[LG]《The Art of Scaling Reinforcement Learning Compute for LLMs》D Khatri, L Madaan, R Tiwari, R Bansal... [Meta & UT Austin & UC Berkeley] (2025)
强化学习(RL)在大型语言模型(LLMs)训练中日益关键,但相较于预训练,RL缺乏可预测的规模扩展方法。本文首次开展超40万GPU小时的大规模系统研究,提出基于Sigmoid函数的计算-性能曲线框架,系统评估不同RL设计选择对性能上限和计算效率的影响,揭示:
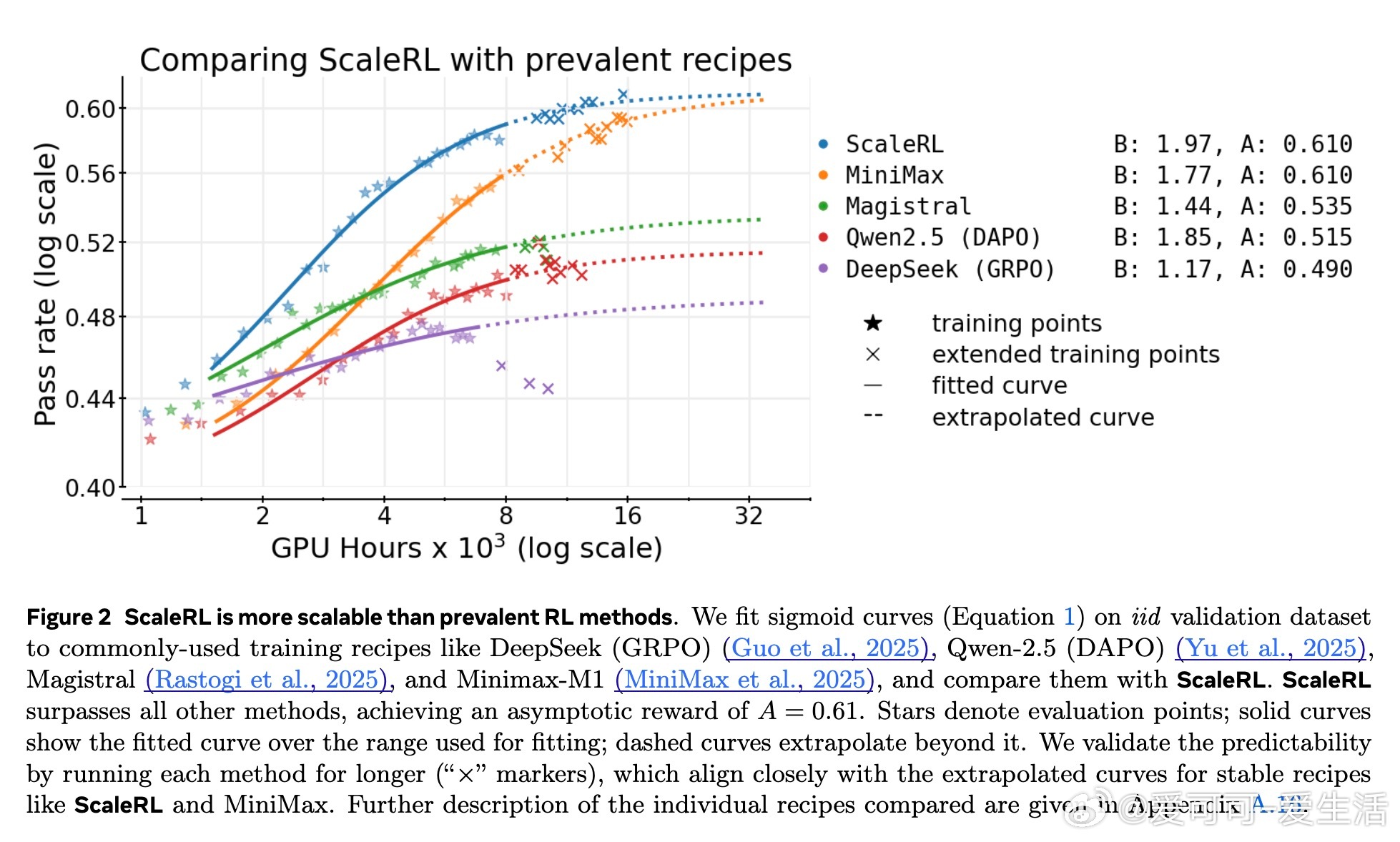
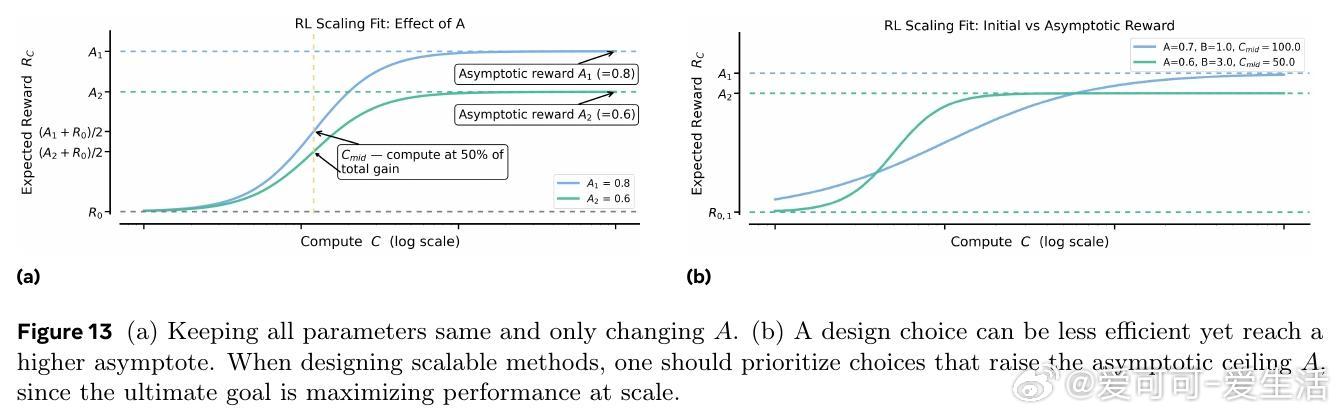
1. 不同训练方法的性能上限(Asymptote)存在显著差异。
