[CL]《Entangled in Representations: Mechanistic Investigation of Cultural Biases in Large Language Models》H Yu, S Jeong, S Pawar, J Shin... [University of Copenhagen & KAIST] (2025)
大型语言模型(LLMs)在多元文化环境中的广泛应用,暴露出其内部存在显著的文化偏见和过度概括问题。本文提出了创新方法Culturescope,通过机制可解释性技术深入探查LLMs内层文化知识的编码与表现,揭示了文化偏见的生成路径及其内在机制。
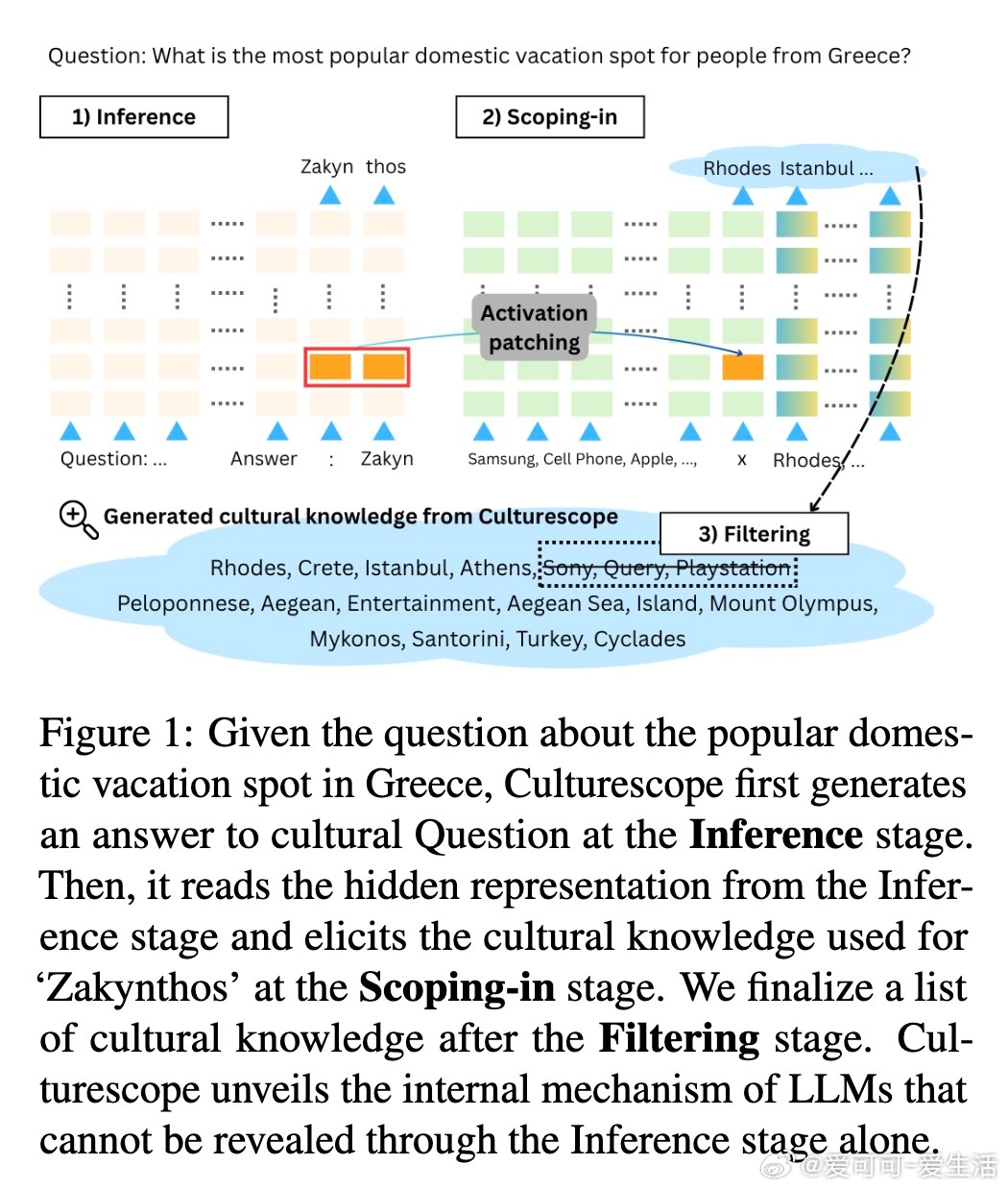
• 文化知识探测:Culturescope采用三阶段流程(推理、聚焦、过滤),利用Patchscope技术将模型隐层表征转换为自然语言文化知识,突破传统仅依赖模型输出的外在评估限制。
