[LG]《GradES: Significantly Faster Training in Transformers with Gradient-Based Early Stopping》Q Wen, X Zeng, Z Zhou, S Liu... [Boston University Metropolitan College] (2025)
GradES:基于梯度的早停策略,实现Transformer训练显著加速与性能提升
• 传统早停依赖全模型验证损失,计算开销巨大,尤其对大规模Transformer,验证推理耗时限制了验证频率,导致过拟合风险与效率权衡。
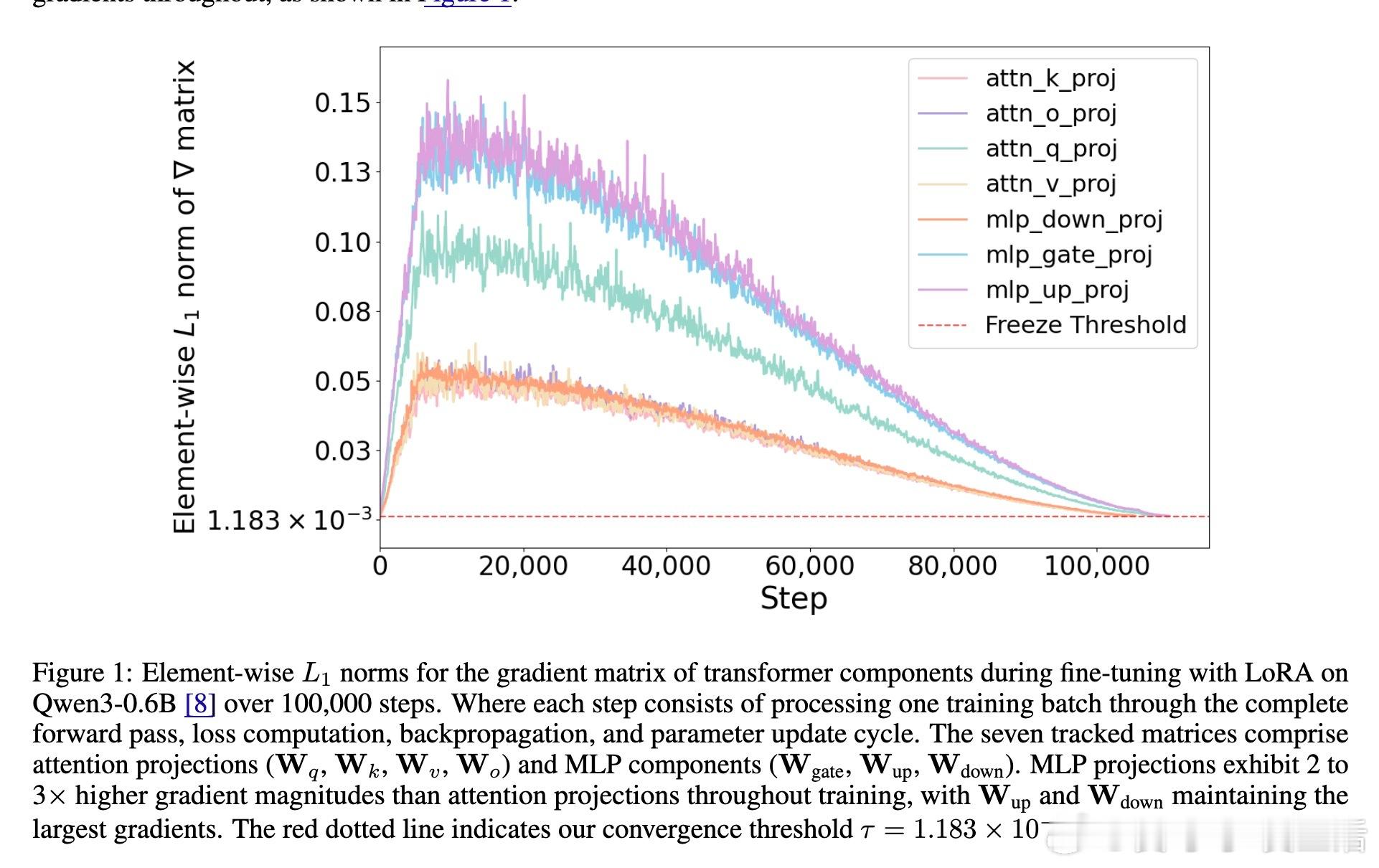
