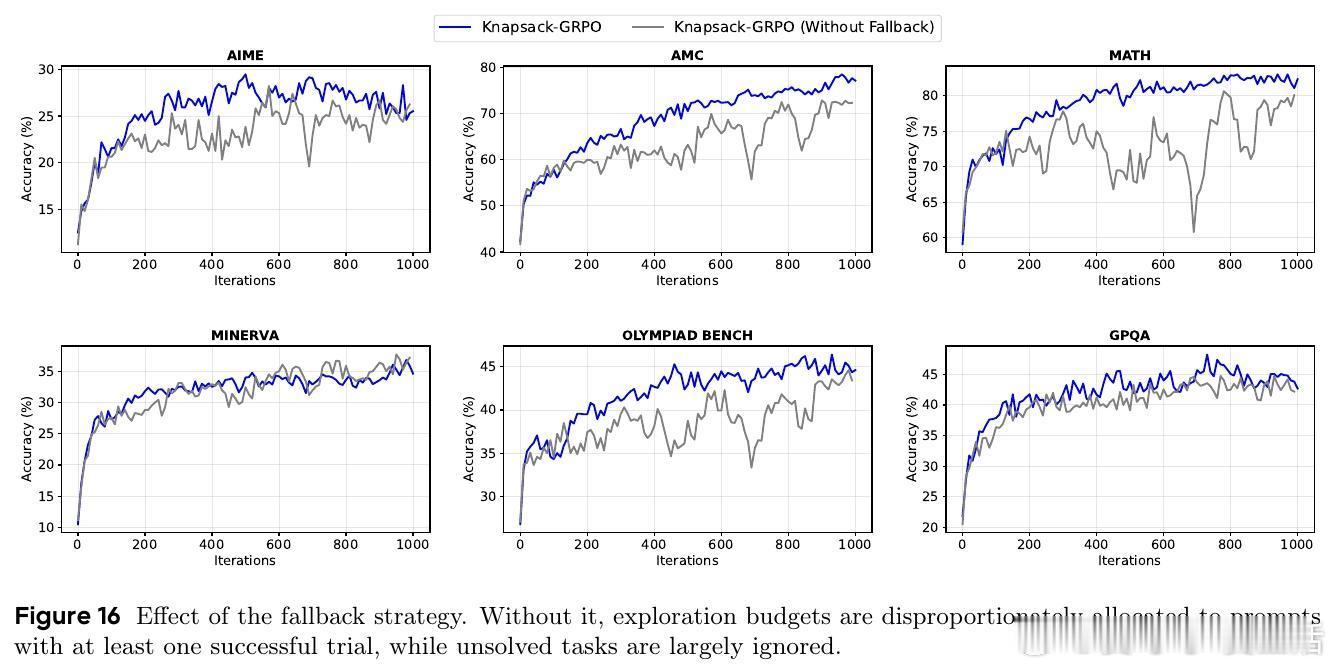
- 配合简单的执行任务平衡策略,兼容现有大规模训练基础设施。
🔮未来方向:
- 融入更丰富的计算成本指标(如token长度、交互轮次);
- 探索更精准的价值函数设计;
- 结合树搜索等高级探索方法,进一步提升难题攻克能力。
结论:本工作开辟了强化学习探索预算智能分配的新思路,解决了任务难度异质性带来的训练瓶颈,为提升LLM后训练效率和能力奠定基础。
论文链接:arxiv.org/abs/2509.25849
强化学习 大型语言模型 资源优化 背包问题 LLM自我提升 机器学习 AI研究