[AI]《LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings》B F. Maier, U Aslak, L Fiaschi, N Rismal... [PyMC Labs] (2025)
如何用大语言模型(LLMs)精准模拟人类购买意愿?最新研究突破传统调研瓶颈!🛍️
1/ 传统消费者调研耗资巨大,且受限于样本偏差和规模。LLMs提供新途径,但直接让模型给出Likert量表评分时,分布往往不真实,缺乏多样性。
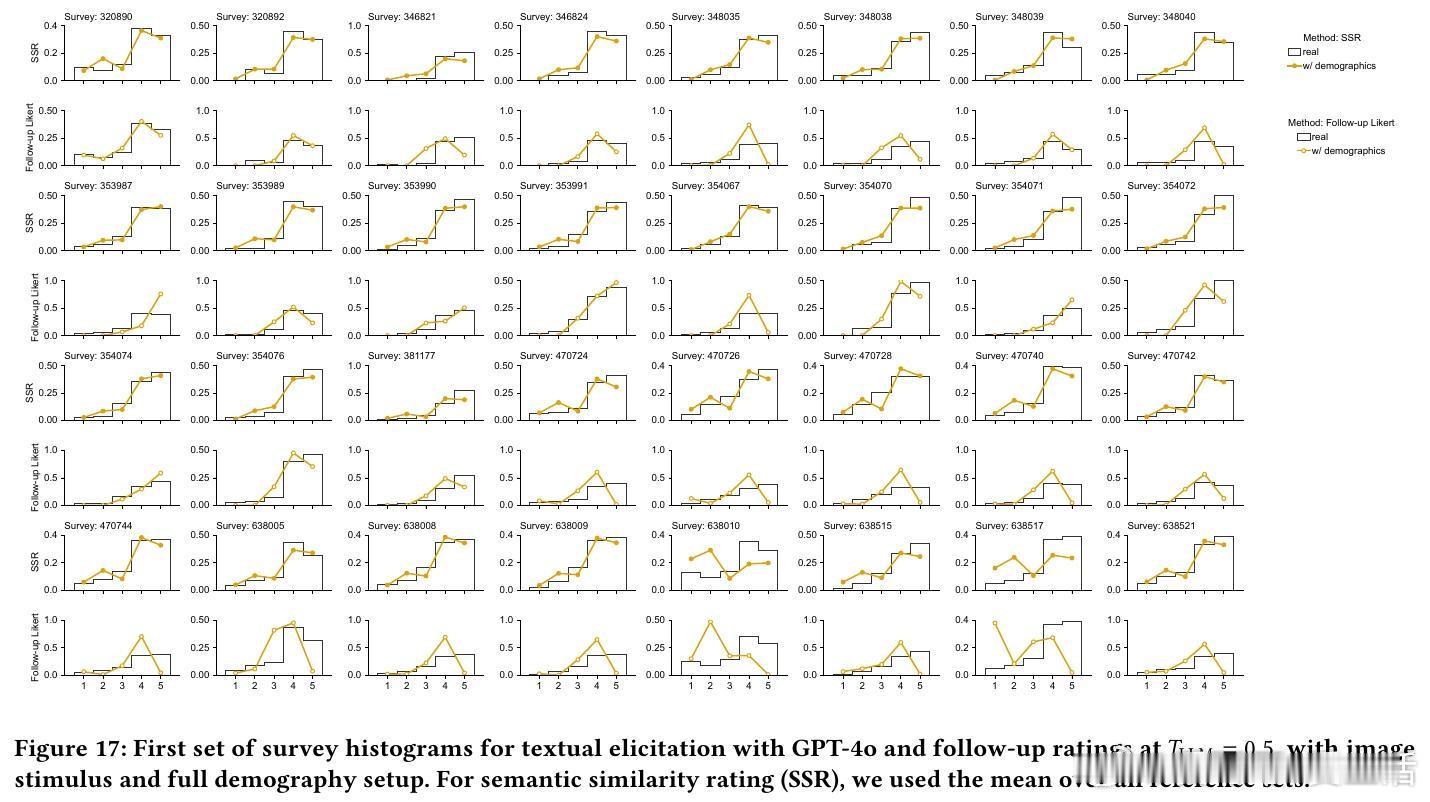
2/ 本文提出“语义相似度评分(SSR)”方法:先让LLM生成自由文本描述购买意愿,再通过与预定义锚点语句的嵌入向量相似度映射为Likert分布。创新结合NLP语义映射和问卷锚定小故事。
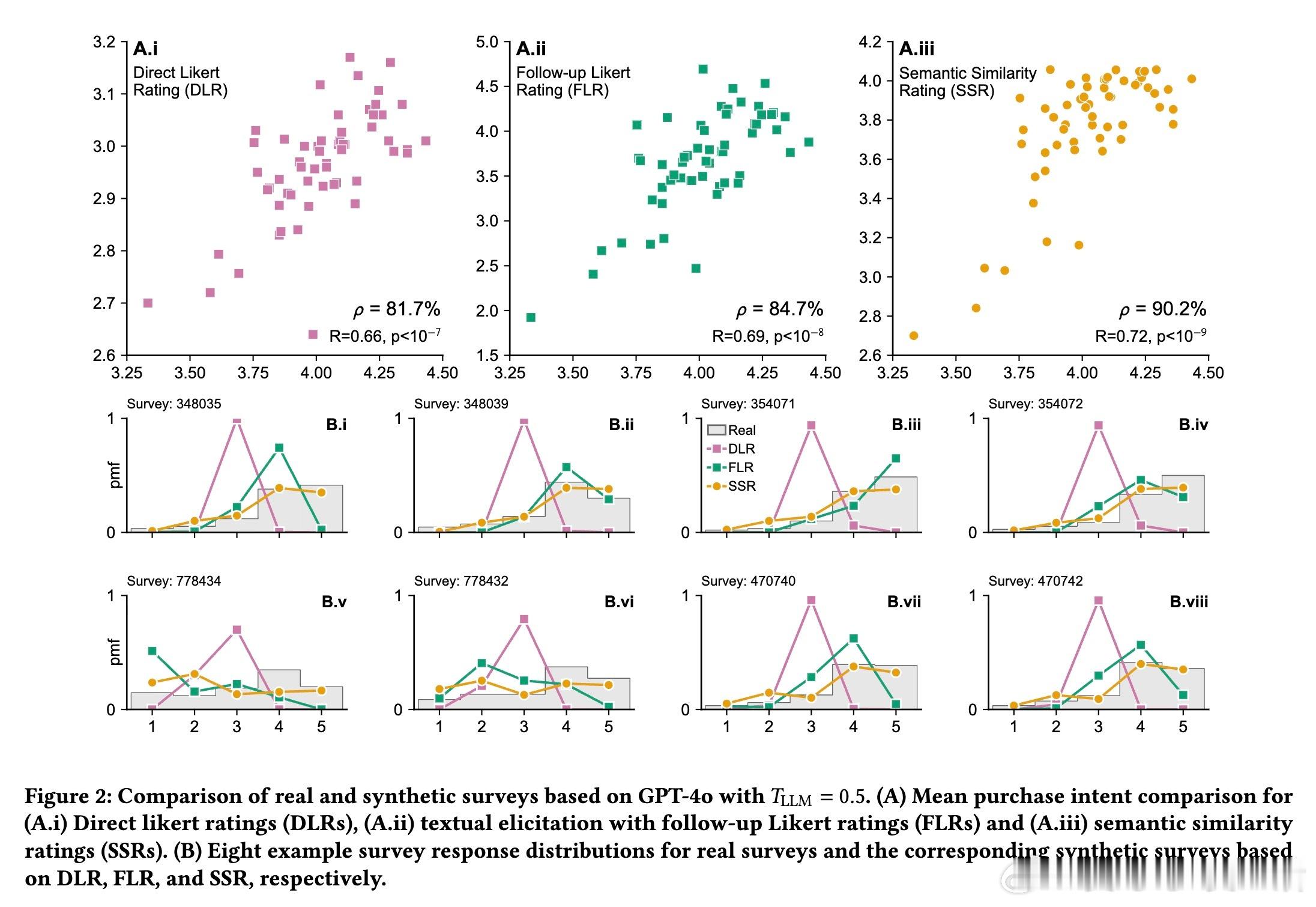