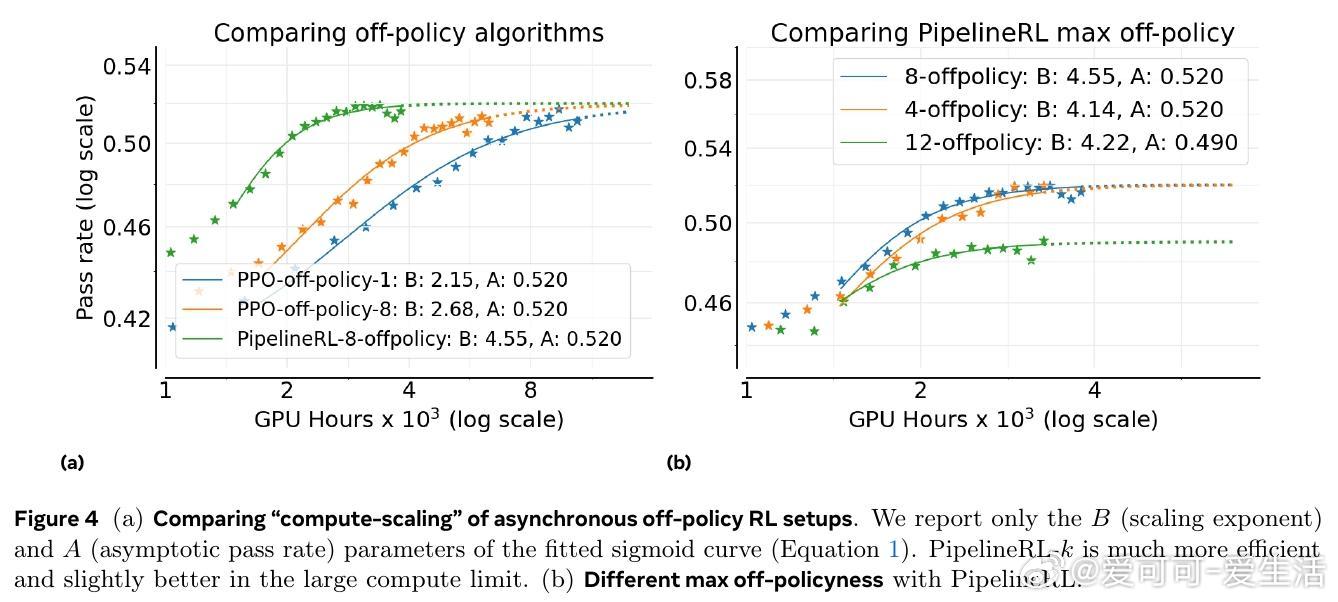
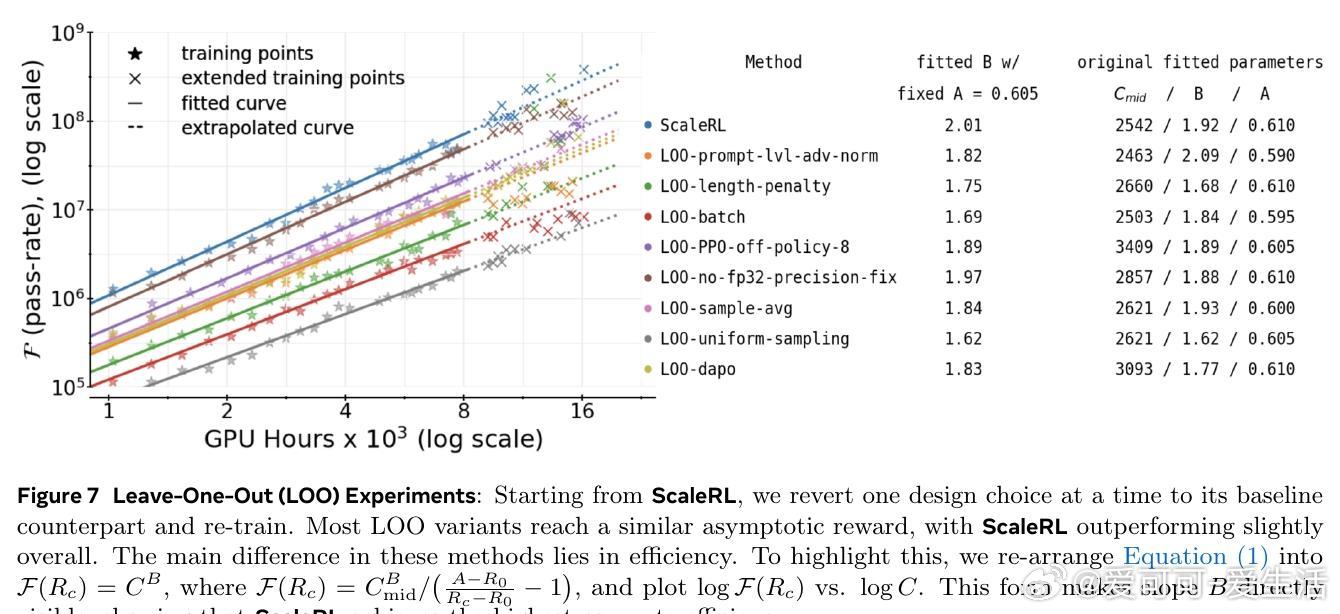
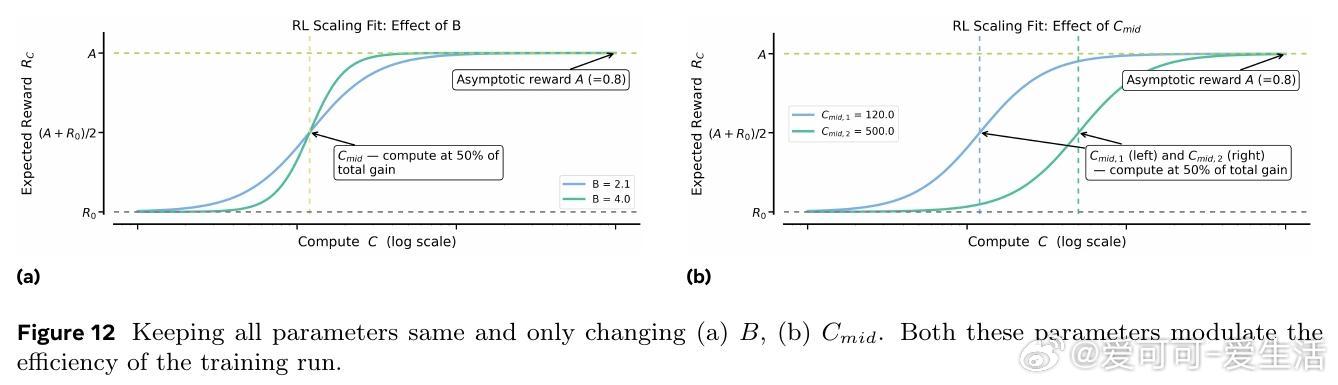
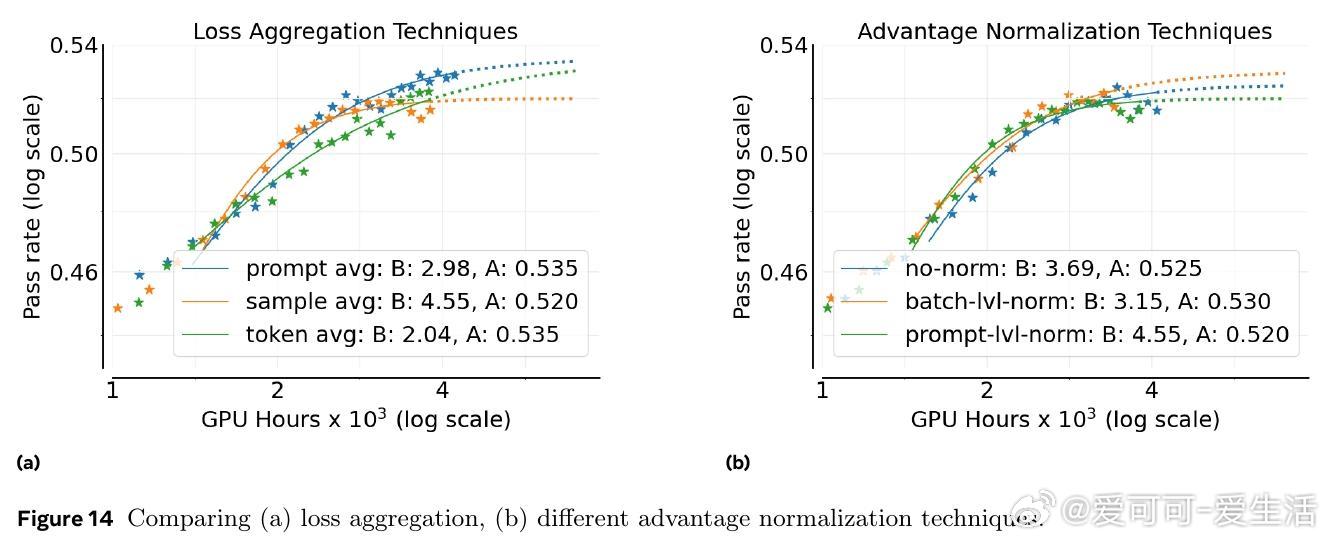
