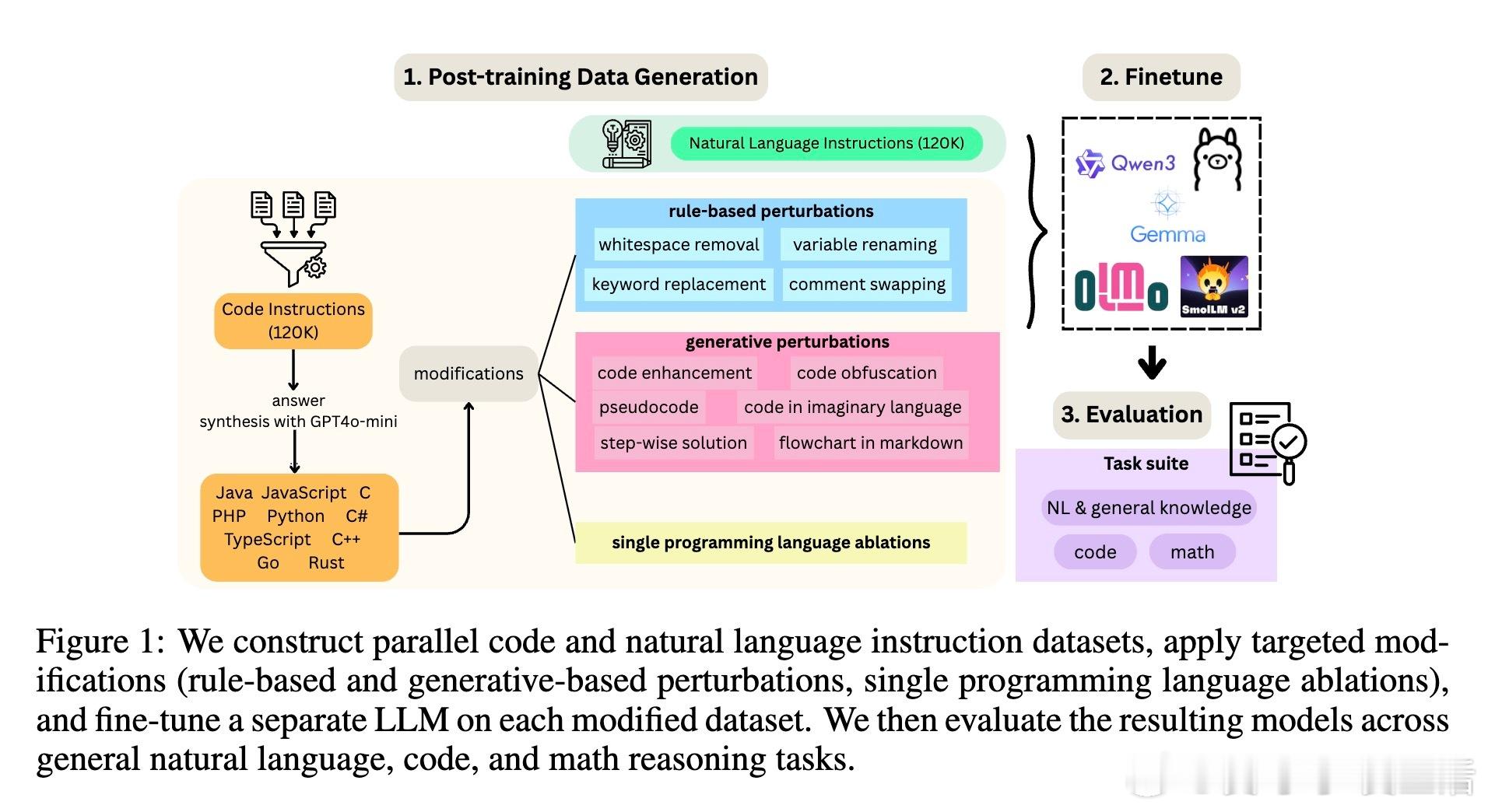
[CL]《On Code-Induced Reasoning in LLMs》A Waheed, Z Wu, C Rosé, D Ippolito [CMU] (2025)
大型语言模型(LLMs)为何“读代码”更聪明?一项覆盖5大模型家族、10编程语言、3,331次微调实验的系统研究揭示了关键:
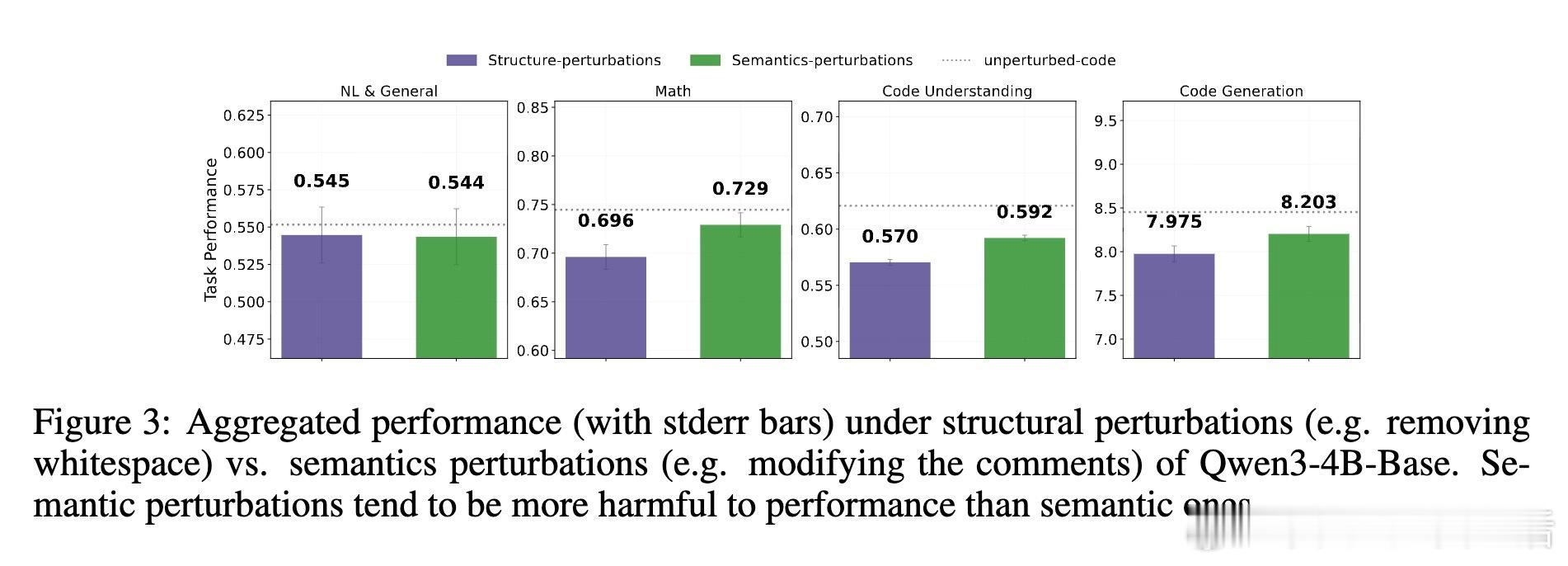
• 代码结构比语义更关键,尤其在数学和代码任务上,格式破坏(如空白删除)比注释混乱影响更大。
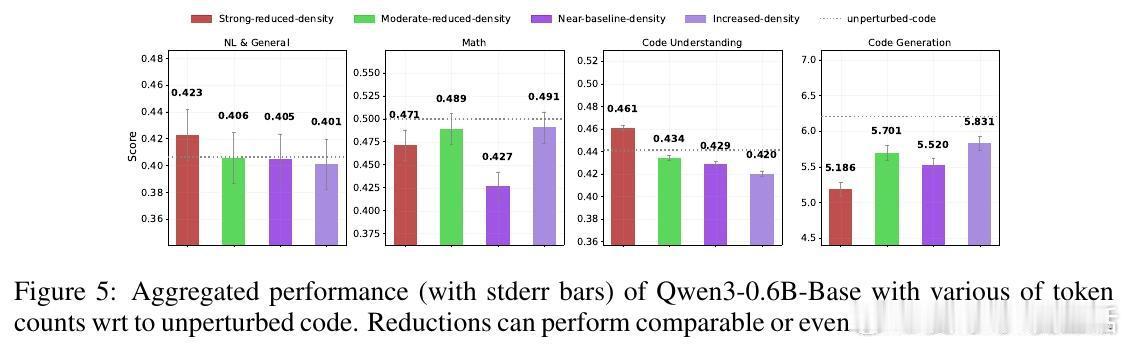
• 抽象表达(伪代码、流程图)同样有效,且用更少token,甚至能提升推理表现,说明模型不依赖具体语法,而是抓取底层结构。