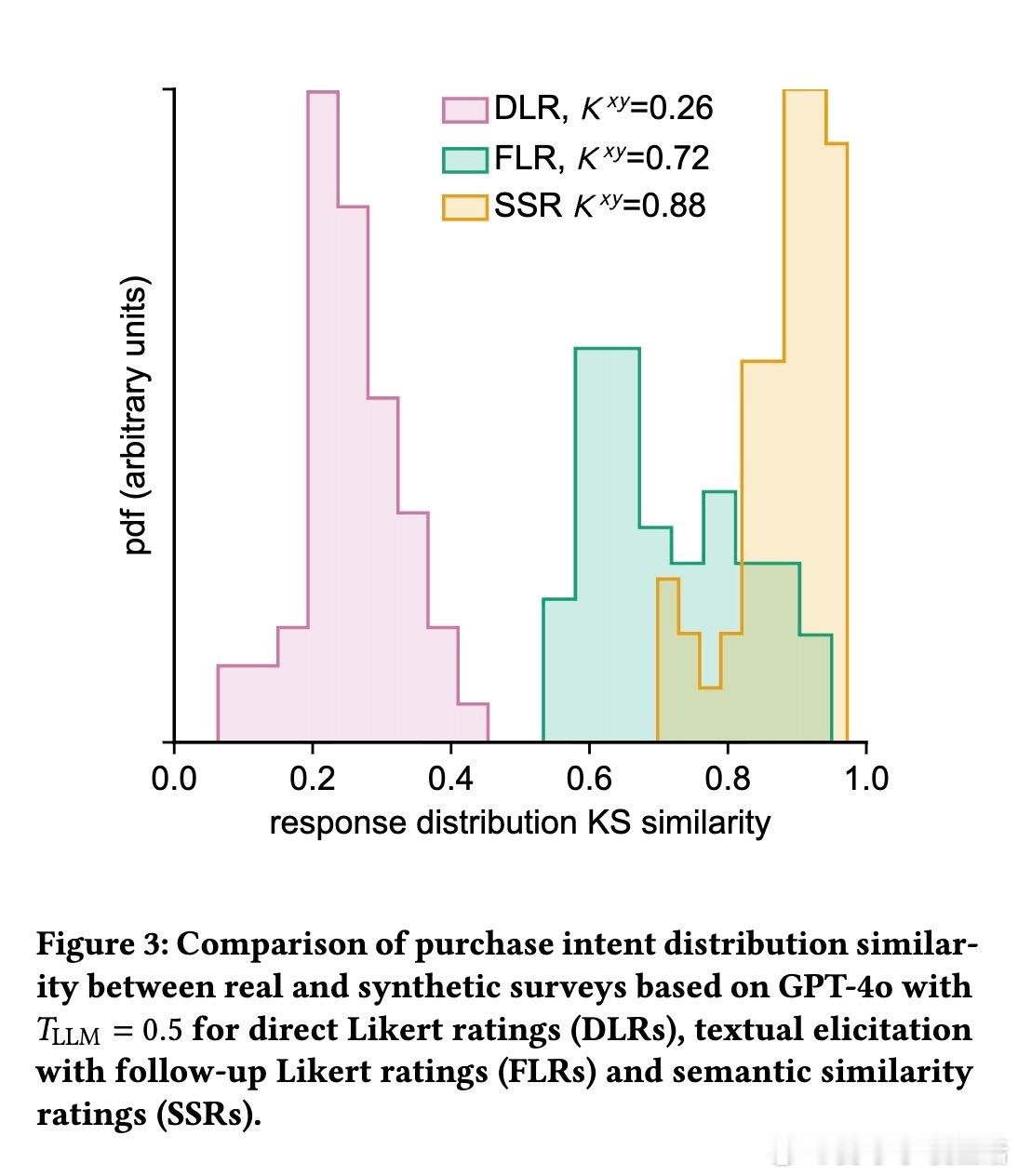
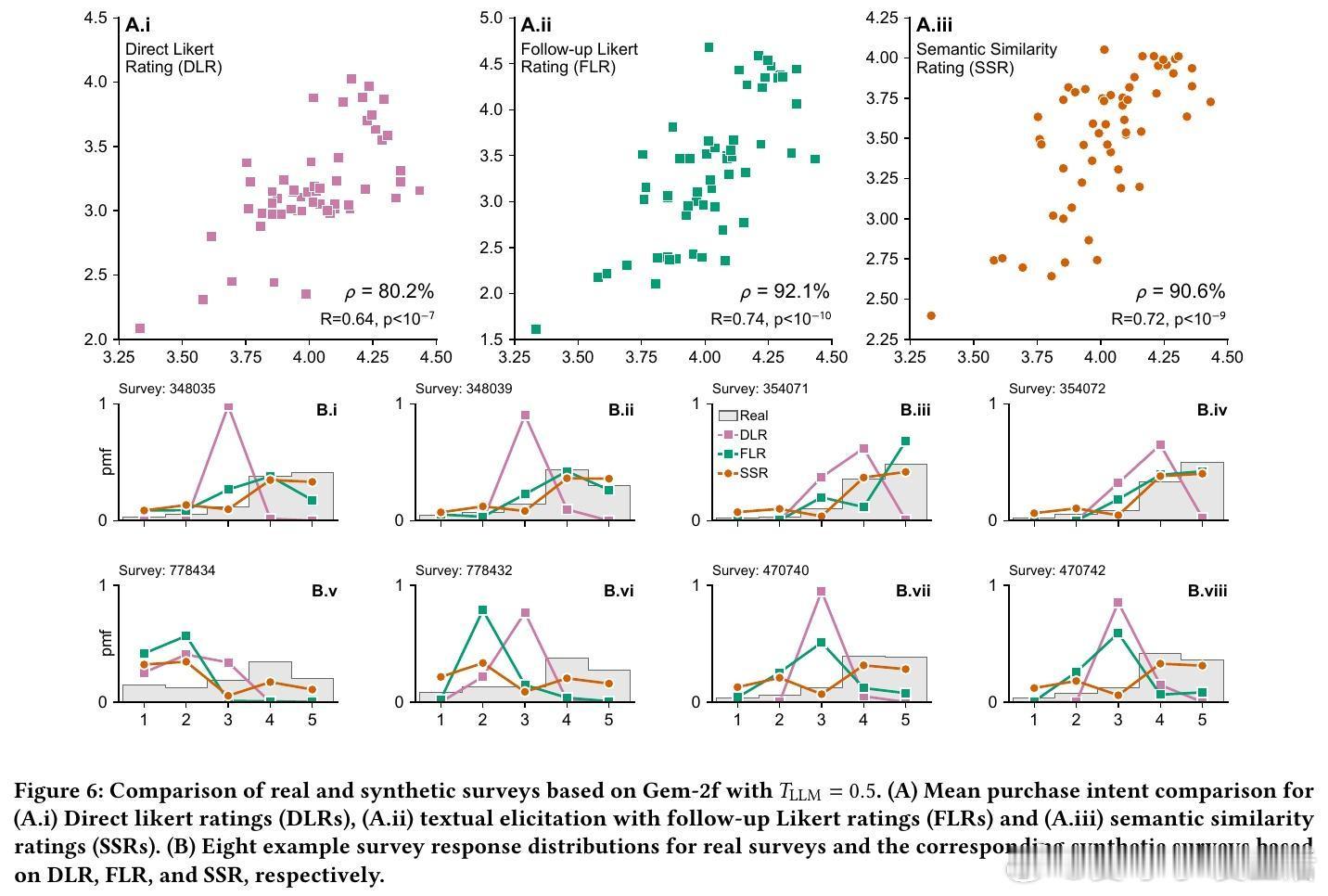
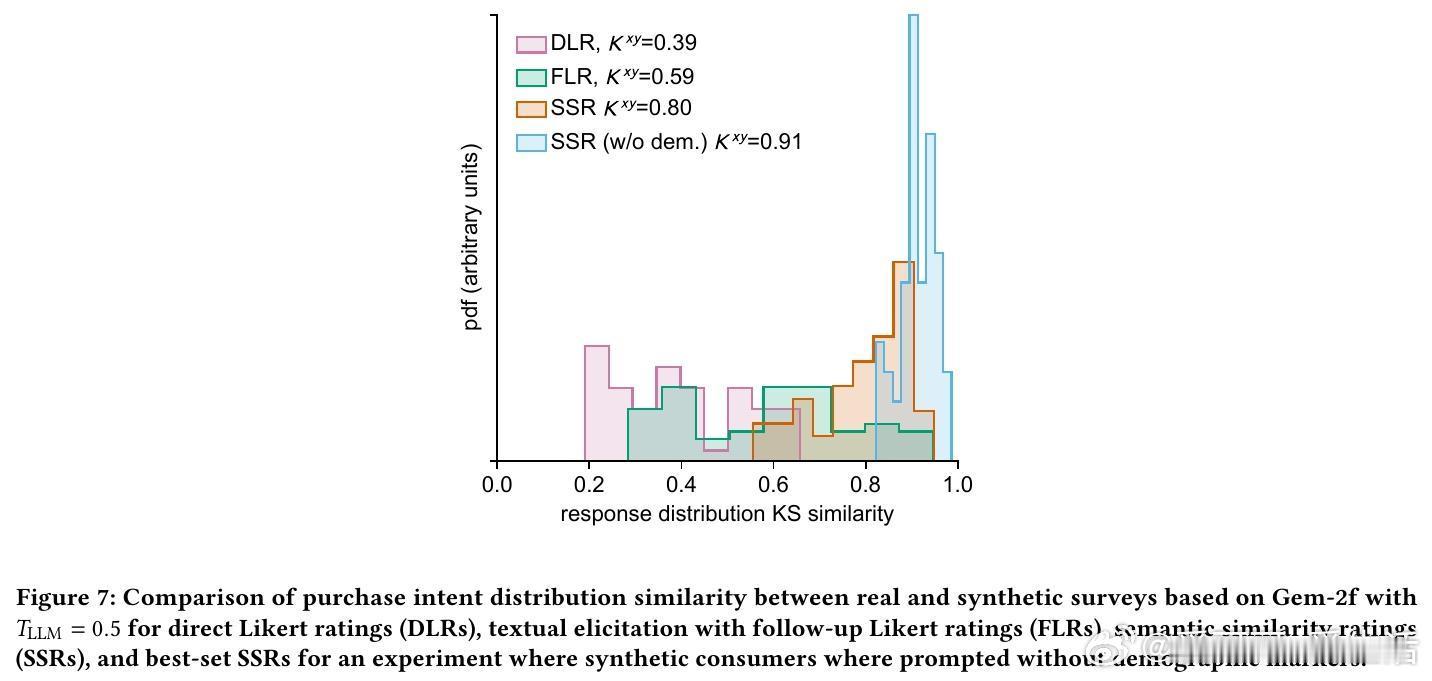
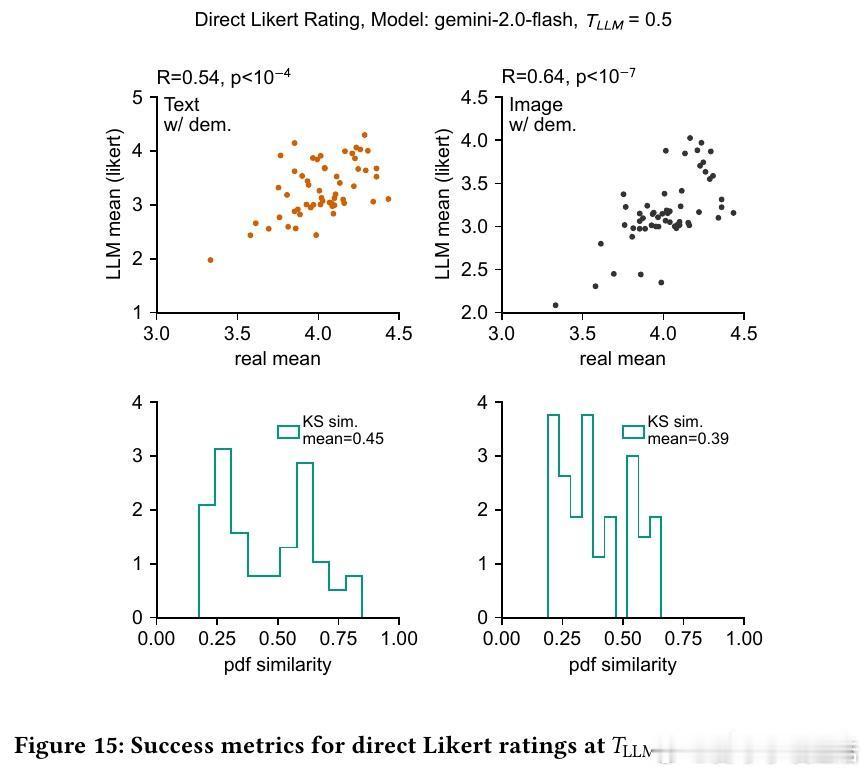
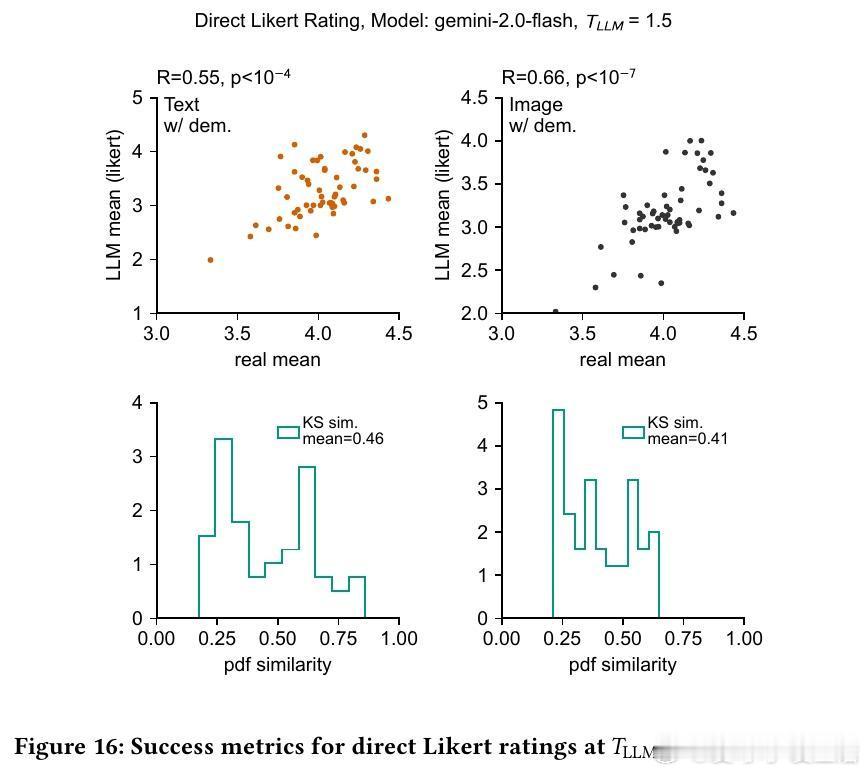
