小米辅助驾驶的 Principal Scientist 陈龙在小绿书上做了一个 Ask Me Anything,简单梳理一下他的输出:
- L4 到 L5 突破的最大难点就在 VLA,因为 L5 不限设计运营域要求模型具备像人一样的常识推理能力。
- 小米做辅助驾驶的顶尖人才(他自己就算吧)薪资可以对标北美。
- 小米打算什么时候冲击 L3?快了,效果很惊艳。
- 辅助驾驶的终局肯定是 VLA,端到端只能解决基本的驾驶能力。道路是为人设计的,有很多需要基于认知推理的场景,所以让车更像人一样思考,是通往高阶自动驾驶的关键。
- 目前业界领先的端到端可以解决 90% 的问题,可以看下 fsd tracker 的 top intervention,特斯拉把端到端做到极致了,安全性已经基本上能保证,剩下的大部分问题(比如lane issue)都是需要 VLA 去解决的。
- 辅助驾驶开环有一定的 scaling 表现,但会很快趋近于饱和,真正的闭环控制问题还是需要强化学习。
- 辅助驾驶的强化学习具体来说分 online RL 和 offline RL,online RL 需要一个可交互的环境给 policy 去自由探索,通过定义的 reward 学习到一些安全性和规则和超越人类的行为。Offline RL 通过真实的离线数据,比如接管数据来进一步提升跟用户偏好,安全性方面的对齐。
- 摄像头和激光雷达现在主流还是单独的 encoder,然后特征融合。理论上前融合更好,但是需要很大规模的的预训练。这个方向很值得探索。
- VLA 和世界模型在辅助驾驶领域的前景很好,目前端到端没有长期的记忆、思考和规划能力,VLA 和世界模型很好的补齐了这些能力。
- YU7 比 Tesla 传感器硬件好很多,纯从技术上来讲,Tesla 能实现 L 几,YU7 就可以。(咦,除了传感器,雷总在发布会上也有对比算力,陈龙没对比算力哟。
- 说小米机器人的消息算泄密,小米铁蛋不能说太多。
- 今天的机器人领域很像 6 - 7 年前,还没有 scale up 的数据采集途径,只是有限的采集数据做一些有限的 demo。但现在 AI 进步非常快,离泛化和通用可能没有那没远了。
- 现在小尺寸模型能力还很有限,但 VLA 能达到的上限会非常高。
- 融合肯定比单一模态的系统性冗余要高,当 MPI 到几千几万时就可以体现出多模态的重要性了。
- 视觉语言模型特征提取能力差、局部细节丢失的问题需要把 VL 的对齐做得特别好,现在除了堆数据和表征学习还没有其他更好的办法。
- 端到端迭代主要靠数据闭环,很重要!算法反而没那么重要。
- 现在趋势是轻图,但(图)肯定会以某种形式长期存在来作为模型的先验,就像人一样如果有精细的道路级导航开车会轻松很多。
- 小米辅助驾驶部门是双休!