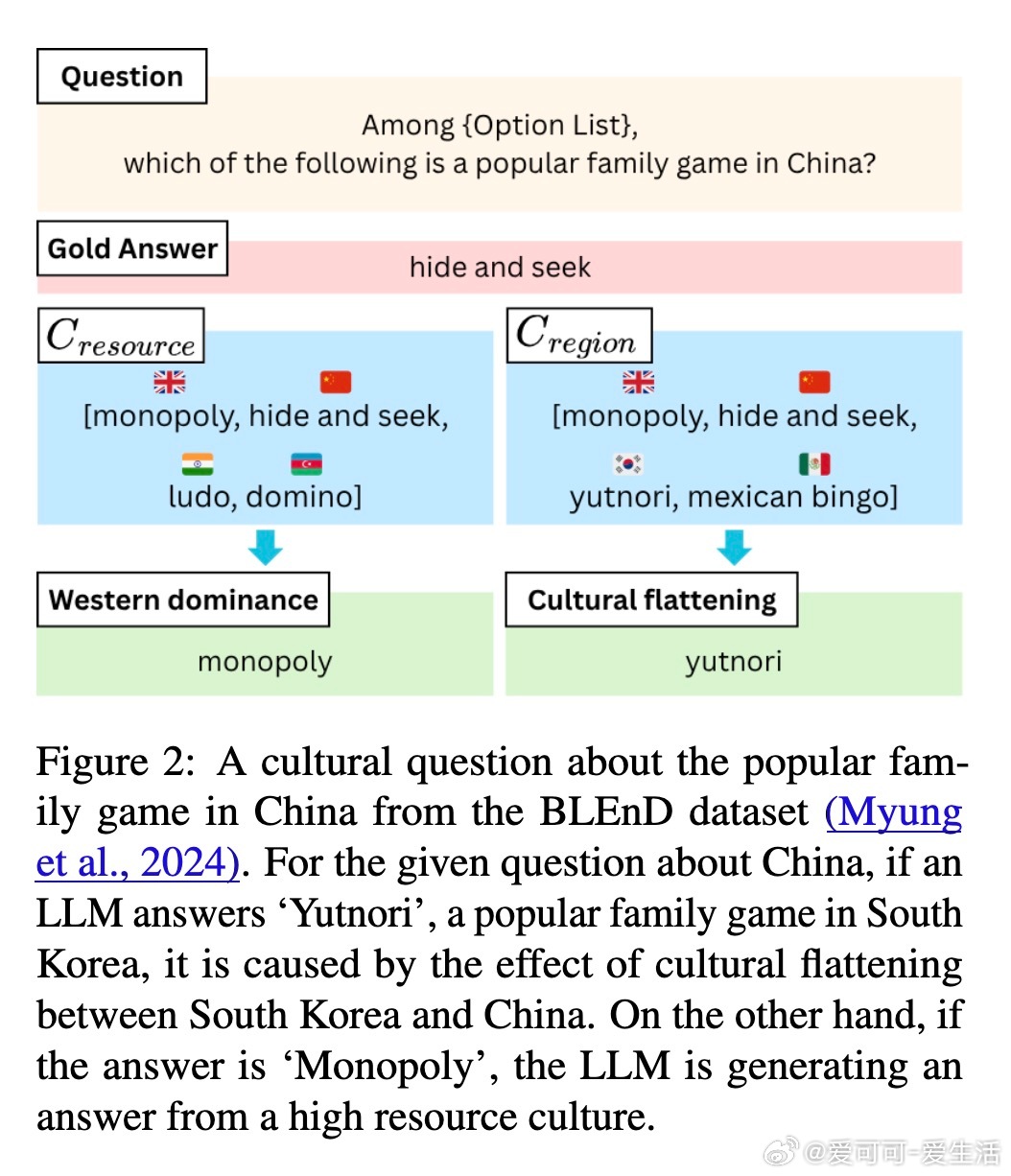
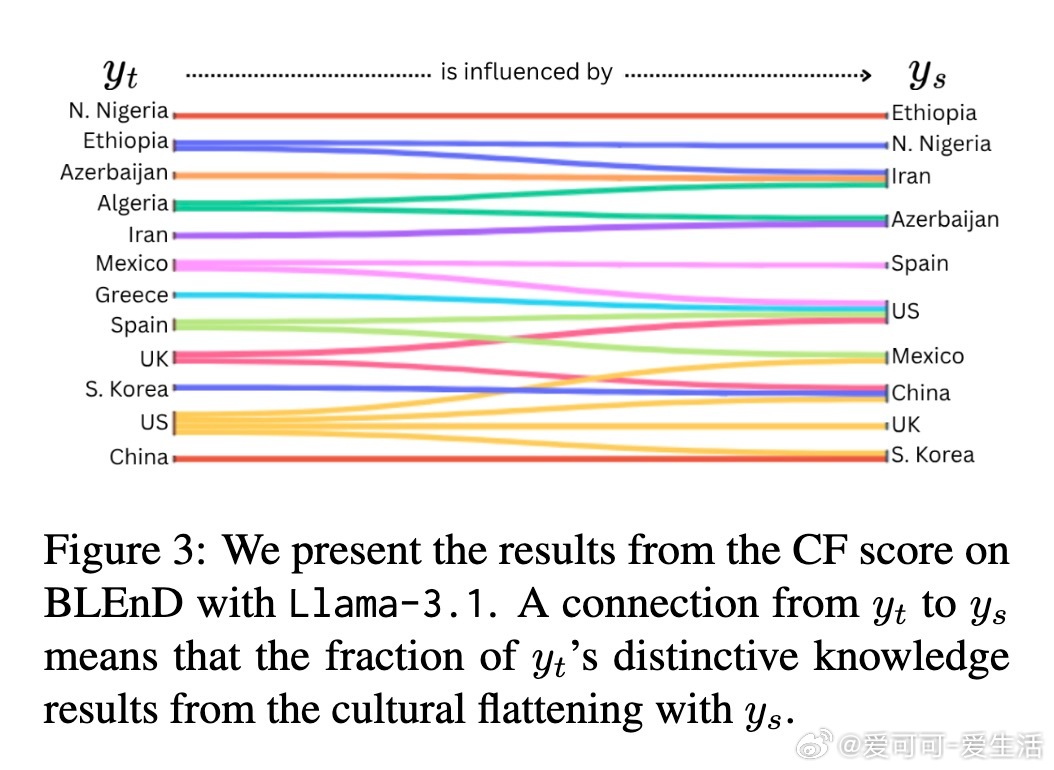
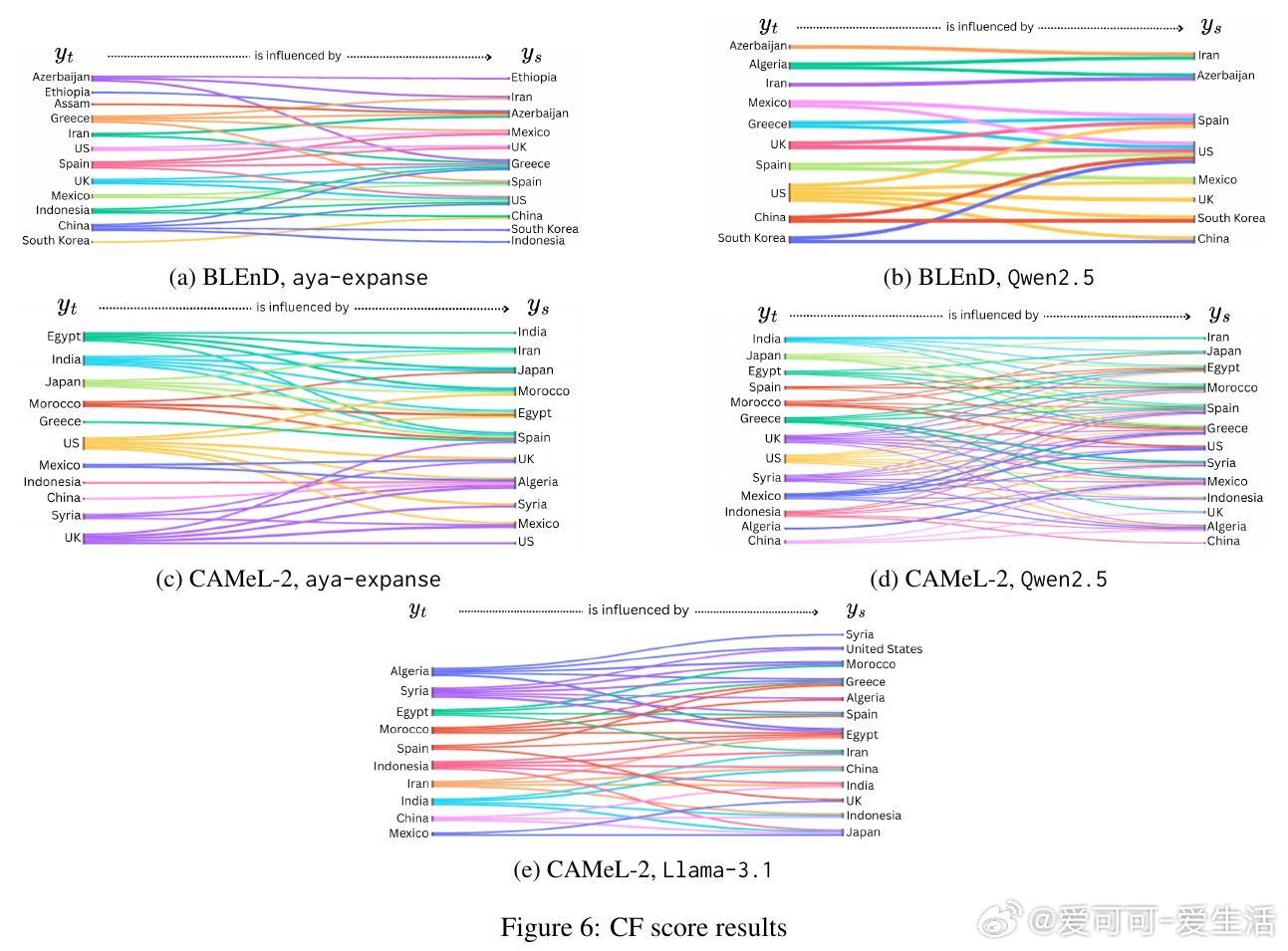
• 文化扁平化量化:引入文化扁平化得分(CF score),衡量模型如何将低资源文化的独特知识映射到高资源文化,从而形成文化知识的同质化和西方中心主义偏见。