3/ 研究基于57个个人护理品调研(共9,300名真实消费者数据)进行测试。SSR方法达到90%的人类测试-重测可靠性,分布相似度KS相似度>0.85,表现远超直接评分方法。
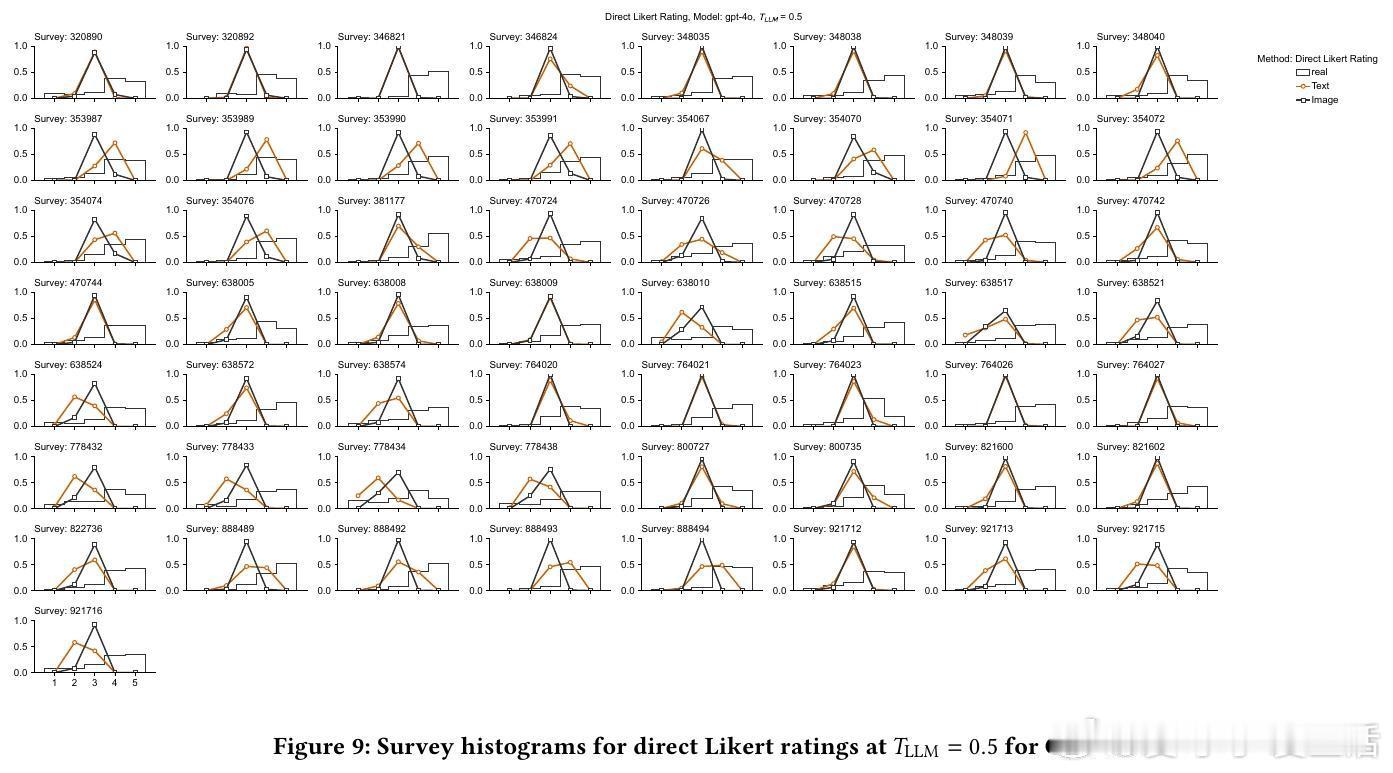
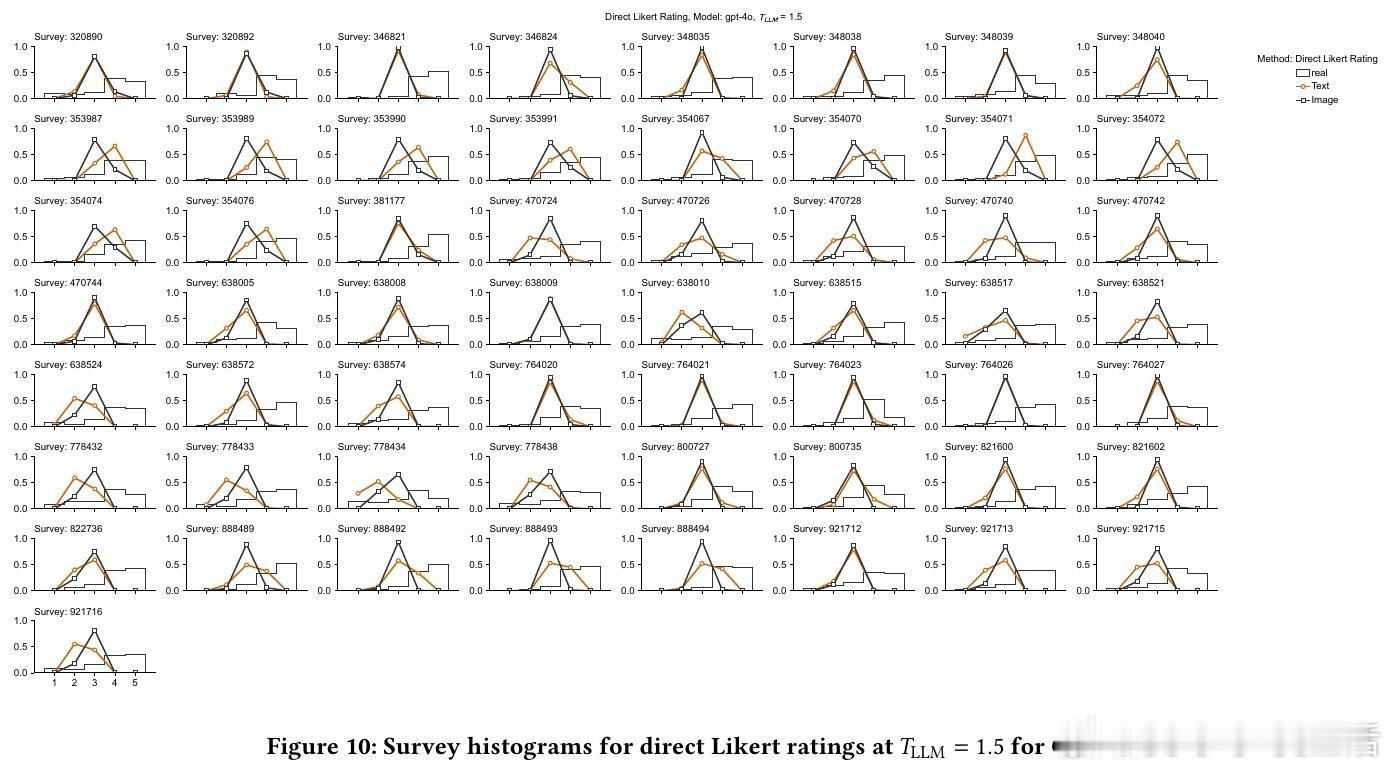
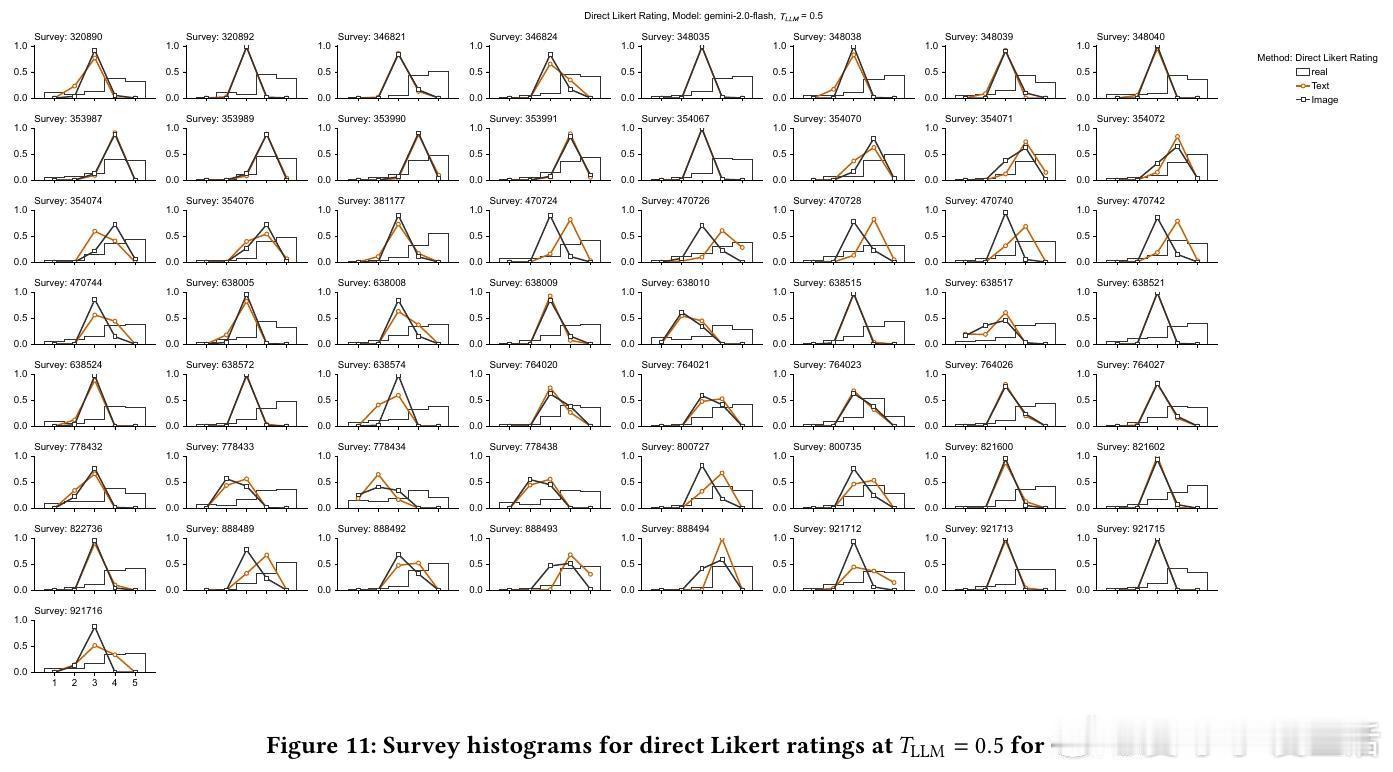
