大模型智商榜单OpenAI统治大模型IQ榜
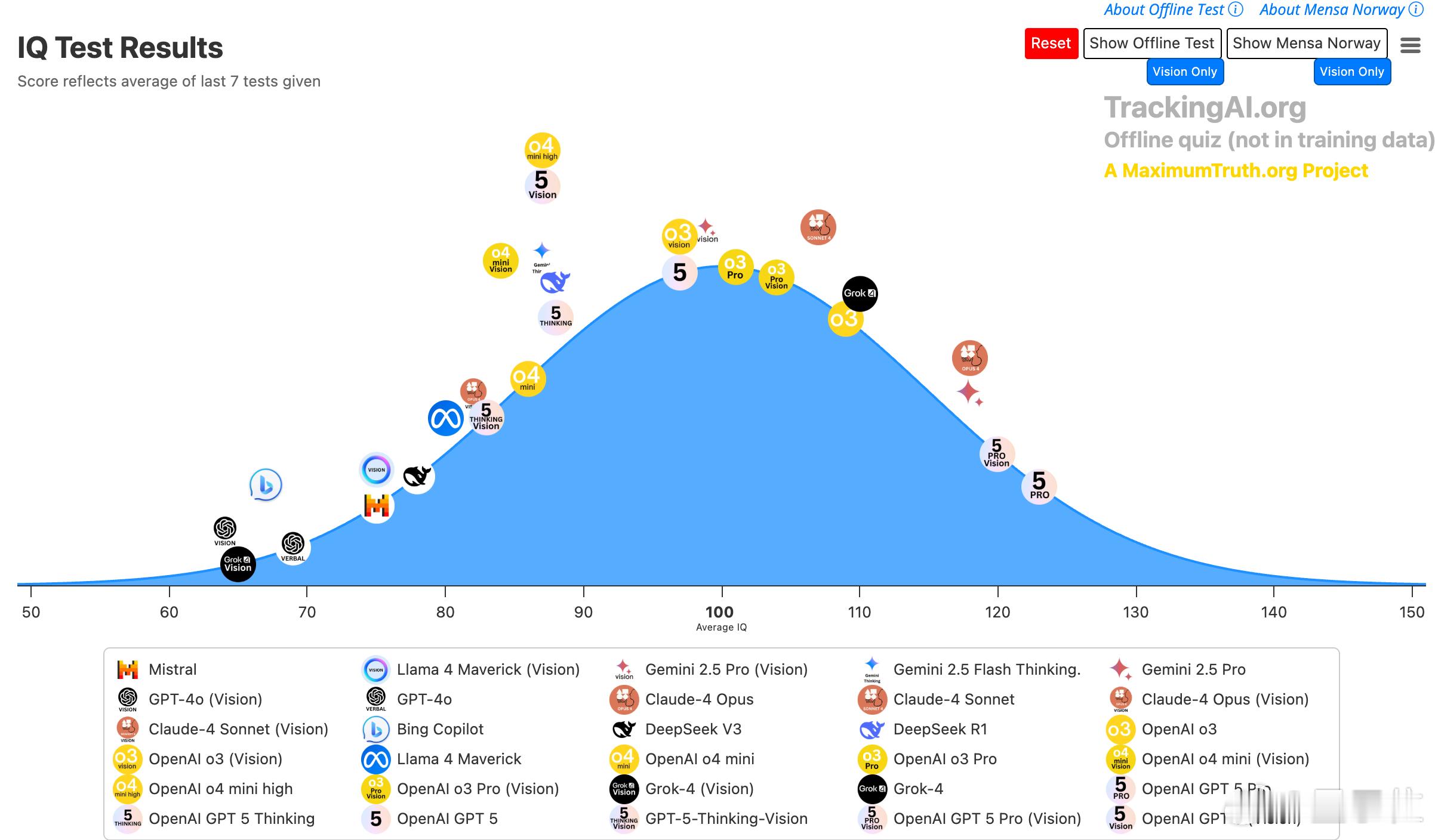
TrackingAI做的大模型智商测试显示:OpenAI系列几乎统治榜单,多款GPT-5系列和o3/o4变体位于高分段。
该站每周对18个Verbal与12个Vision模型做测验,离线得分以最近7次测试平均值为准,题目多来自MensaNorway等非训练集来源。
榜单要点:
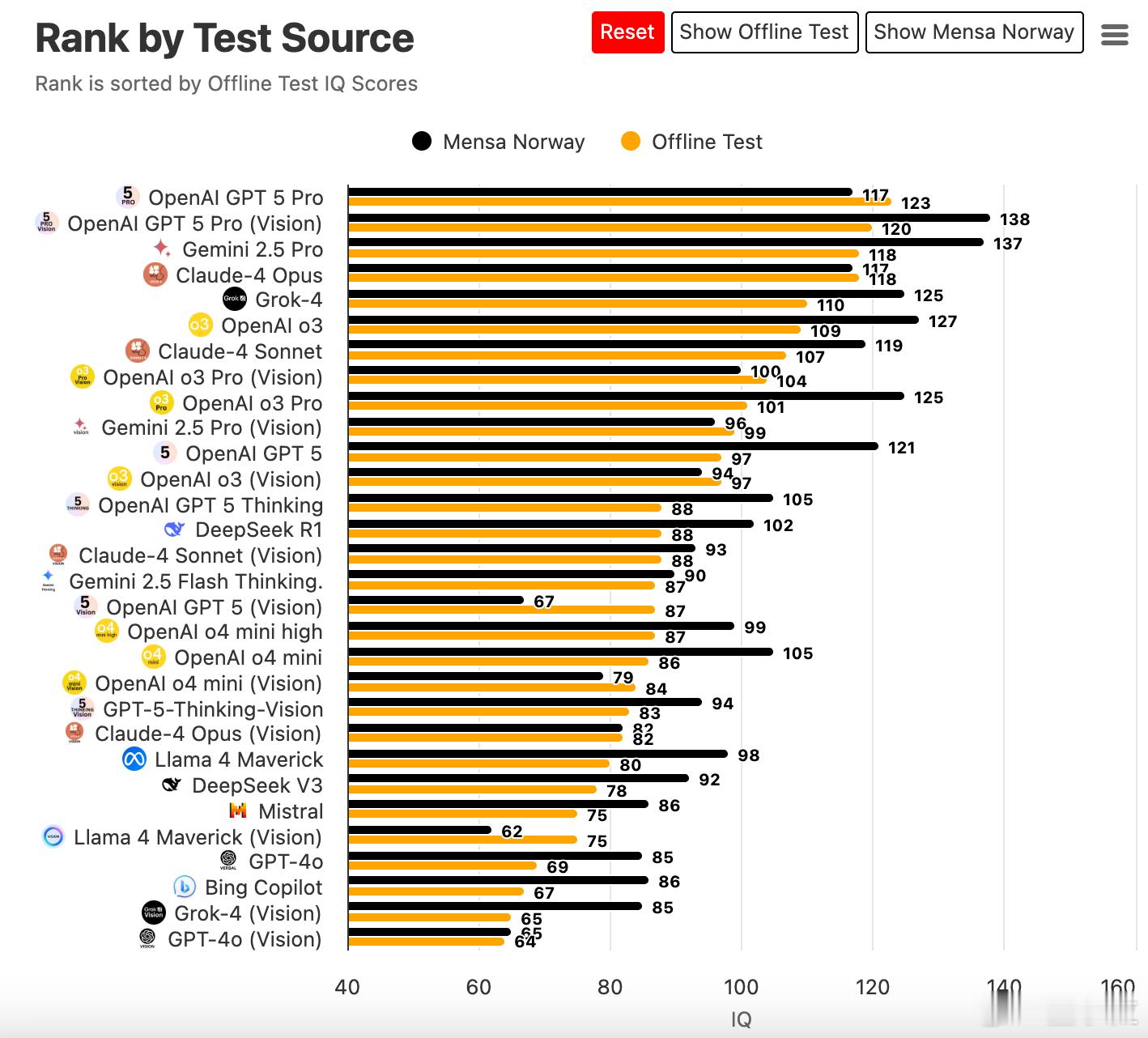