• GradES创新性地监控Transformer内部各权重矩阵(注意力查询、键、值、输出投影及MLP层)梯度幅值,依据梯度范数阈值τ动态冻结已收敛组件,避免不必要的更新和验证,训练时间加速1.57–7.22×。
• 通过组件级早停,GradES有效防止过拟合,提高泛化能力,平均准确率提升约1.2%,且兼容主流优化器(Adam、SGD)及参数高效微调方法如LoRA。
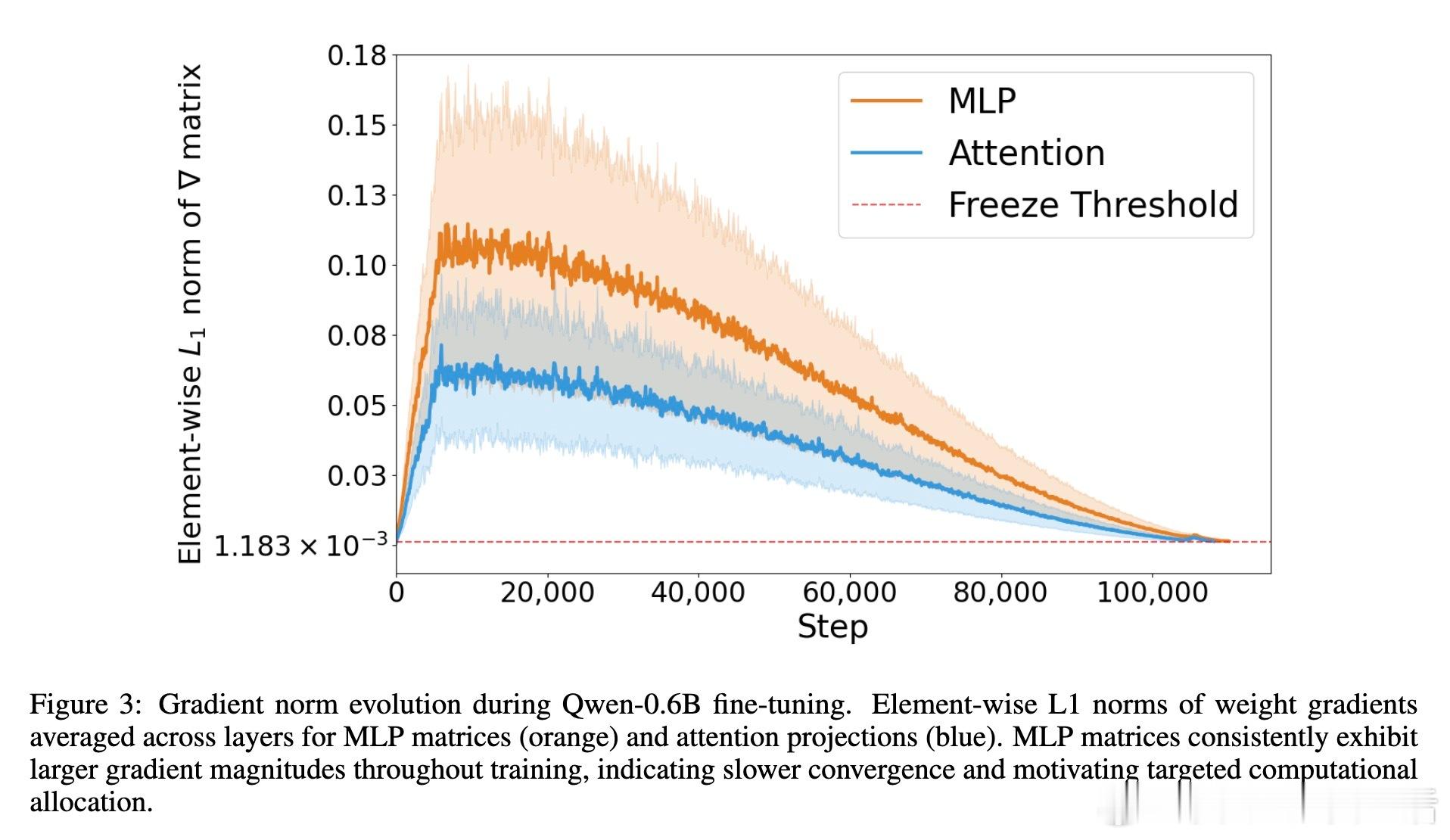
• 关注不同组件收敛差异:MLP层梯度幅值持续较大,收敛更慢;注意力投影矩阵收敛更快,优先冻结,体现细粒度调控的优势。
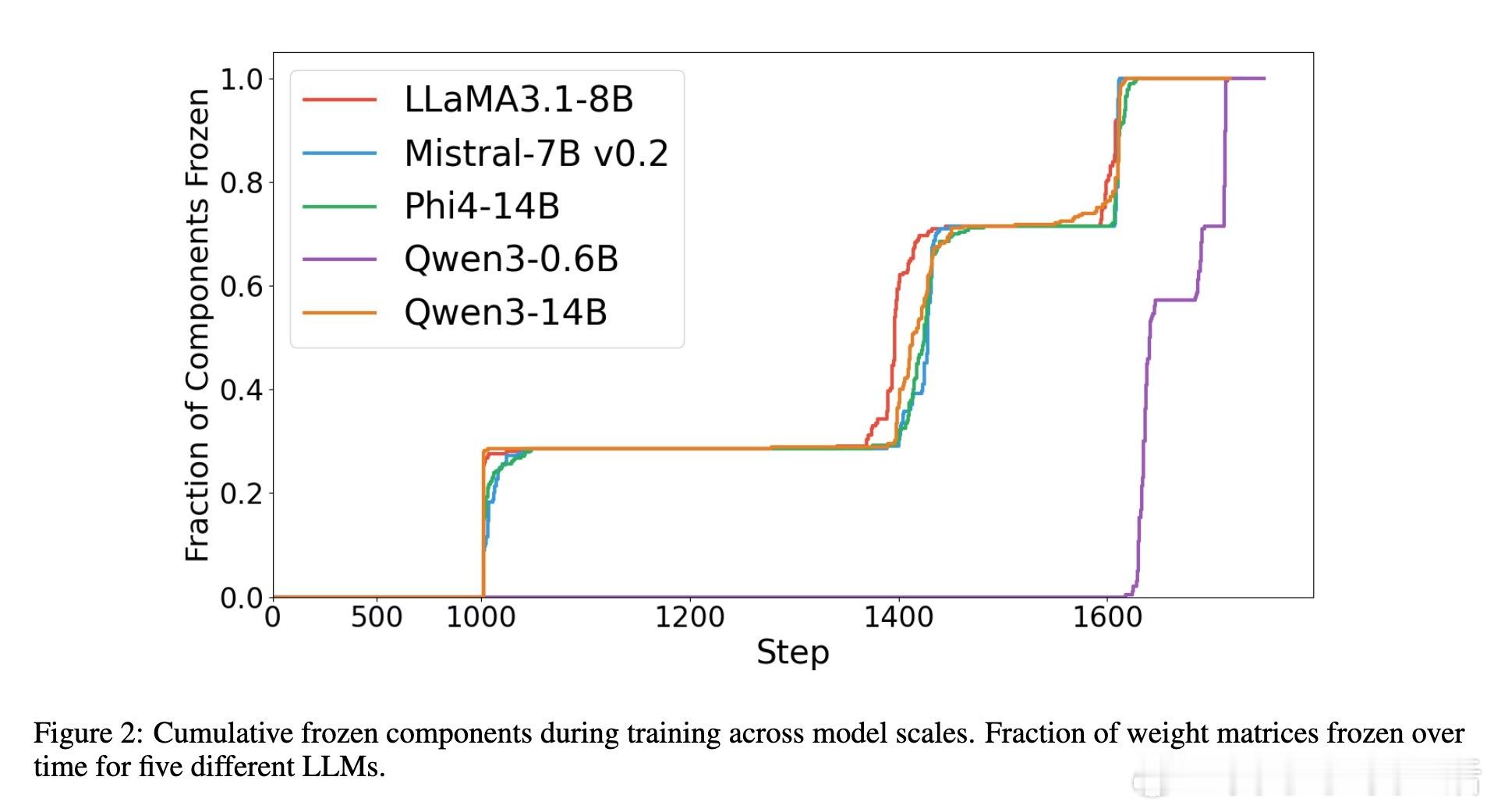
• 实验覆盖5款主流大模型(0.6B至14B参数量),8个语言理解基准,证明GradES普适性和稳定性;结合LoRA实现极致训练效率(如Qwen3 0.6B训练时间缩短至14%)。
• 理论分析支持GradES收敛性及阈值选择,开源代码可复现,易于集成到现有训练流程。
心得:
1. 异构组件的梯度动态揭示了Transformer内部训练的不均衡性,精细化早停策略能显著提升训练资源利用率。
2. 传统早停的“黑白决策”忽视了局部收敛差异,GradES通过矩阵级冻结实现训练的连续正则化,避免过拟合同时保持学习动力。
3. 将梯度信息复用为收敛判据,省去昂贵验证步骤,适合资源受限环境及大规模模型训练,推动训练范式革新。
详见🔗arxiv.org/abs/2509.01842
Transformer大模型训练早停梯度优化模型微调人工智能