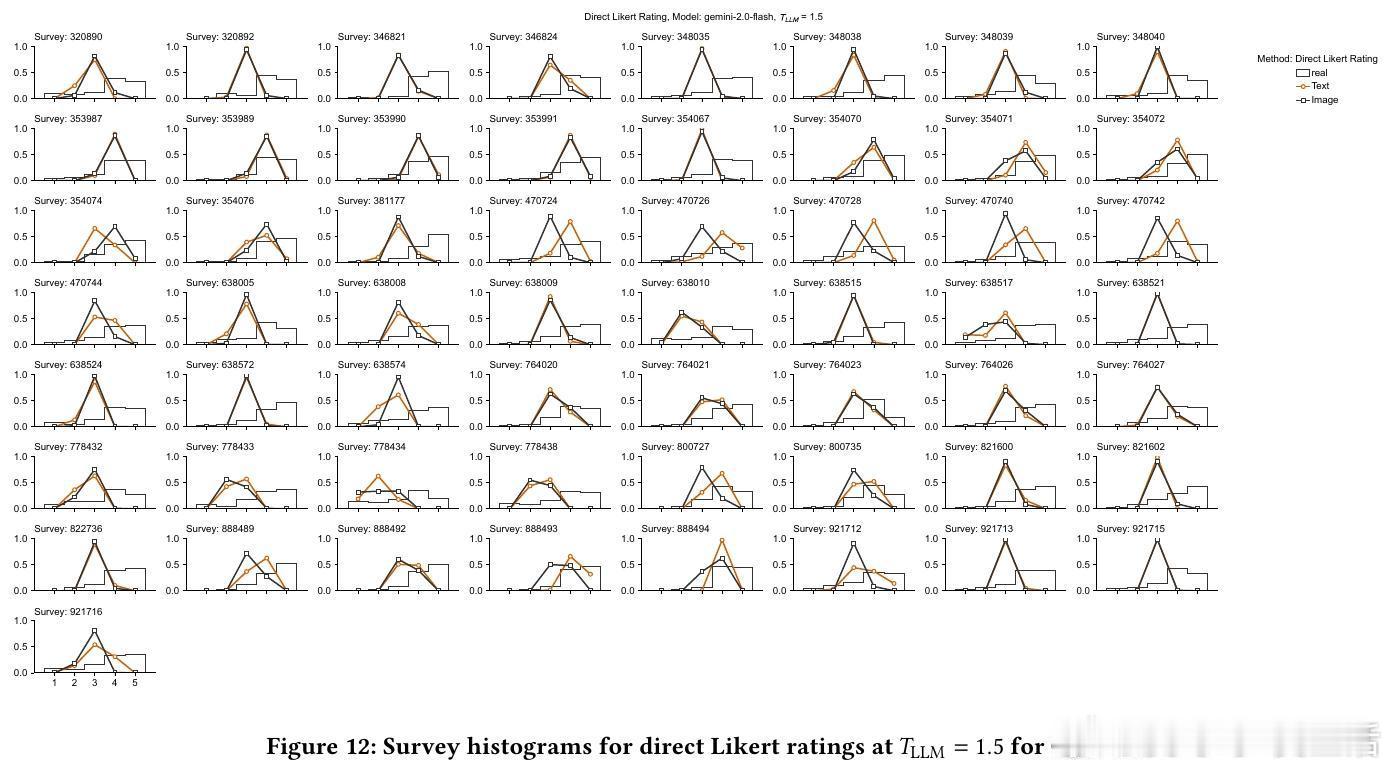
4/ 细节:直接评分模型往往聚焦中间值(3分),缺乏对1分和5分的合理输出,导致分布偏窄;SSR则还原了真实消费者分布的广度和偏态。
5/ 此外,SSR生成的文本反馈丰富具体,能揭示消费者对产品的喜好和顾虑,提供传统Likert评分无法比拟的定性洞察。
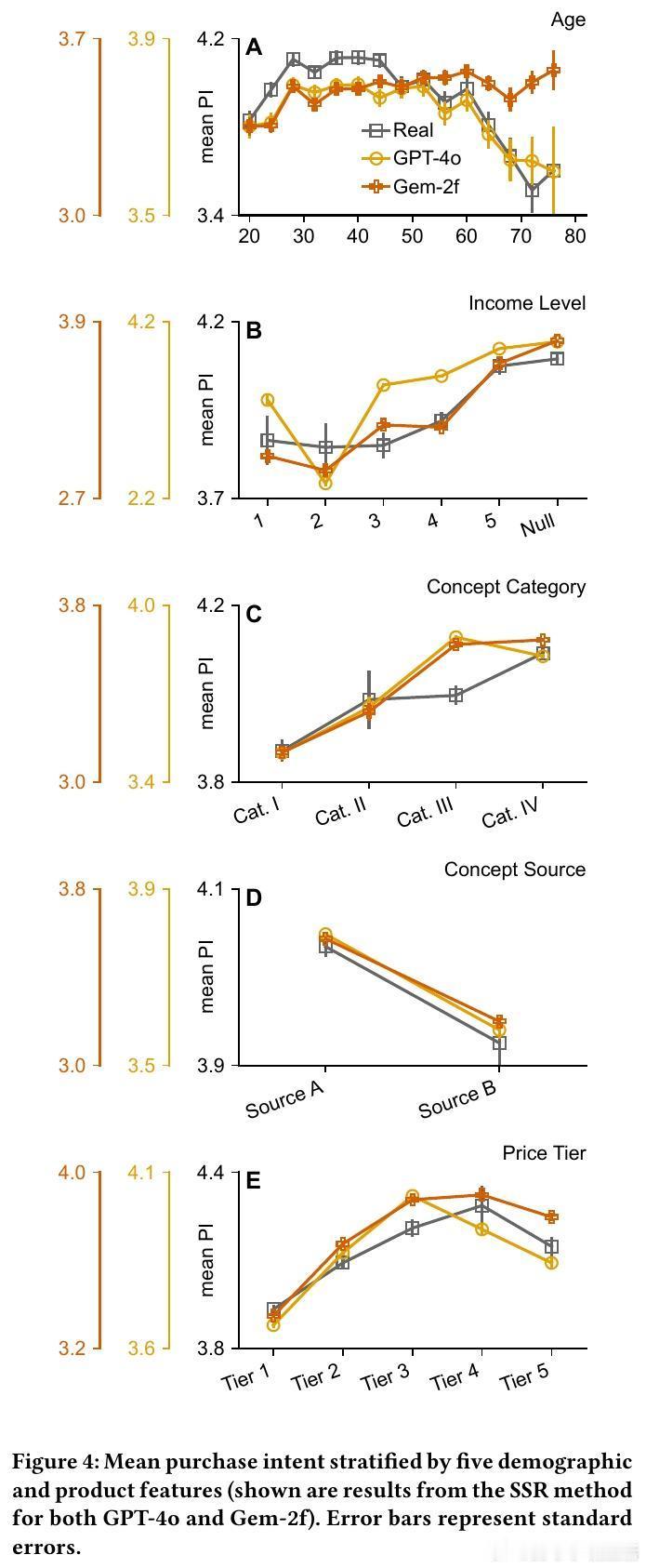
