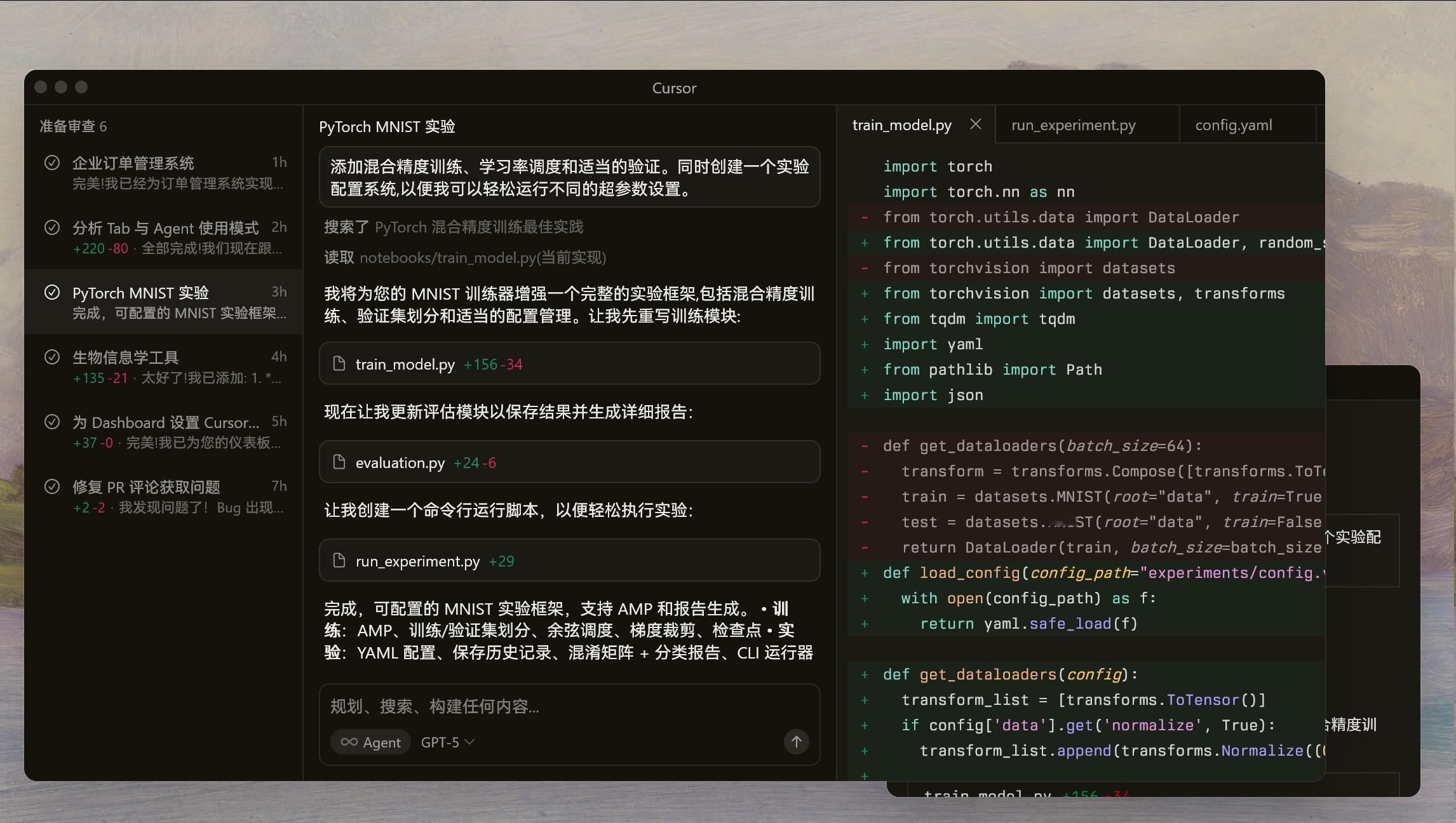
2025科技年度热问 受邀请,参与年度话题,分享我对今年AI发展的几点思考:微博科技列了三个问题,分别涉及今年的关键突破点、眼前一亮的产品和明年的发展趋势。我怕我乱答会误导的朋友,于是就想,如果是让Andrej Karpathy来回答,他会怎么回答?于是我导出了Andrej Karpathy 最近三个月的所有推文(包括评论)和他写的文章,发给AI,让Andrej Karpathy的数字分身,来回答下这三个问题,也许对你更有帮助。----------------------------------Q1:2025 年推动 AI 进入下一阶段的关键突破是什么?如果只能选一件事,我会选:RLVR(Reinforcement Learning from Verifiable Rewards)+ 推理时算力(test-time compute)。这听起来像两件事,但它们在产品体验上是一件事:模型不再只是“预测下一个 token”,它开始更像在做“可验证空间里的搜索(search)”。你给它一个可验证的奖励函数(比如数学题对不对、代码能不能通过测试、形式化推理是否一致),它就会在“思维轨迹/中间步骤”的空间里反复试,找到能赢的路线,然后把这种路线内化成能力。我喜欢把 2020-2024 的训练栈想成一棵树:⭕️Pretraining:灌溉知识与语言能力(大树的木头)⭕️SFT:教它“怎么回答像样”(枝叶整形)⭕️RLHF:让它更符合人类偏好(园艺师修剪)而 2025 的 RLVR 像是:你第一次给了它一个更稳定的“练功房”——奖励不是人类情绪,而是可验证信号。这让优化可以更厚、更长、更激进。于是出现那种“拐点感”:你会直觉地感觉到它从“会说话的系统”变成了“会解题的系统”。----------------------------------Q2:2025 年有哪些 AI 产品真正让我感到眼前一亮?我会列三个“范式级”的产品体验,它们代表了三条不同的路,但最后会合流到同一个方向。1️⃣ Cursor:新一层 LLM Apps 真正出现了Cursor 让我眼前一亮的点不在“写得多好”,而在它证明了:模型之上会长出一个很厚的新应用层,而且这个应用层不是皮肤,是骨架。它做的事情(也是我认为“新层”的典型构件)大概是:⭕️Context engineering:把你要解决的问题、代码库、diff、历史决策装配成“喂给模型的上下文”⭕️多次调用的编排:不是一次 prompt 搞定,而是底下串成一个 DAG,平衡成本/延迟/成功率⭕️人机协作的 GUI:让你在关键点介入(review、accept、rollback)⭕️Autonomy slider:同一个系统能“给建议”也能“自己动手干”这意味着:很多人 2025 讨论“模型能力”时,其实忽略了另一个巨大变量——产品把模型“组织起来”的能力。Cursor 让我确信:2025 不是只有更强的模型;更重要的是,模型开始被工程化地组织成“可用的工作流实体”。