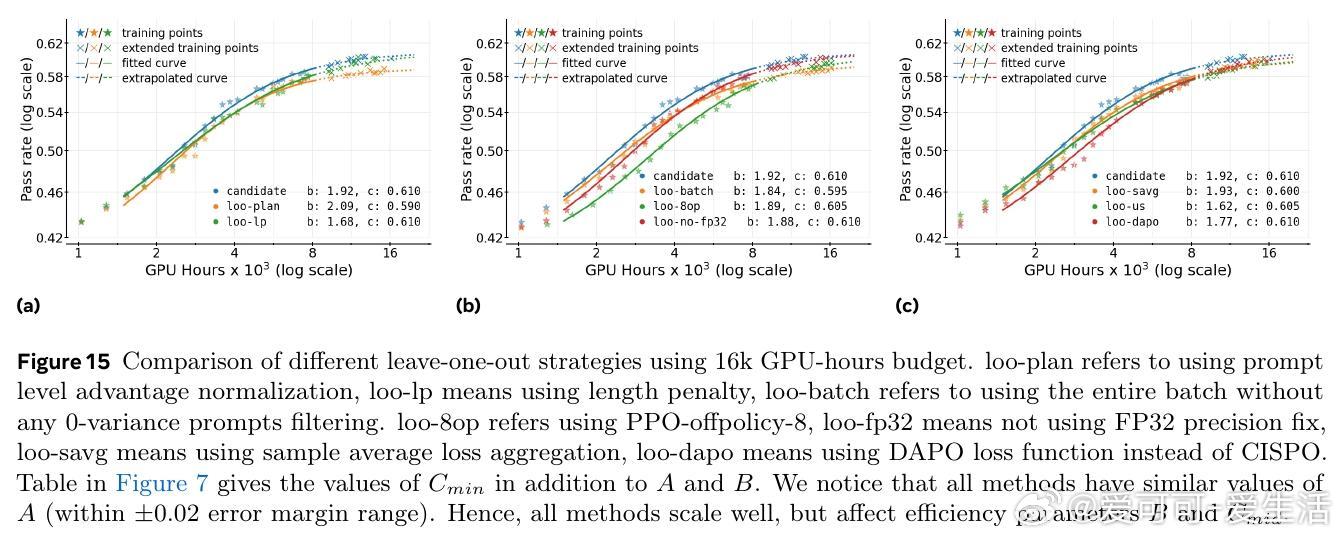
2. 损失聚合、归一化、训练课程和离线策略算法主要影响计算效率,而非性能上限。
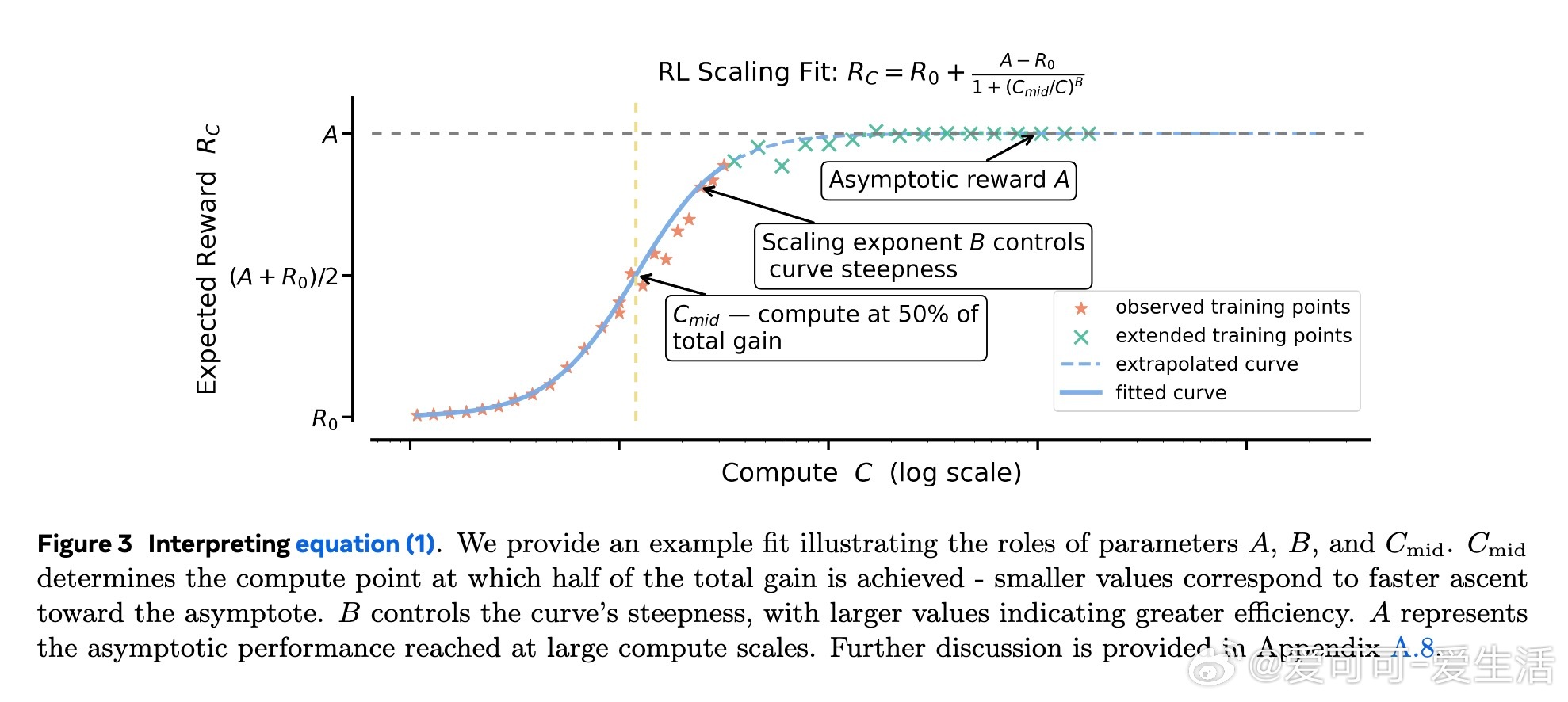
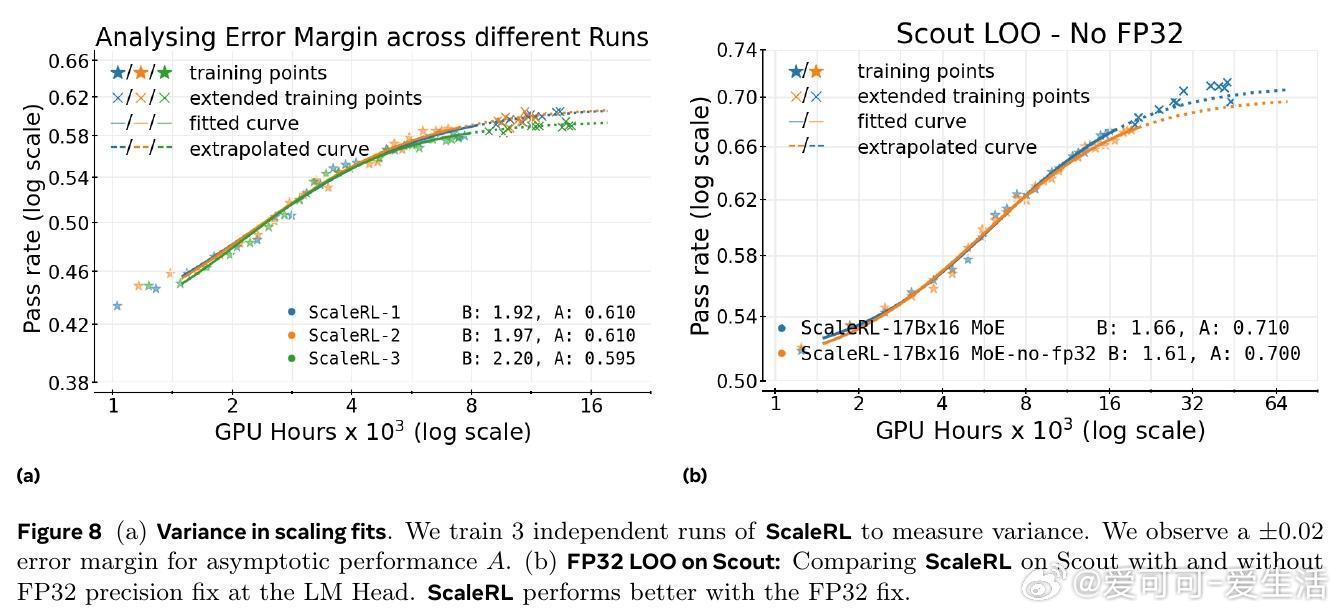
3. 稳定且可扩展的训练方案遵循可预测的规模扩展轨迹,可从小规模训练中准确外推大规模性能。