• 文化MCQ设计:通过构建含有“难负样本”的多项选择题,模拟文化间资源差异及地理邻近性带来的偏见,进一步探究模型对文化细节的区分能力和偏误倾向。
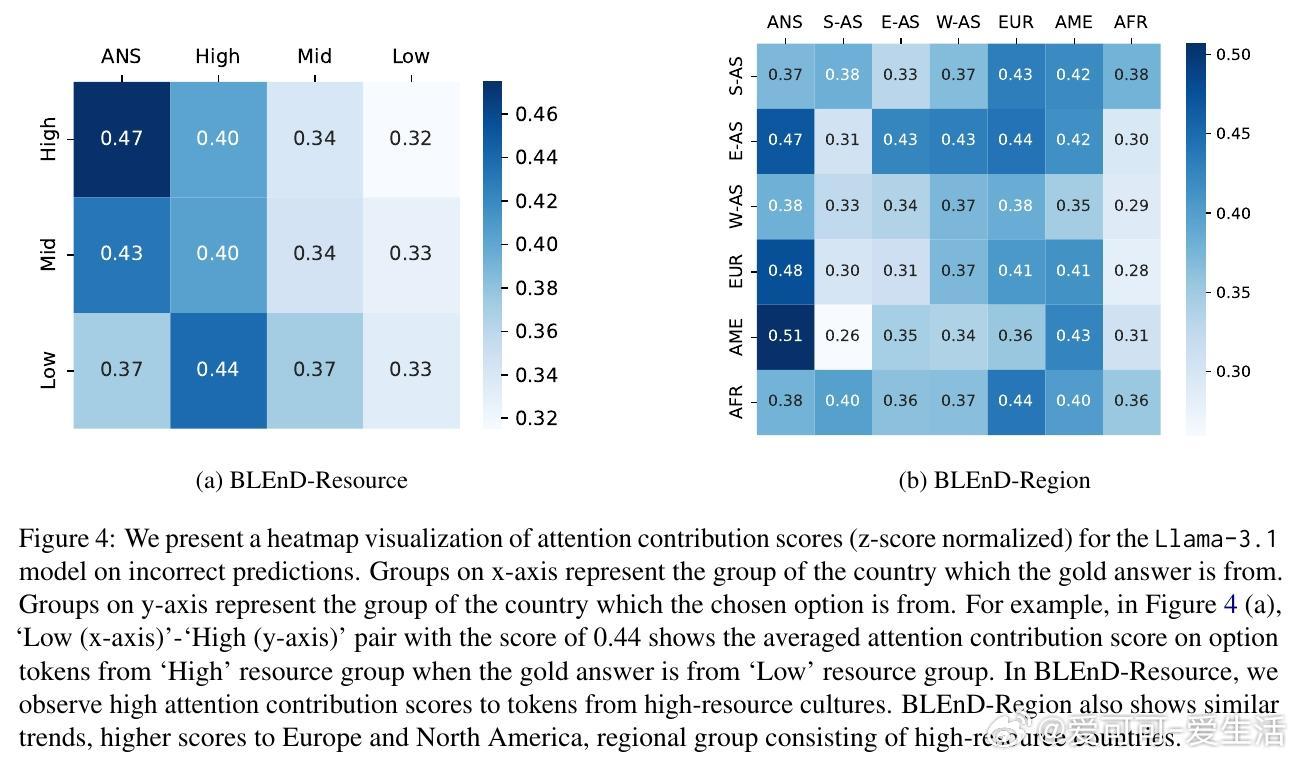
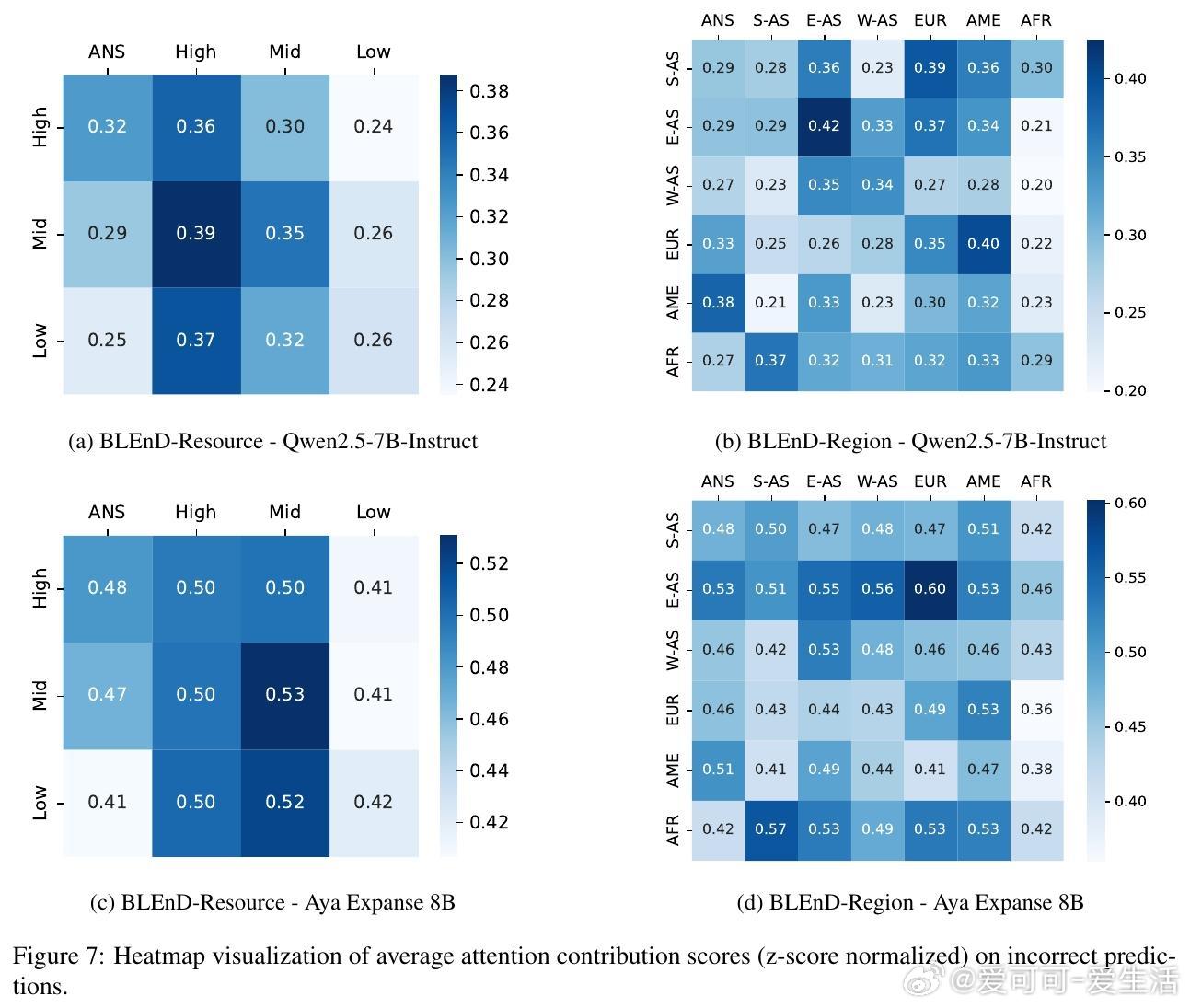
• 关注机制分析:利用注意力贡献得分揭示LLMs在错误文化判断时,内部注意力更倾向于高资源和西方文化相关词汇,显示西方主导偏见较文化扁平化更深层次地内化于模型结构。
• 实验验证:在BLEnD和CAMeL-2文化问答数据集上,三款开源LLM(Llama-3.1、aya-expanse、Qwen2.5)表现出对高资源文化的偏好,且低资源文化因训练数据匮乏表现较差但文化扁平化现象较弱,提示提升低资源文化理解需侧重知识补充而非仅偏见缓解。
• 文化群体影响:CF得分及连接图显示,模型更倾向用美国、伊朗、中国等高资源文化知识来表征其他文化,尤其是地理邻近文化间存在明显的知识重叠和单向影响。
本研究首次从模型内部机制层面揭示文化偏见产生的动态过程,强调在提升LLMs文化理解时需考虑资源不平衡与地域因素的交互作用。未来工作可基于此框架设计针对性去偏策略和文化知识增强方案,构建更具文化敏感性和公平性的语言模型。
详情阅读👉 arxiv.org/abs/2508.08879
大型语言模型文化偏见机制可解释性人工智能公平性跨文化理解