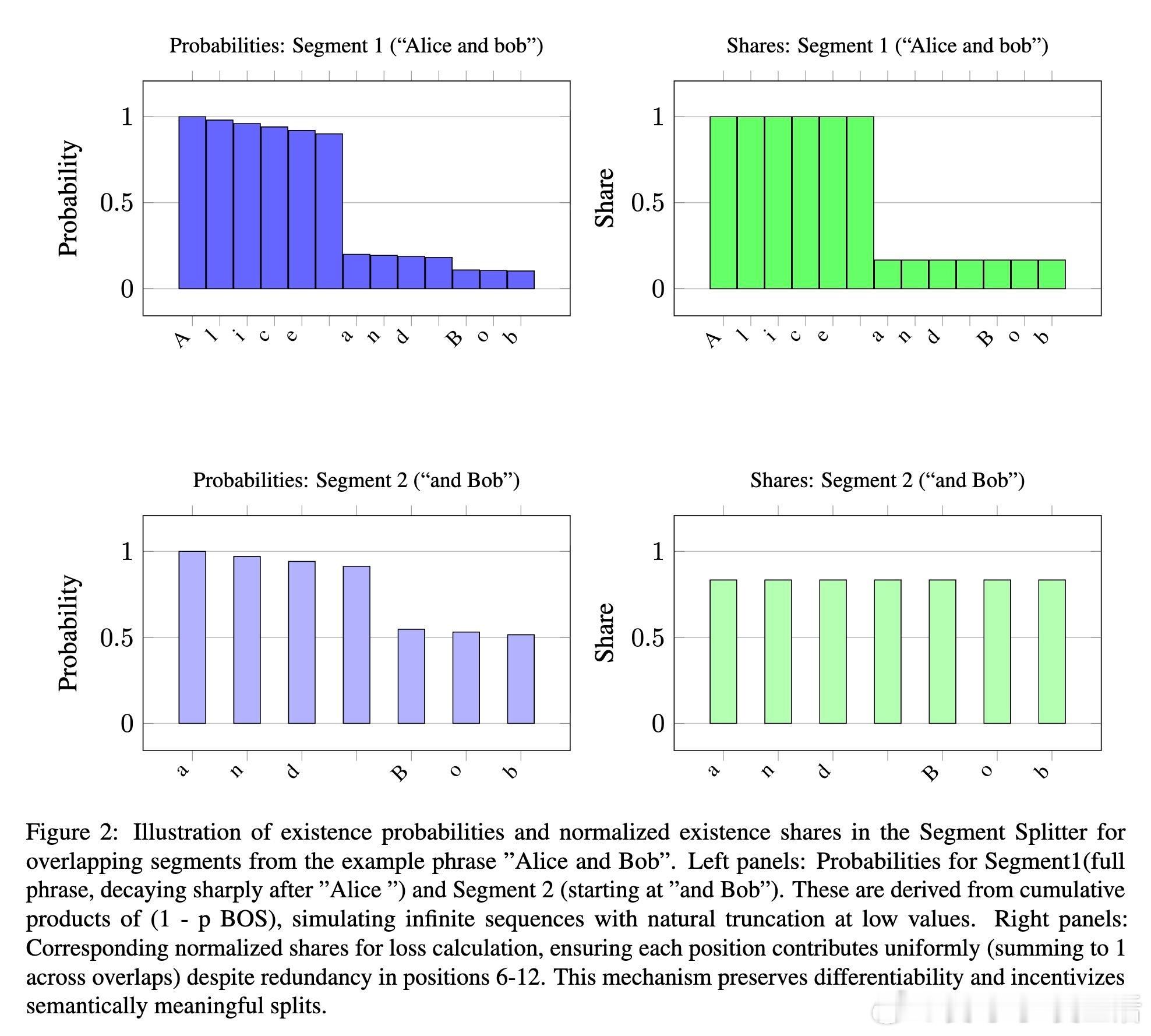
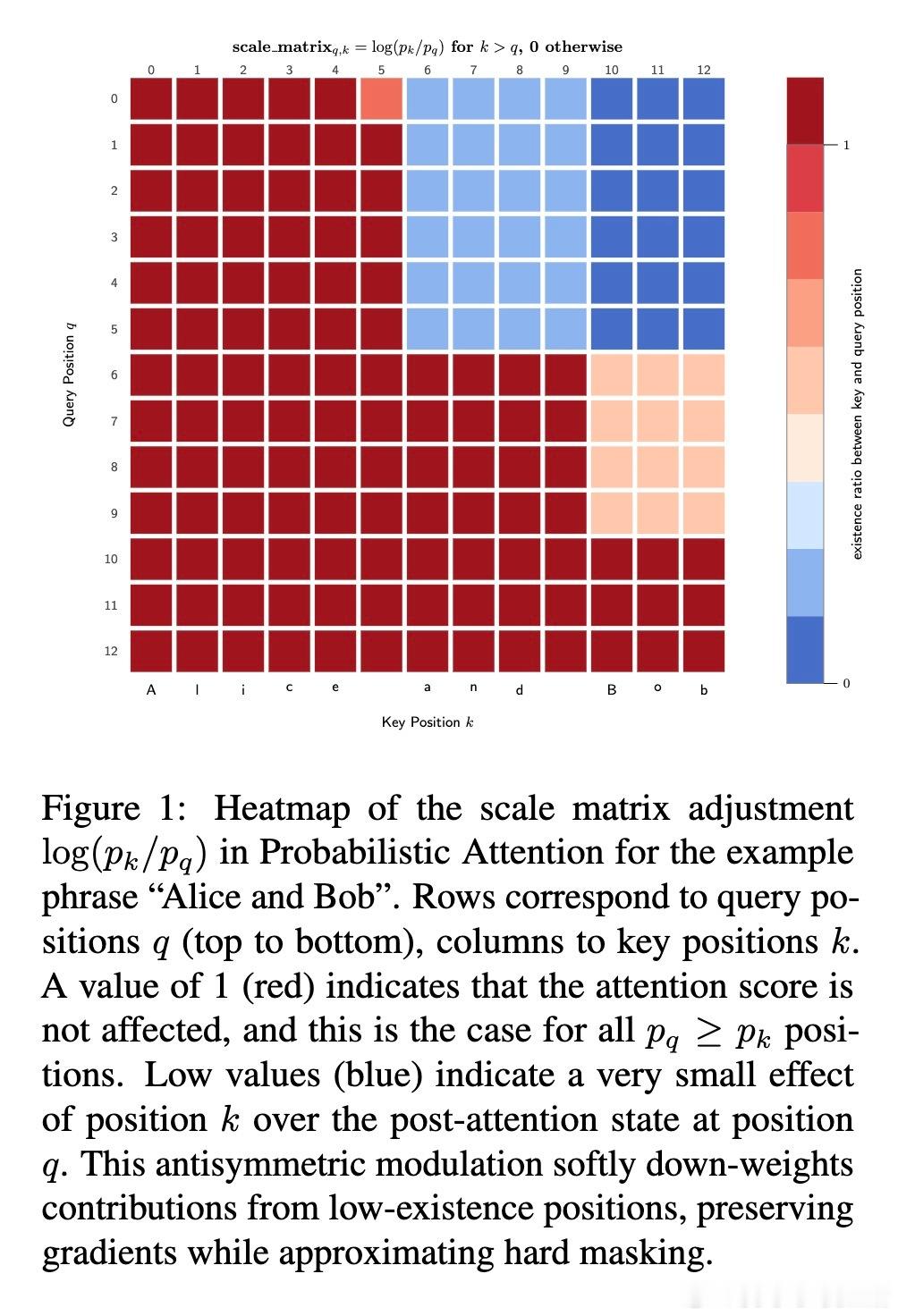
[CL]《Zonkey: A Hierarchical Diffusion Language Model with Differentiable Tokenization and Probabilistic Attention》A Rozental (2026)
长期以来,大语言模型一直被困在非微分分词器(如BPE)的“木桶效应”中。这种基于规则的硬性分割,让模型在面对噪声或特定领域数据时显得僵化。Zonkey的出现,试图打破这层天花板,实现从原始字符到文档表示的全链路梯度优化。
分词器的枷锁与进化的契机。现有的LLM虽强,但其基石——分词过程——却是不可微的。这意味着模型无法根据最终任务的反馈来优化如何“看”文字。Zonkey引入了可微的分词器(Segment Splitter),它不再依赖预设规则,而是通过学习概率性的序列起始(BOS)决策,让模型自主发现语言的边界。
涌现的语言结构。在没有任何显式监督的情况下,Zonkey在训练中自发学会了:空格通常意味着单词的开始,而句号则标志着句子的终结。这种从底层数据中“长”出来的分词能力,让模型能够以最符合语义逻辑的方式压缩信息。金句:真正的智能不应被预设的规则定义,而应在理解数据的过程中自我重构。
概率注意力:处理无限序列的艺术。传统Transformer使用硬掩码(Hard Mask),这会导致梯度断裂。Zonkey提出了概率注意力机制,为每个位置分配一个“存在概率”。它将序列视为理论上的无限延伸,通过概率衰减来实现软截断。这种设计不仅保留了梯度流,还让模型能够优雅地处理变长输出。