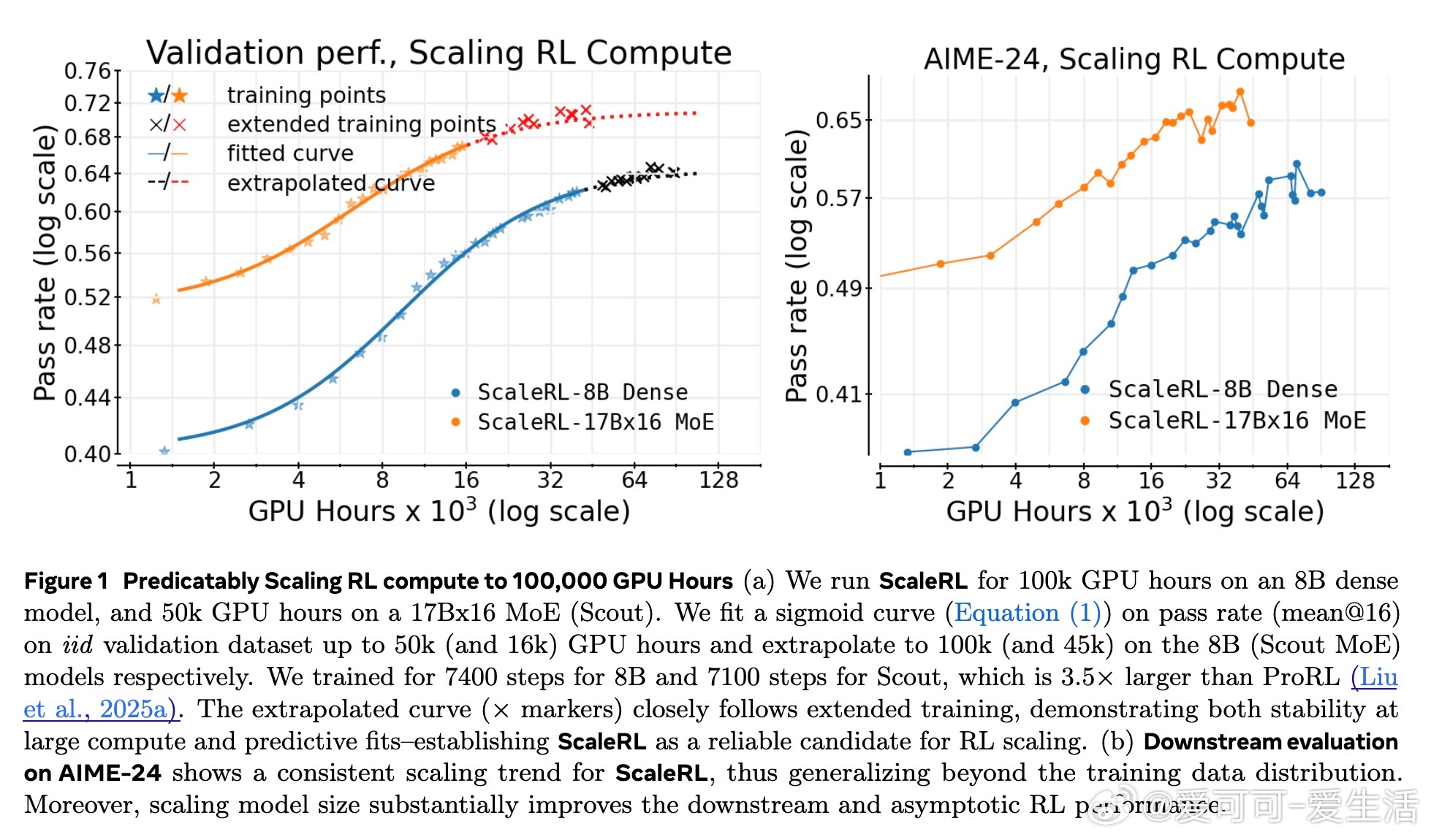
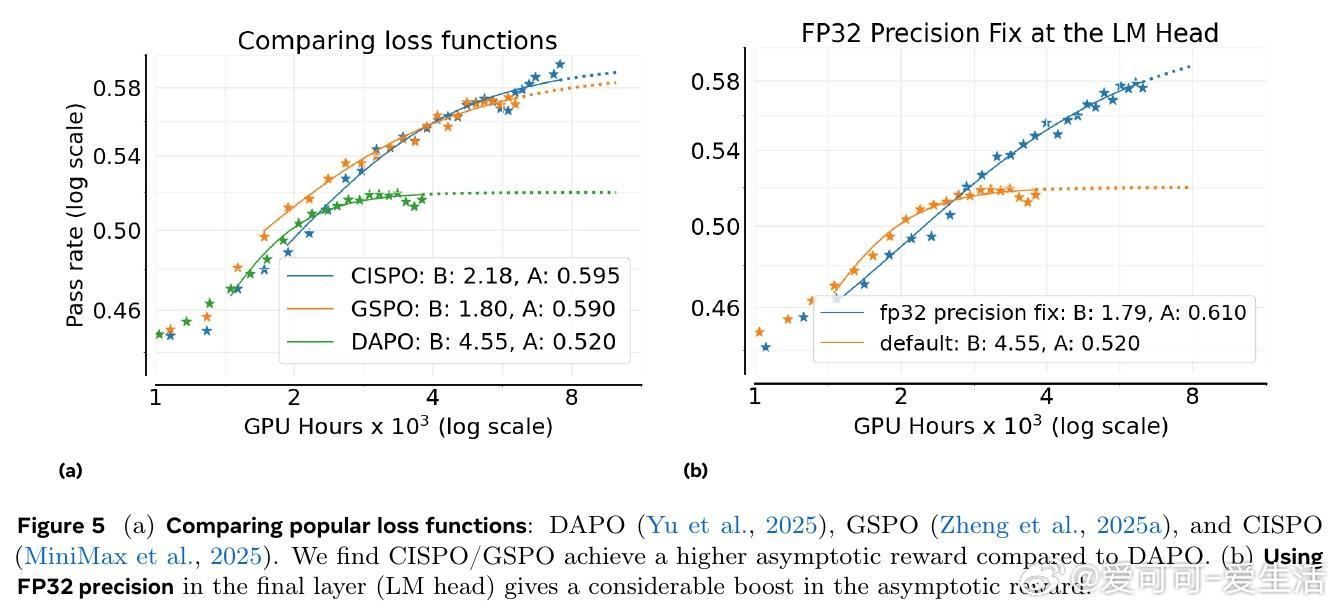
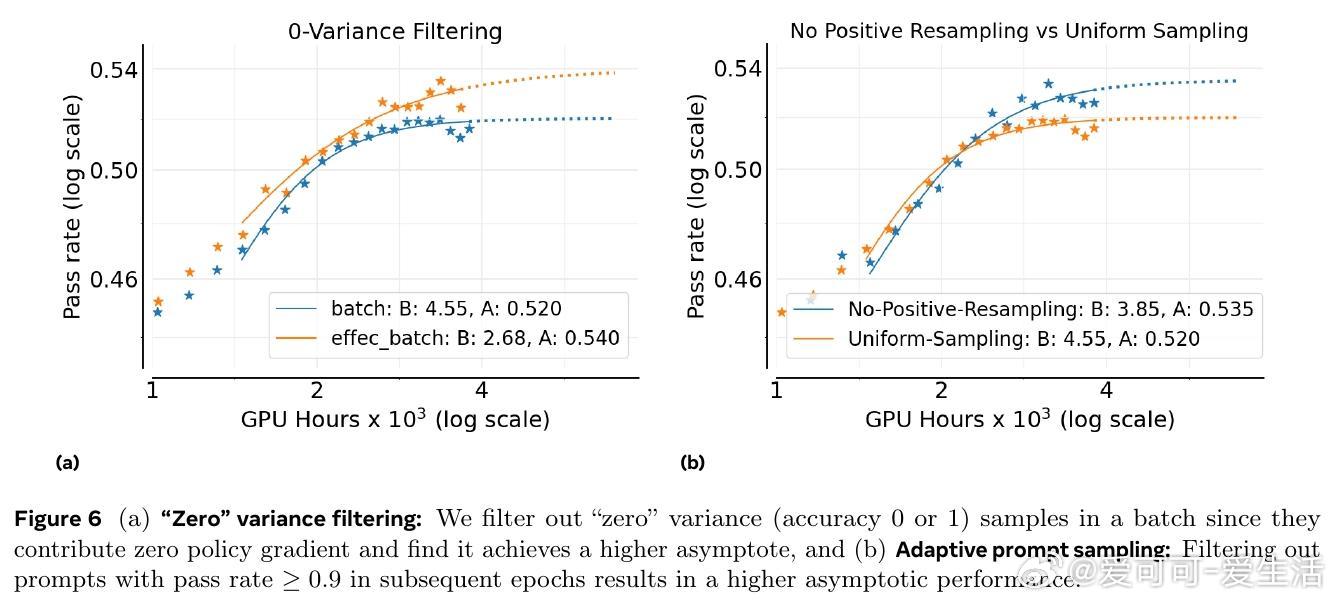
基于此,作者设计了ScaleRL训练方案,结合异步Pipeline-RL结构、截断重要性采样损失(CISPO)、FP32精度修正、零方差样本