2️⃣ Claude Code:AI 第一次像“住在你的电脑里”我把 Claude Code 这类东西看成一种全新交互范式:它不再是网页里的一次性对话,而是一个常驻的、能动用你本地工具链的实体:终端、文件、git、脚本、测试、日志……它“就在现场”。这带来的不是“写代码更快”这么简单,而是心理上的变化:你开始把它当作一个(很奇怪的)同事——一个不会累、能并行、但也会犯低级错的同事。于是编程的层次结构开始变化。你会越来越多地做这些事:⭕️定义任务边界(什么叫 done)⭕️设计约束与护栏(别删错文件、别泄露密钥、别乱改接口)⭕️做最终审核(你承担责任)我在推文里说过类似的感觉:作为程序员,我从没像现在这样觉得“落后”。这不是情绪化的焦虑,而是职业结构真的在移动。3️⃣ Gemini “Nano Banana”:LLM GUI 的第一道闪电我对 Nano Banana 的兴奋点也不是“又一个更强模型”,而是它隐隐展示了一件事:图像/屏幕/GUI 本身正在变成新的 API。当一个模型能对着试卷照片解题、能在图上标注、能把视觉输入当作一等公民去推理时,你会意识到:未来的“使用电脑”可能不是点鼠标、不是写脚本,而是——让模型看屏幕、理解状态、然后行动。这条线一旦成立,后面的想象空间会很大:“软件”不再只是给人用的 UI,也不再只是给机器用的 API,而会出现一种第三形态:给 LLM 用的界面(LLM-first interface)。----------------------------------Q3:展望 2026,哪个趋势是不可忽视的必然路径?我会押一个我觉得“不可避免”的合流趋势:Agentic LLM Apps 会变厚,并且会全面渗透到你的真实工作流里:私有数据 + 工具调用 + 反馈闭环 +(适度的)自治。它们会像“数字工厂(digital factorio)”一样,把大量工作 JIT 化、自动化,并产生复利。为什么我觉得它必然?因为 2025 已经把三个关键部件都点亮了:⭕️RLVR/推理算力旋钮:让“会解题/会规划”的倾向更强、更稳定(至少在可验证域)⭕️Cursor 证明新应用层:上下文装配、编排、GUI、自治滑条——这些会变成标准组件⭕️Claude Code / LLM GUI:让模型从“聊天框里”走到“你的电脑与工具链里”把这三件事拼起来,你就会得到 2026 的主角:更像同事的系统——它能接触你公司的私有知识库,能读写真实代码与文档,能跑测试,能发 PR,能监控指标,能在失败后自我修正(因为有 feedback loop),并且你可以用 autonomy slider 控制它到底是“建议模式”还是“执行模式”。当然,我对它也很谨慎。因为我在 2025 更强烈地感到:这些系统更像“ghosts”,不是“animals”。它们的智能是锯齿状的(jagged):能在某些地方惊艳你,也能在你最想当然的地方出糗;能把基准测试刷爆,也仍然离“可靠的通用代理”很远。所以 2026 的另一条隐含必然路径是:可验证性与评估体系会重新成为核心工程。我们会更不信 benchmarks,更依赖“在你真实环境里的闭环评估”。换句话说:训练在测试集上可能越来越容易,但在真实世界里稳定交付仍然很难。