DDMM:在混沌中寻找秩序。文本扩散生成的难点在于离散性与语义扭曲。Zonkey采用了去噪扩散混合模型(DDMM),它巧妙地平衡了DDPM的随机多样性与DDIM的确定性效率。在潜在空间中,它在不确定时保持谨慎,在路径清晰时果断跃迁,确保了从噪声到连贯文本的平滑演变。
层级化的压缩与缝合。Zonkey通过多级架构将字符压缩为词级向量,再进一步抽象为句子级向量。为了保证全局一致性,缝合器(Stitcher)负责将重叠的片段重新组装。这种层级化不仅提升了语义抽象能力,更带来了生成效率的质变:在深层架构中,模型可以并行生成整个句子或段落,而非逐字蹦单词。
非线性补全:打破从左到右的诅咒。得益于扩散机制,Zonkey原生支持文本填空(Infilling)。给定前缀和后缀,模型在潜在空间中对中间缺失的部分进行协同去噪。这让它在处理非顺序任务时,比传统的自回归模型更具全局视野。语言不是单向的洪流,而是多维语义在时空中的交织。
迈向全梯度驱动的语言模型。虽然目前Zonkey仍处于原型阶段,但它证明了一个关键命题:完全基于梯度的层级化扩散模型是可行的。它摆脱了固定词表的束缚,展现出了极强的领域自适应潜力。当模型能够自主决定如何感知和重组语言时,我们离真正的通用人工智能又近了一步。
深度思考。Zonkey的意义不仅在于技术指标的提升,更在于它对“分词”这一基础概念的重塑。如果说BPE是人类强加给机器的眼镜,那么Zonkey就是让机器长出了自己的眼睛。这种从底层逻辑出发的彻底变革,或许正是下一代大规模语言模型的进化方向。
arxiv.org/abs/2601.21768