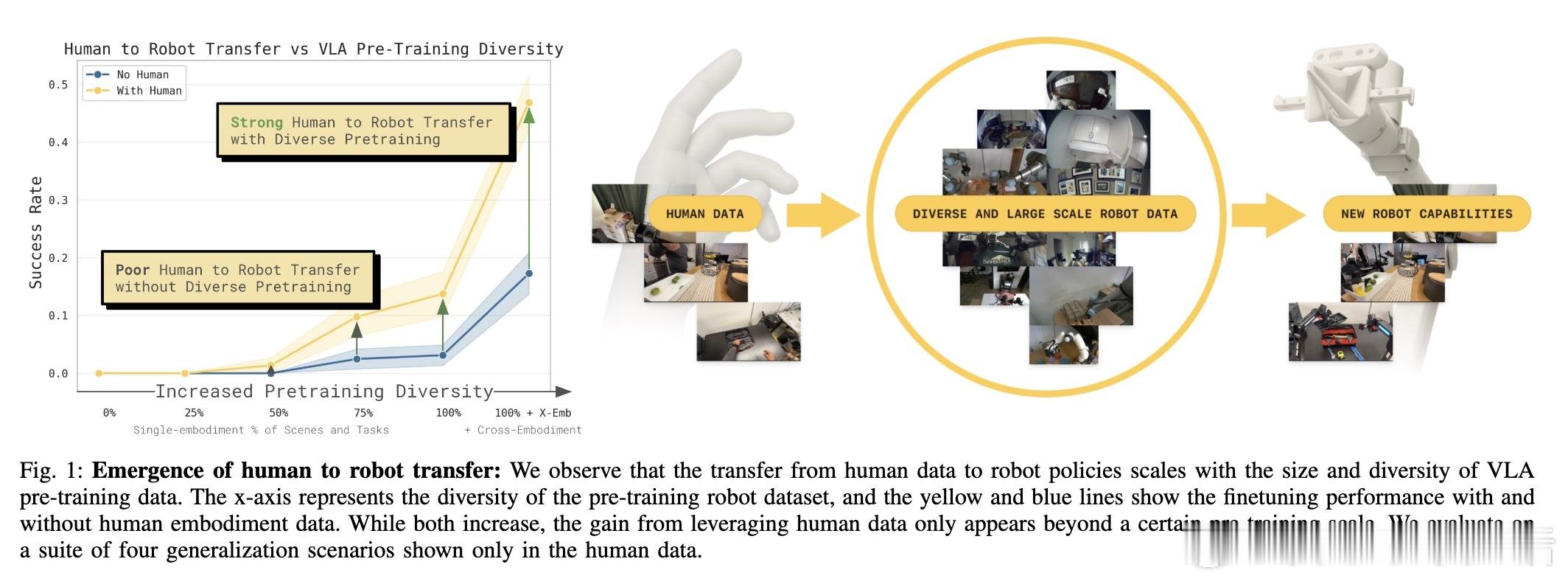
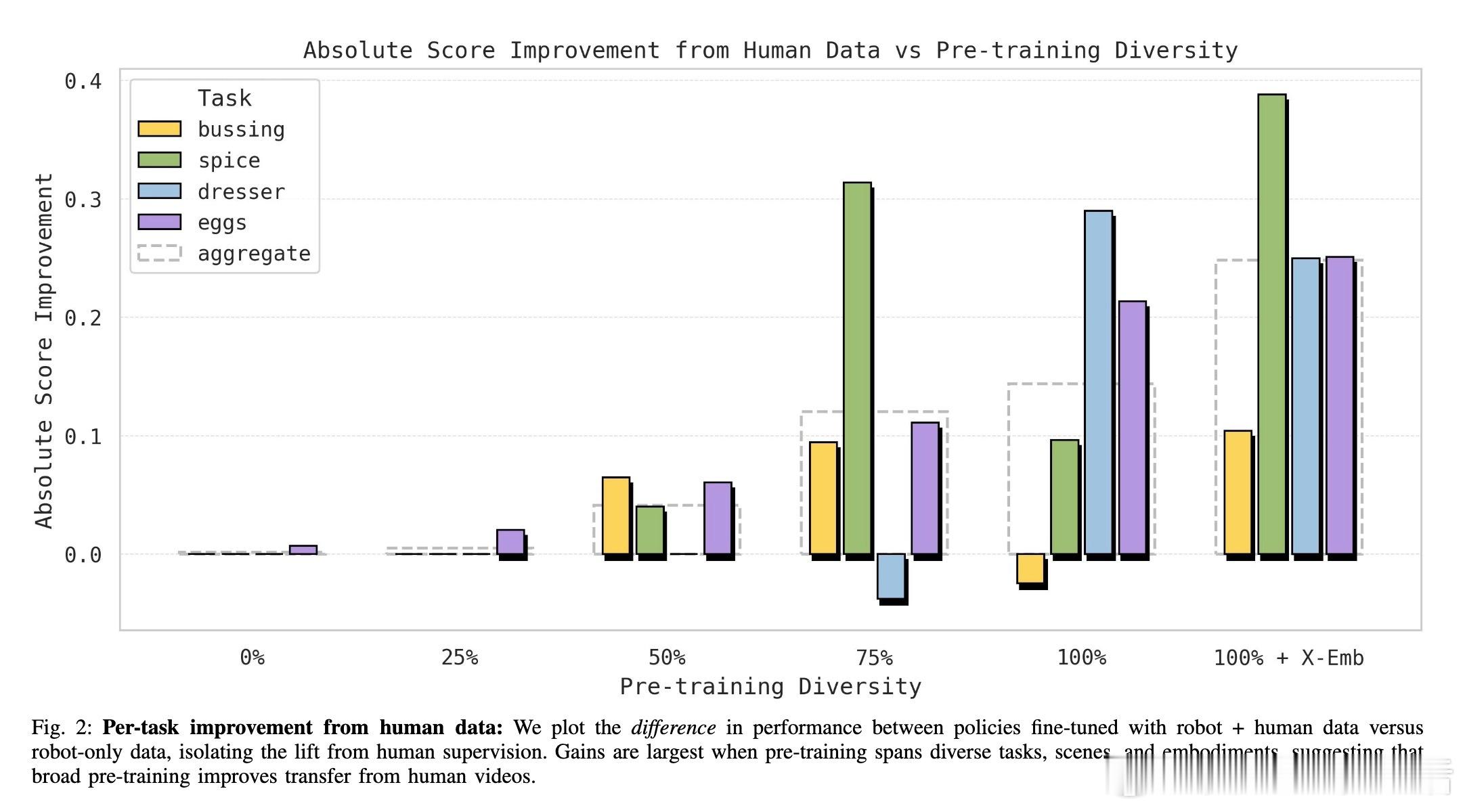
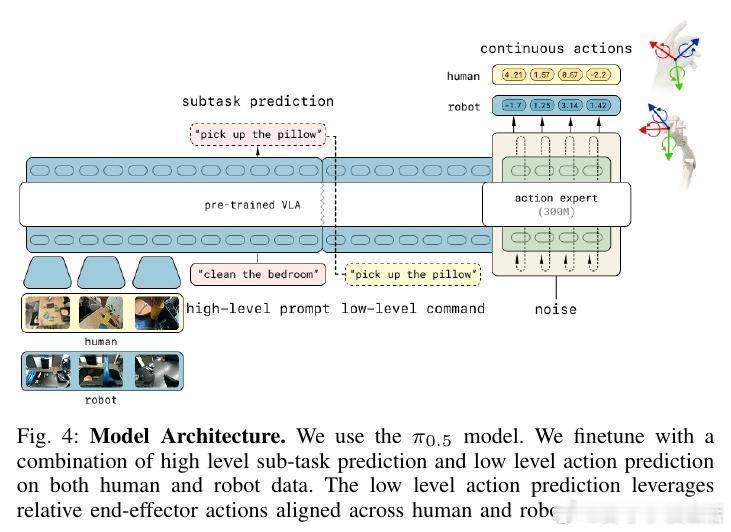
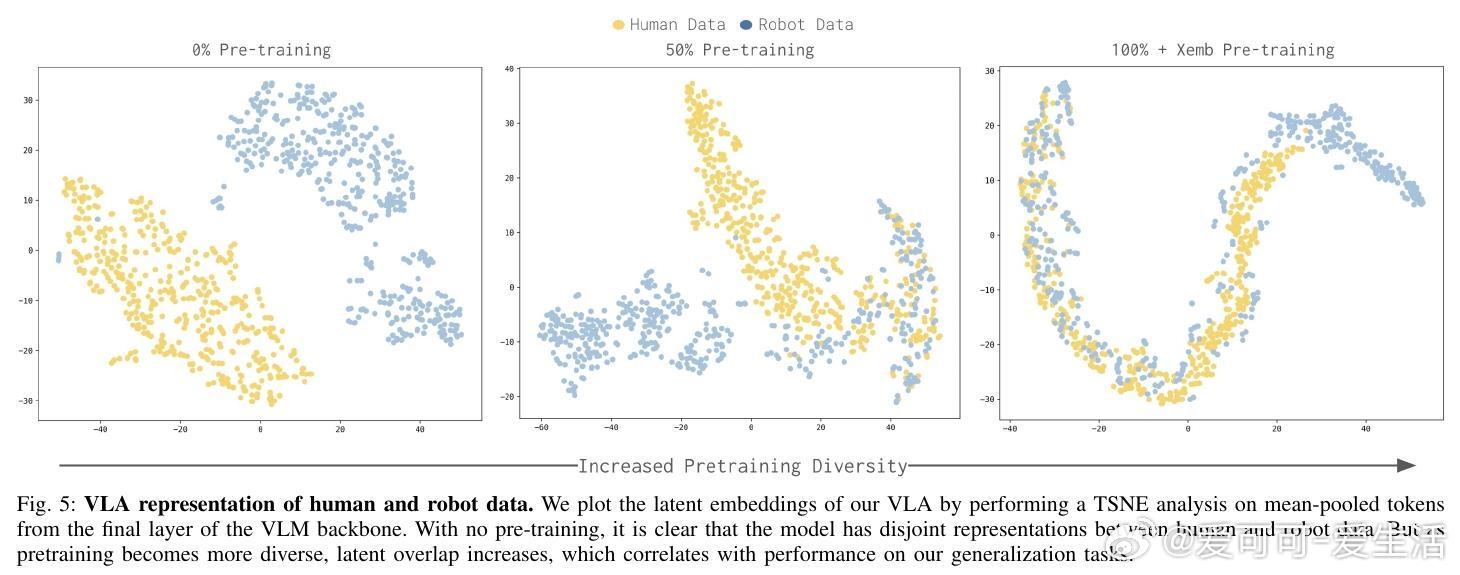
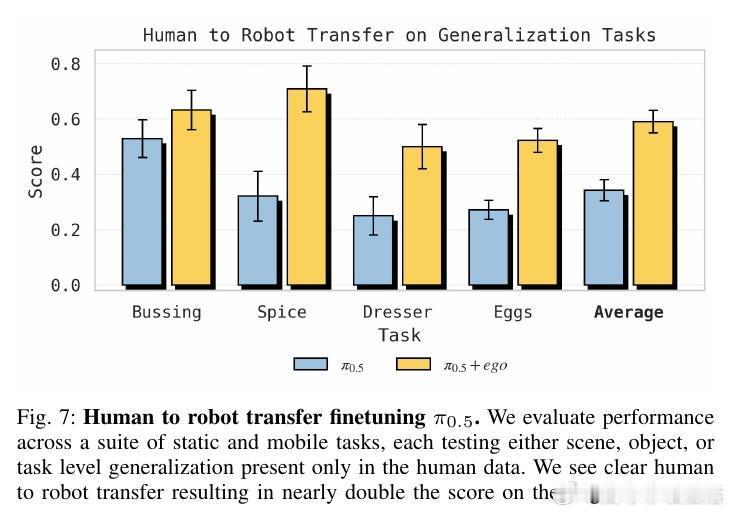
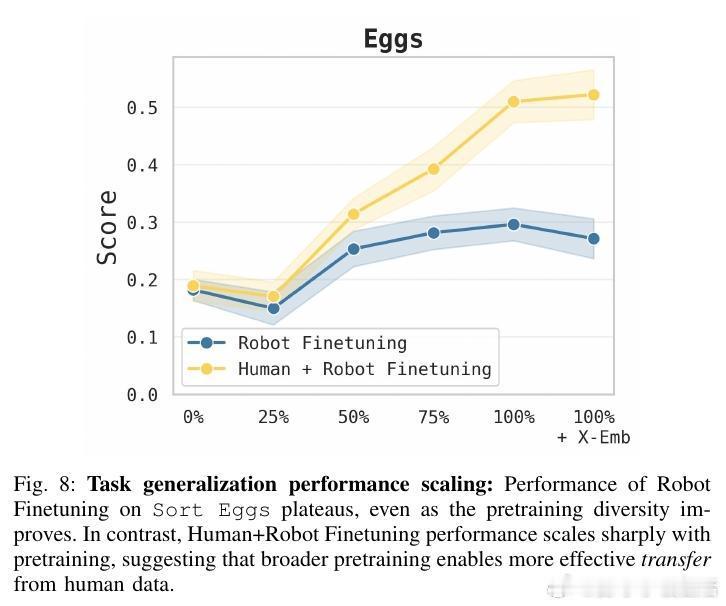
[RO]《Emergence of Human to Robot Transfer in