- 对于 VLA,直接用预训练的 VLM 是泛化性最好的,bev feature 融合可以增加空间理解能力,需要构造语言数据做 sft,但会一定程度上伤害通用能力。我们也在探索如何不损失通用性的前提下提升空间理解推理能力。
- Transformer还是现在最好的网络架构,只是自动驾驶和机器人涉及到反馈控制的训练方式需要创新,以及 VLA 如何解决自回归效率问题。
- 1. VLA 也是端到端,只是可以利用语言模态进行推理从而降熵增加确定性;2. 语言是必须的,参考猩猩学开车也能学会,但不理解这个世界没有语言推理能力终究会出各种问题;3. 4D 毫米波雷达是一个纯视觉很好的冗余,当达到几千几万 MPI 时就会意识到冗余的重要性了。
- 纯视觉到后期肯定会有一些问题,例如光线不佳、雨后地面反光等等,因为人在这些情况也经常出错。等到几万 MPI 时候就会发现传感器冗余的重要性。
- 对于解决自动驾驶,无论多少数据都不可能充足,世界是非结构化的,总会有没有见过的场景出现,而且关键是你不知道有哪些没有见过的场景也不知道多少数据会够,所以常识推理能力是必须的。
- 4D 毫米波雷达是对纯视觉方案很好的补充,能提供速度和高度信息,可以作为关键的冗余感知,提升系统的全天候能力和安全性。跟普通雷达比,对路牌,低矮障碍物等检测能力更强一些。
- VLA 要解决需要思考推理的场景。比如临时的施工区、交警的复杂手势、非典型的交通行为、非典型到路线等等,这些场景由于数据很少,端到端并不能学习得很全面。
- 小米内部机器人部门资源给得挺多的,后面潜力非常大。
- 强化学习对于自动驾驶很有用,RLHF 可以对其用户习惯偏好,online RL 提升安全性和 ood 状态的恢复能力。可以作为模仿学习后的微调,也能作为 RL 预训练,但还在探索阶段。
- 传统规控是安全的基础,长期模型还是要结合传统规控兜底的。
- 如何解决辅助驾驶的 cornercase,data-driven 是核心思路,通过数据挖掘找到问题根源,然后针对性地去迭代优化模型。数据有限的情况下就需要对模型做一些增强,比如引入深度等 inductive bias。基模肯定会探索,无监督预训练基模可以得到很好的表征提升模型学习效率,语言模型基模拉高整体的认知、推理能力。
- 自研(辅助驾驶)芯片成本和优化会好很多,激光雷达我个人认为成本足够低的情况下是一个对视觉很好的冗余(也有可能会被 4D 毫米波雷达替代)。技术上重点是要能做到前融合端到端,传感器的多少是成本和安全性的 trade-off。
- VLA 路线主要提升长尾场景的推理能力,更加注重 high level 的规划。世界模型现在讲的比较多,但没有一个明确的思路到底是作为预训练方法,或是模拟器配合 RL 训练,还是推理时预测下一个状态做 Latent Action Model 或 MCTS。本质来讲 VLA 也都是可以使用这些方式来训练的,所以可以结合起来搞不冲突。
- 很多人感觉现在自动驾驶是端到端的数据工程问题,只要 scale up 数据模型就行,但同时也还是个科学问题,模仿学习还是有上限的,真正学会像人一样开车还需要学习到:1)闭环反馈控制能力,2)像人一样思考的能力。这就需要 WM+RL 和 VLA 的探索了!
- 世界模型解决 low level motion 的问题,VLA 解决的是更 high level 的决策。
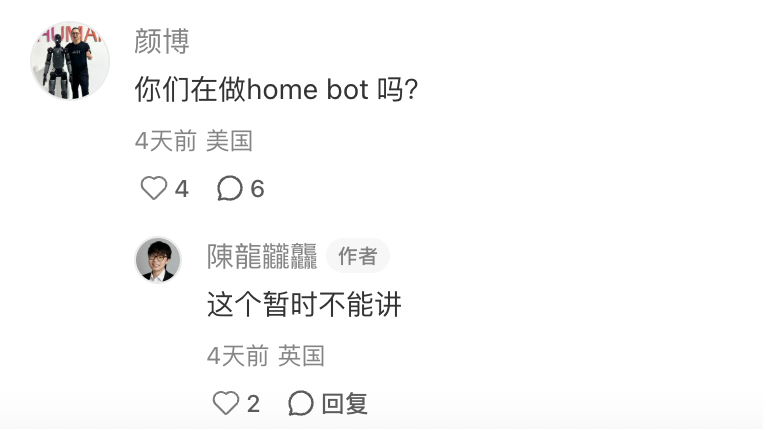
就不一一截图了,放一个最可爱的问答,「这个暂时不能讲」,生动表明陈龙同学没有经过公关部的培训。😄