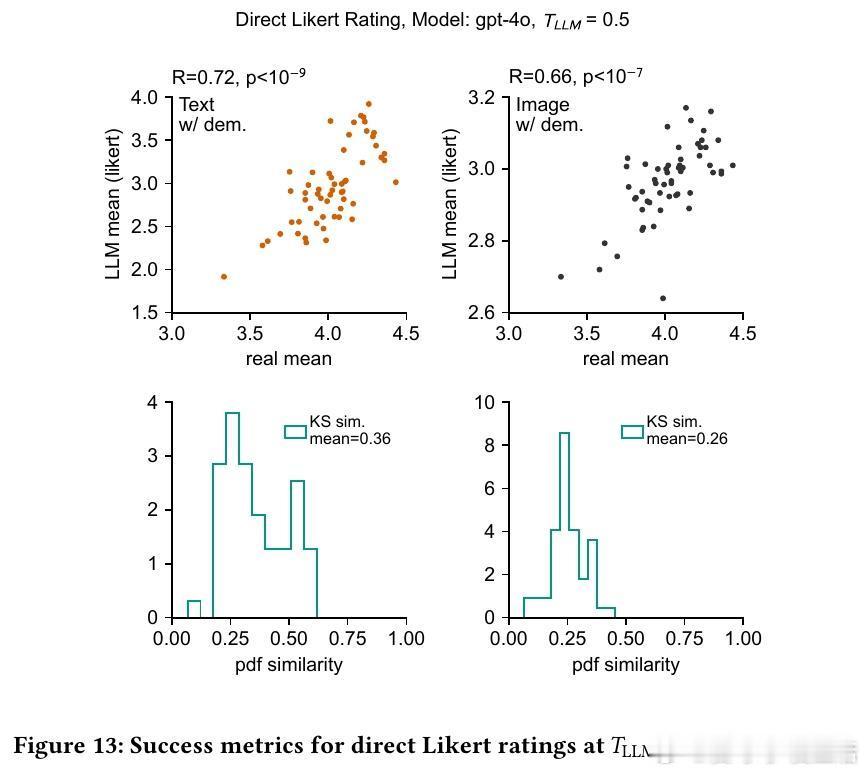
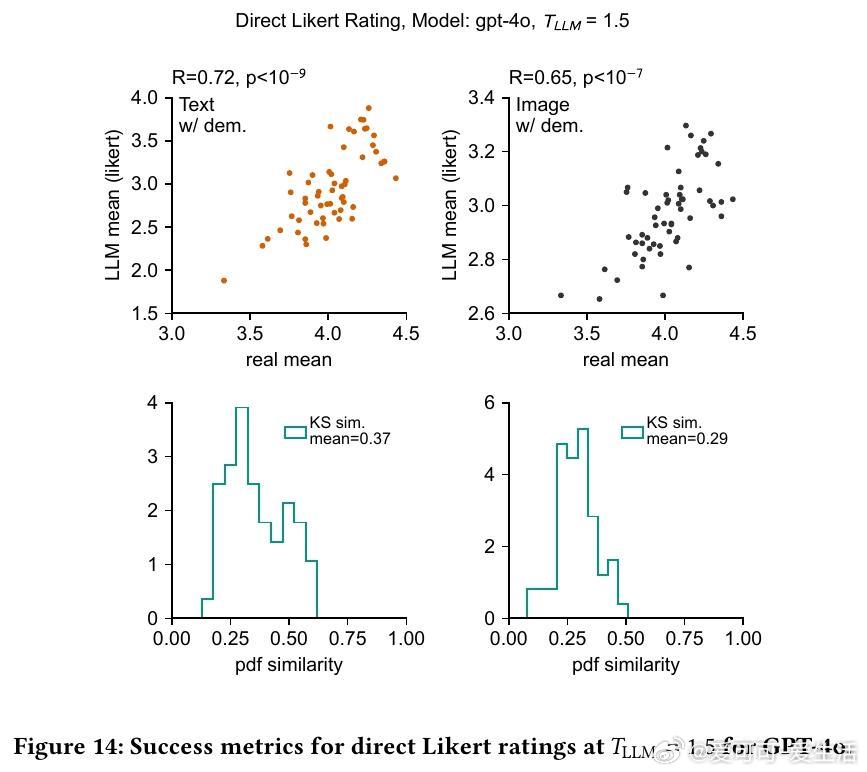
6/ 实验还发现,向LLM提示具体人口属性(年龄、收入)显著提升结果贴合度,且模型对年龄和收入的响应趋势与真实人类相似,表明模型有效利用了人口统计信息。
7/ 传统机器学习模型(如LightGBM)虽能部分复现分布,但在相关性和可靠性上明显不及SSR,凸显LLMs在无监督零样本条件下的强大泛化能力。