Vision-Language-Action Models》S Kareer, K Pertsch, J Darpinian, J Hoffman... [Physical Intelligence] (2025) 想象一下,如果机器人只需“看”人类干活的视频,就能学会从未接触过的新技能,那该多好?长期以来,这被认为是机器人领域的圣杯,但跨物种的视觉和动作对齐一直是巨大的挑战。本文揭示了一个令人振奋的现象:这种“人机转换”能力并非刻意设计,而是随着模型预训练规模和多样性的增加而“涌现”出来的。研究团队提出了 $\pi_{0.5} + \text{ego}$ 方案。他们不再使用复杂的对齐算法,而是将人类视频视为一种特殊的“机器人形态”。通过追踪人类手部的3D轨迹和高层子任务描述,直接将人类动作喂给VLA模型进行联合微调。实验发现,预训练的广度决定了迁移的深度。当模型在成千上万种场景、任务和不同机器人形态中磨炼后,它开始形成“形态无关”的底层表征。TSNE可视化显示,随着预训练多样性提升,人类和机器人的潜在特征空间从完全割裂走向了深度融合。在具体测试中,这种迁移能力表现惊人:在未见过的公寓整理房间、处理从未见过的物体、甚至学会“按颜色分拣鸡蛋”这种机器人数据中从未出现的任务逻辑上,加入人类数据后的模型表现几乎翻倍。在某些任务中,人类视频提供的价值已经接近于昂贵的机器人实机采集数据。这背后的深刻启示是:通向通用物理智能的道路,可能并不需要为每种传感器差异编写补丁。当数据的多样性跨越某个临界点,模型会自动理解“抓取”这个动作的本质,无论那是一只人类的手,还是一个金属夹爪。这也意味着,互联网上浩如烟海的人类活动视频,正从“好看的素材”变成“机器人可用的教材”。我们正在进入一个规模化利用人类经验的新阶段,物理智能的上限将由人类文明的广度来定义。这种能力的涌现告诉我们,规模不仅仅是参数的堆砌,更是认知的跨越。当模型见过足够多的世界,它便学会了在不同形态之间寻找共性。原文链接:arxiv.org/abs/2512.22414