过滤及无正样本重采样等技术,成功实现了单次10万GPU小时的超大规模RL训练,验证了预测曲线的准确性。相比现有方法,ScaleRL在提升最终性能和计算效率上均表现卓越。
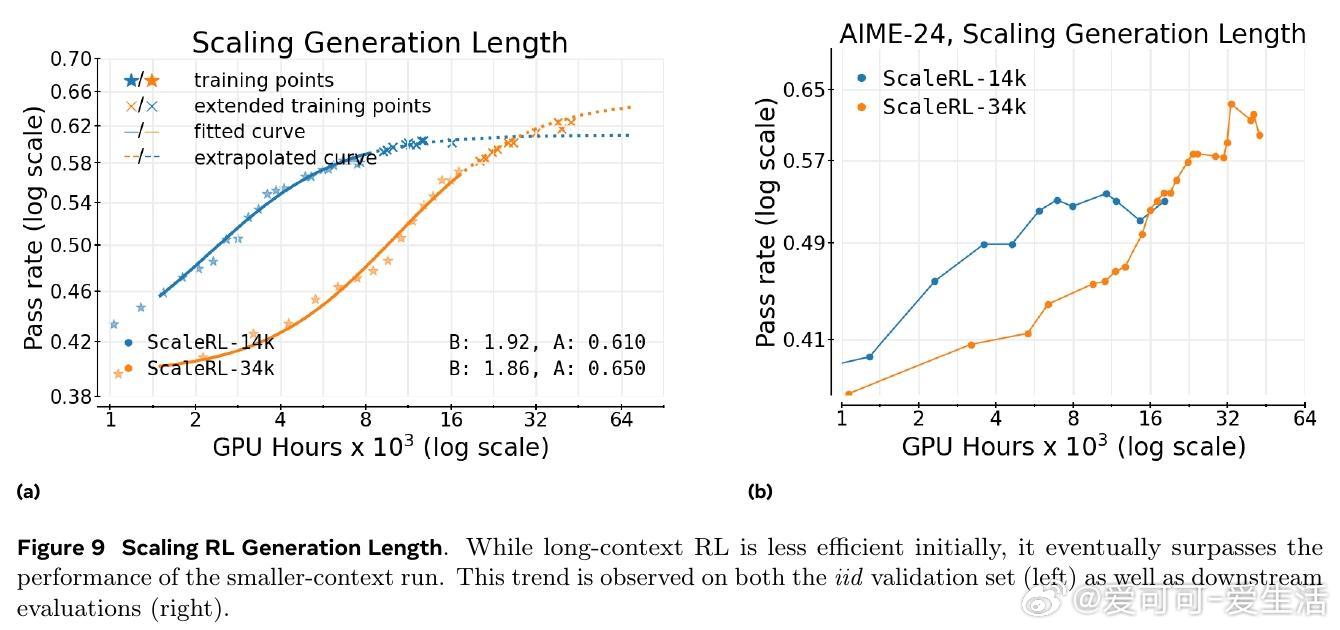
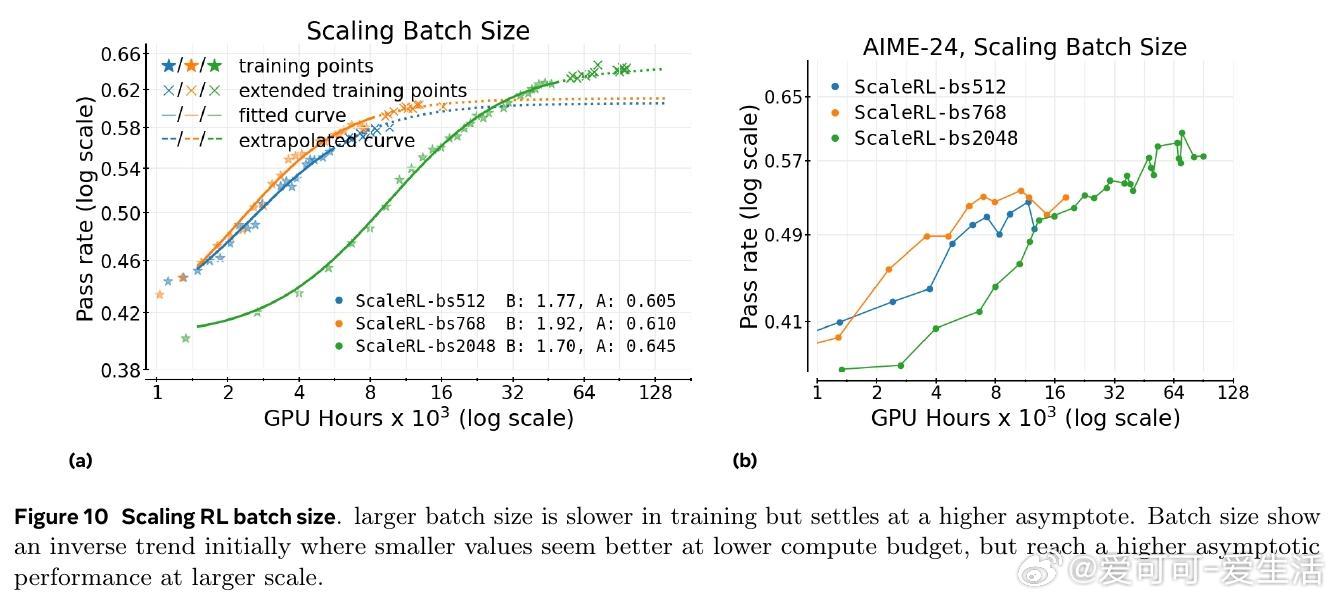
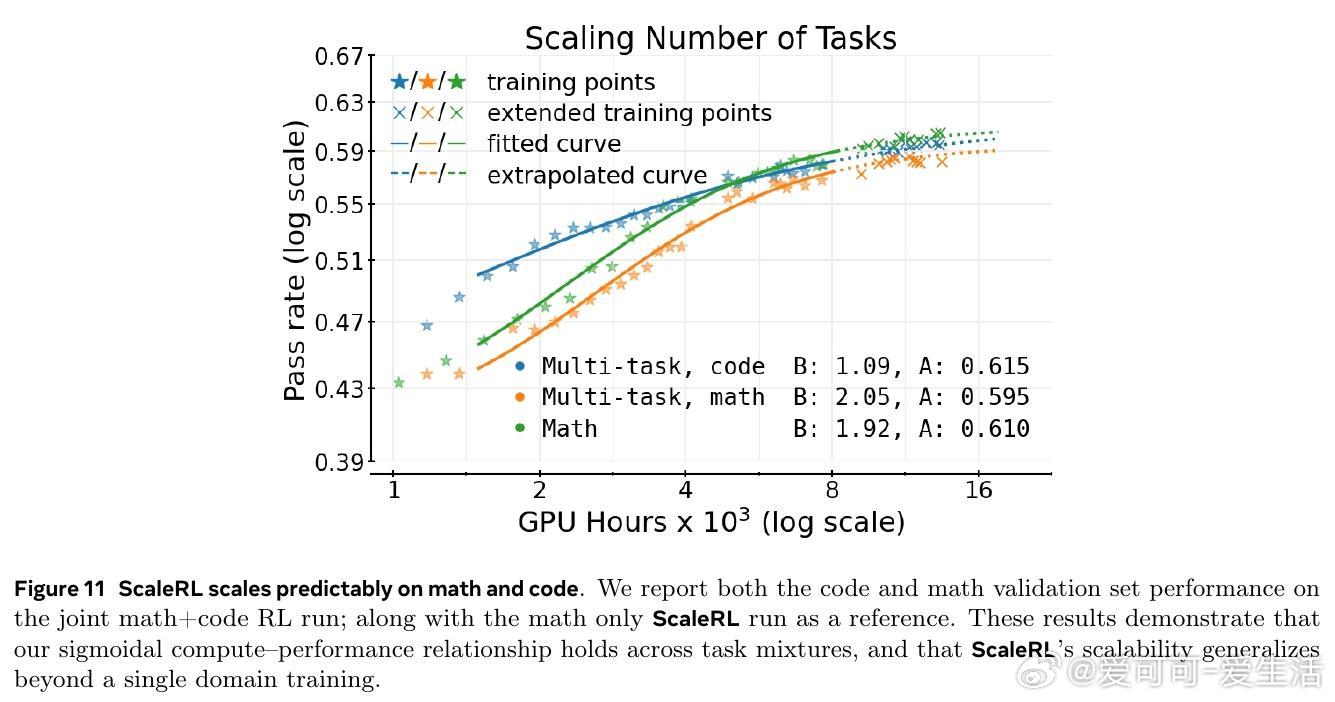