1. 顶尖模型:GPT-5Pro(Vision)--IQ138、GPT-5Pro--IQ137、Gemini2.5Pro--IQ127、Claude-4Opus--IQ125、Grok-4--IQ125。
2. 多模态强势:GPT-5系列在文字和视觉题上都表现稳定,说明多模态推理已接近文字模型水平。
3. 中端表现:o3系列和部分OpenAI小型号稳定落在100左右;Meta Llama4Maverick和Mistral等多位于平均线下。
4. 测评取向差异:MensaNorway偏语言逻辑,离线题更考通用推理和视觉规则,导致部分视觉模型分数下滑。
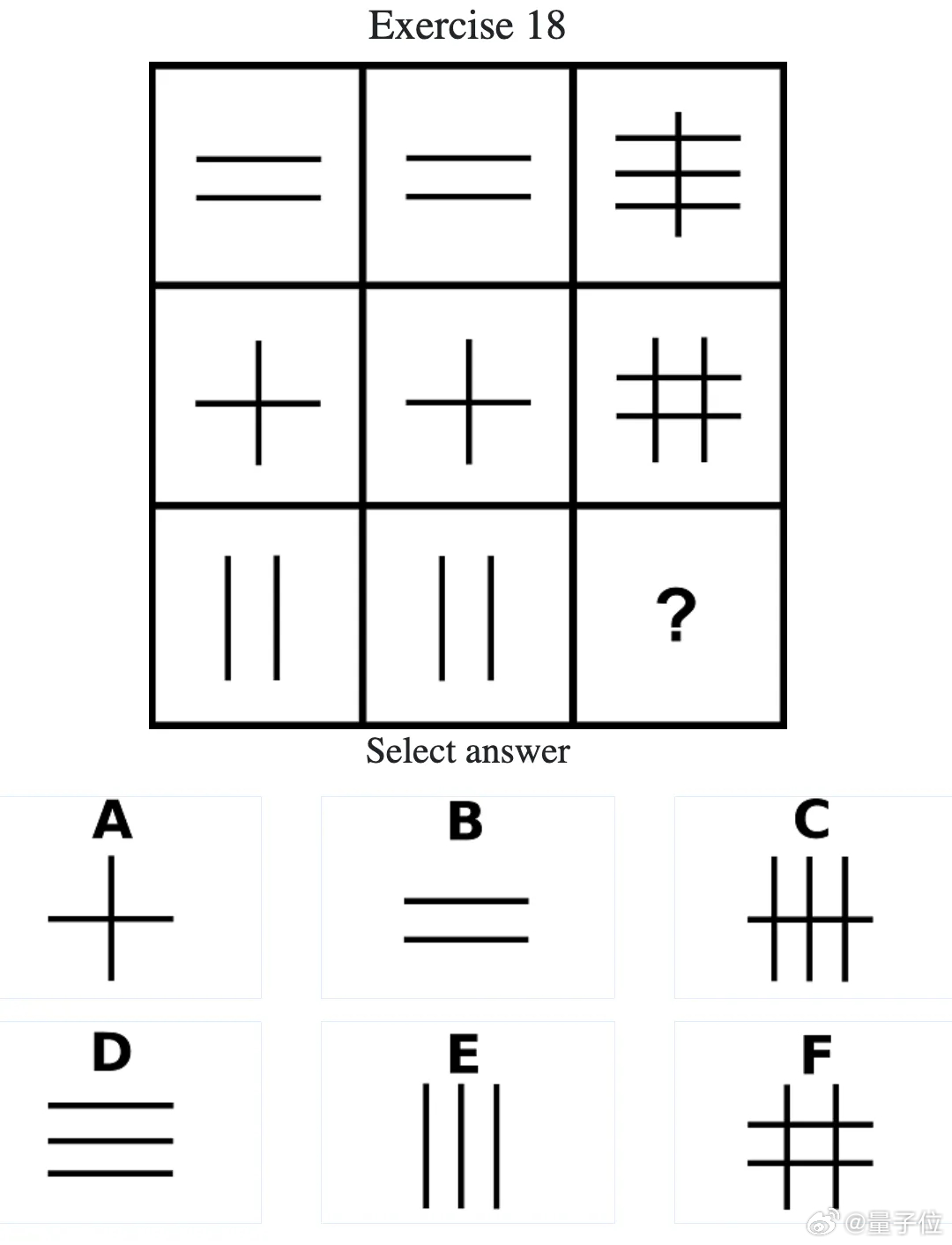