8/ SSR方法无需对模型进行额外训练或微调,成本低,易于推广。它为企业提供了一个可扩展、经济的消费者调研模拟工具,有望降低调研成本,加速产品迭代。
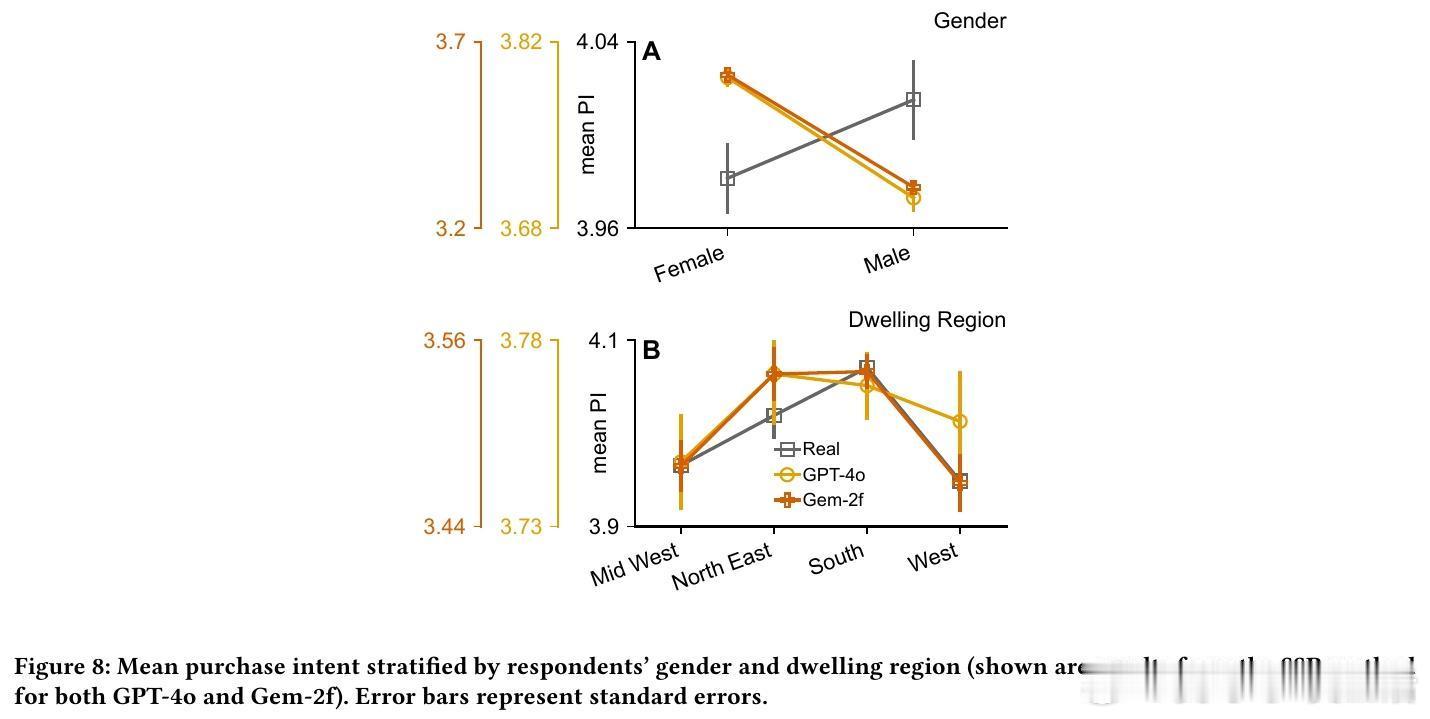
9/ 当然,SSR依赖于LLM训练数据的覆盖度,某些小众领域或新兴品类可能效果有限;且部分人口特征(如性别、地域)模拟尚不完美,需谨慎解读细分群体结果。
10/ 未来方向包括:扩展SSR至更多问卷指标(满意度、信任度等)、自动优化锚点语句、结合多轮文本生成和模型校准、以及与轻微微调技术结合,进一步提升真实感与解释力。
总结:SSR巧妙将自由文本与语义相似度结合,成功破解LLMs直接数值评分的局限,实现了高保真人类购买意愿模拟。它不仅重塑市场调研模式,也为AI赋能消费者洞察开辟新篇章。🚀
全文详见:
大语言模型 消费者调研 市场洞察 人工智能 自然语言处理 消费行为 产品开发