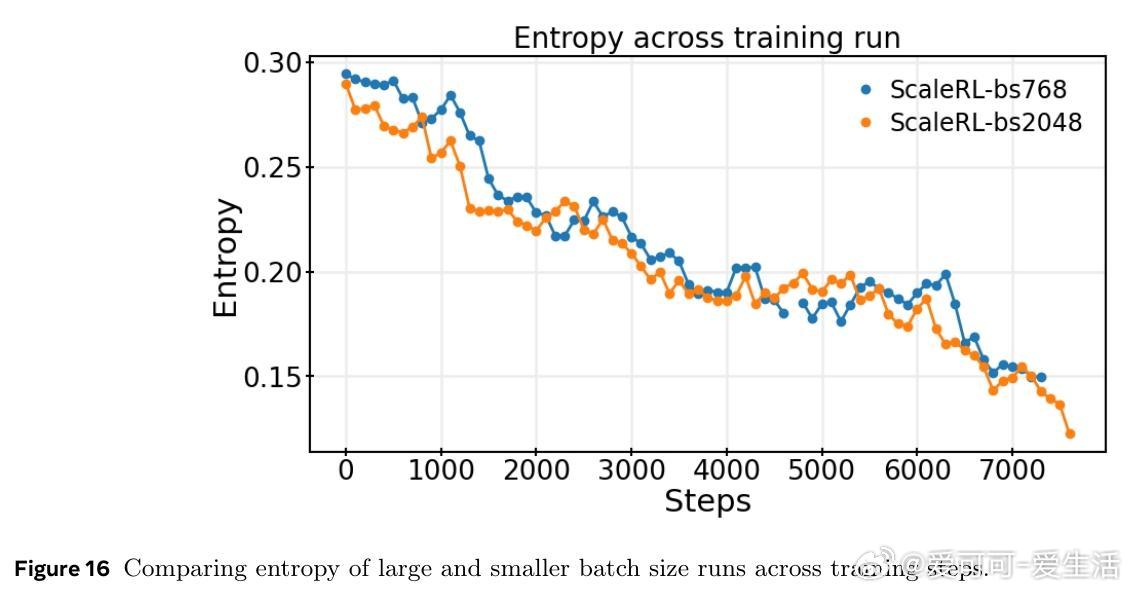
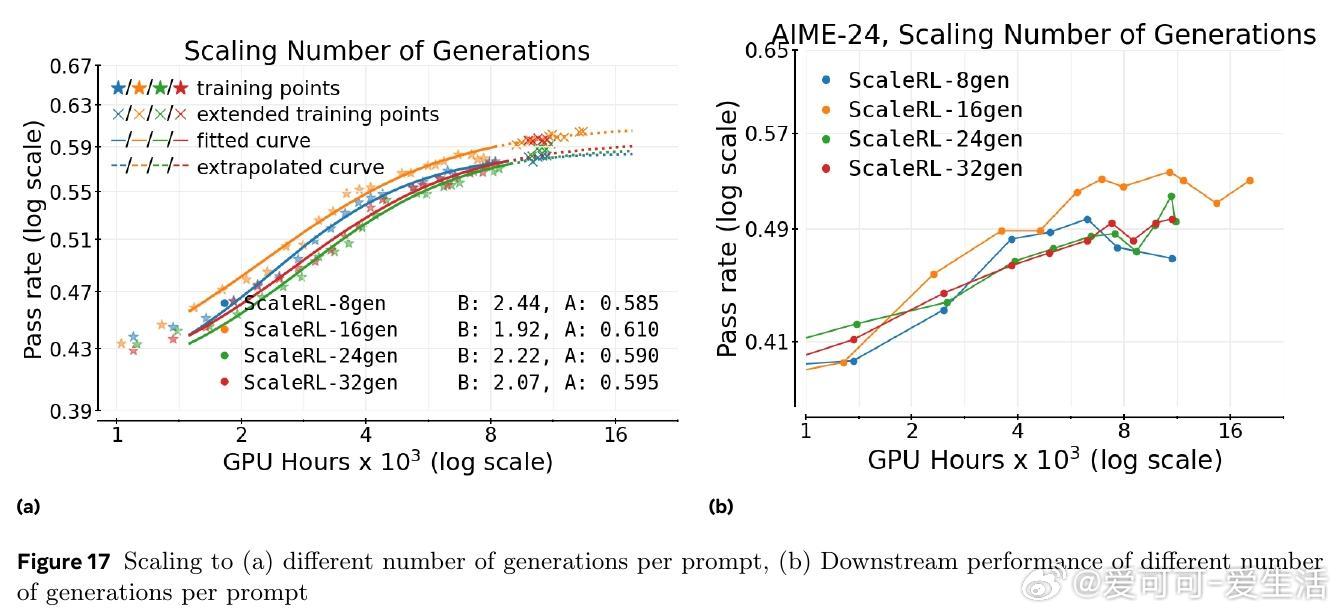
研究还发现,扩展模型规模、增加生成长度和批量大小均能显著提升RL性能上限,且ScaleRL在多任务(数学与编程)训练中表现出良好可扩展性和泛化能力。文章强调RL训练稳定性与截断率密切相关,合理设计可有效避免训练崩溃。
总结而言,本文为RL在LLMs训练中的规模扩展奠定了科学基础,提供了系统的评估框架和实践指南,有助于推动RL训练向更大规模和更高效能发展。未来工作可探索RL与预训练计算、模型规模和训练数据的联合扩展规律,及更复杂的RL训练场景。
原文链接:arxiv.org/abs/2510.13786
强化学习 大规模训练 大型语言模型 ScaleRL 计算效率