测试题目举例如下:图3
1、题型:找规律,3×3图形矩阵,右下缺一项。
2、观察规律:每行是同一方向的线条主题且数量有递增趋势。第一行以横线为主,右侧由2条横变3条横;第二行由简单十字到右侧变为3横3竖的网格;第三行以竖线为主,左中各为2条竖线,因此右下应为3条竖线。
3、正确选项:E(三条竖线)。
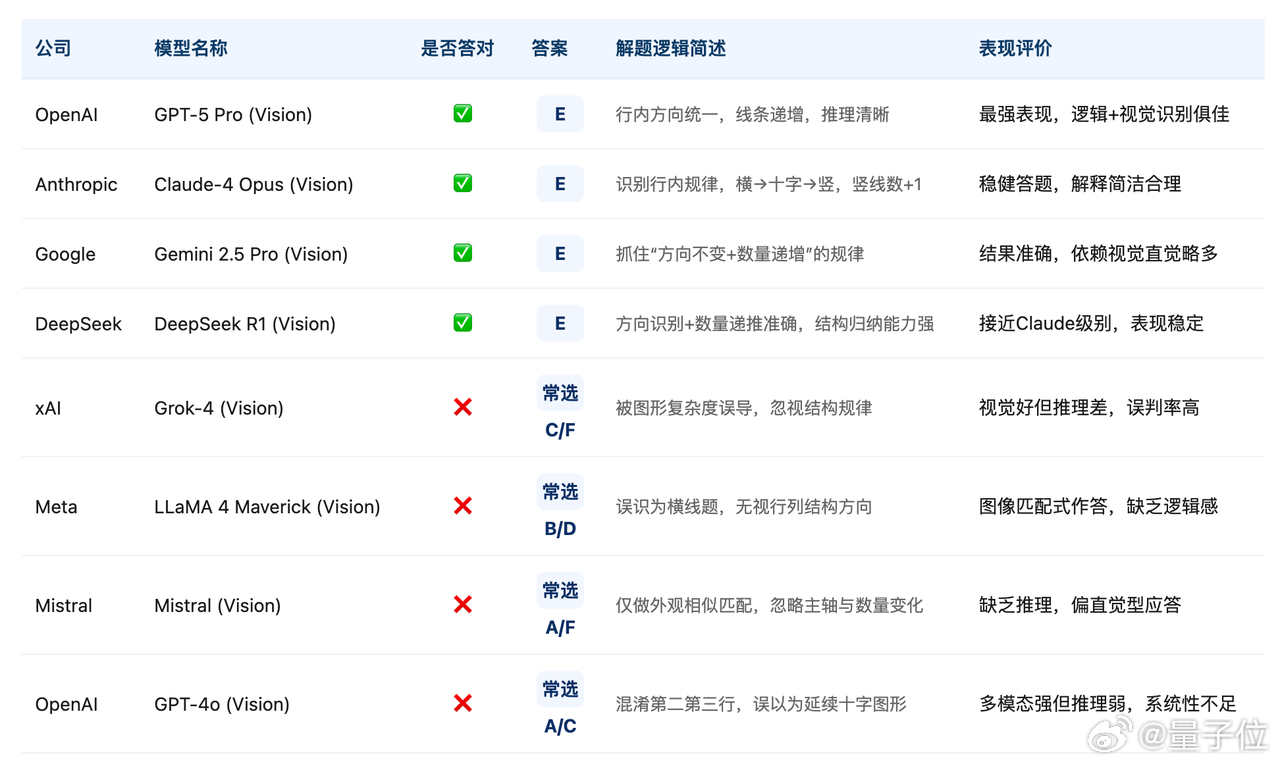
各大模型在此题的表现:图4
· GPT-5Pro(Vision) 答对,能给出“方向+数量递增”的解释,推理清晰。
· Gemini2.5Pro(Vision) 答对,归纳出“每行主题一致并递增”,解释相对简洁。
· Claude-4Opus(Vision) 答对,兼顾方向与数量两个维度的分析。
· GPT-4o(Vision) 偶有错误,常选A或C,说明对行内递增规律把握不足。
· Grok-4(Vision)、Llama4Maverick、Mistral 等视觉模型多有错误,倾向于按图形相似度直接匹配而非推理数量规律。
总体来看,高分模型不仅在表象识别上更稳定,还能把“方向”和“数量”这种抽象规则抽出来并外推;低分模型更容易被视觉细节拖累,缺少系统化的规则归纳能力。
榜单地址:www.trackingai.org/home