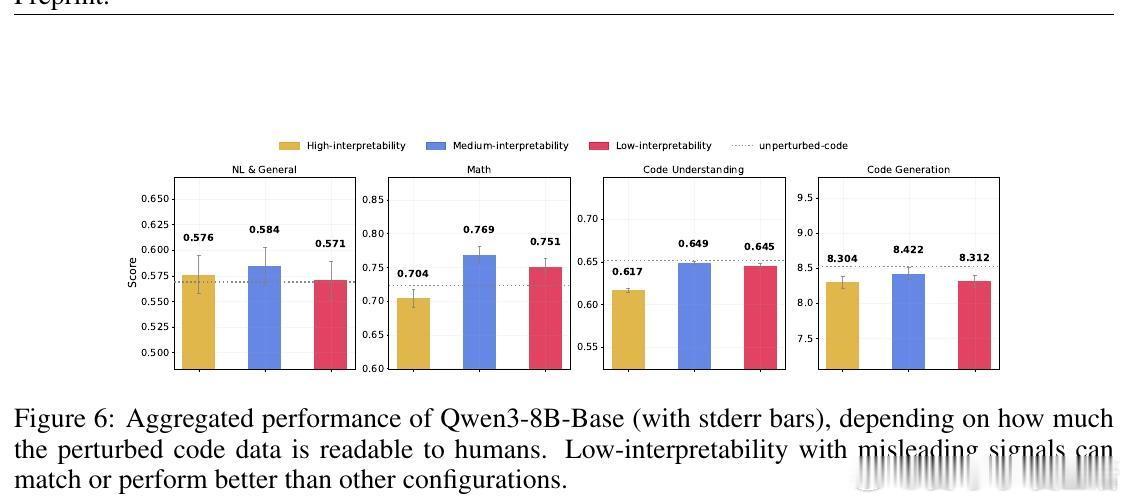
• 模型对表面模式极具鲁棒性,即使代码被故意破坏或注释误导,仍能保持竞争力。
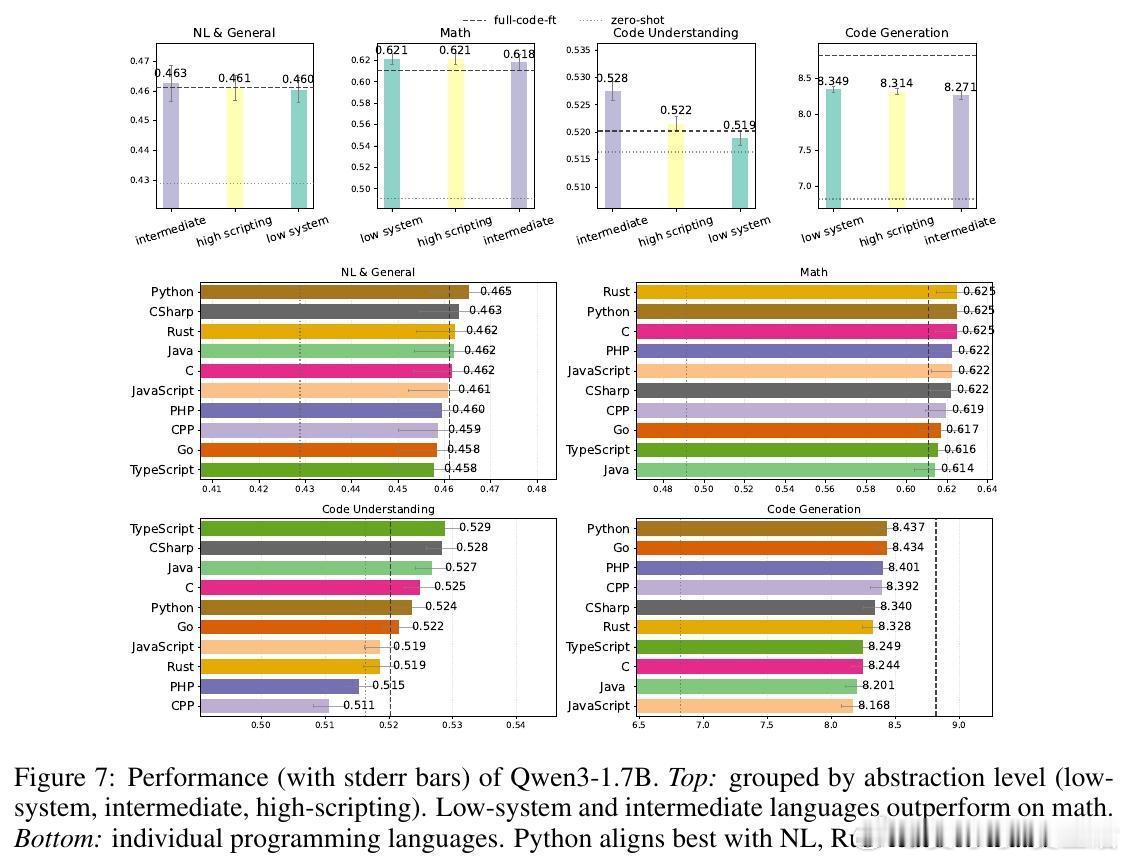
• Python语法更利于自然语言推理,低级语言如Java、Rust则助力数学推理,体现语言风格对任务的适配性。
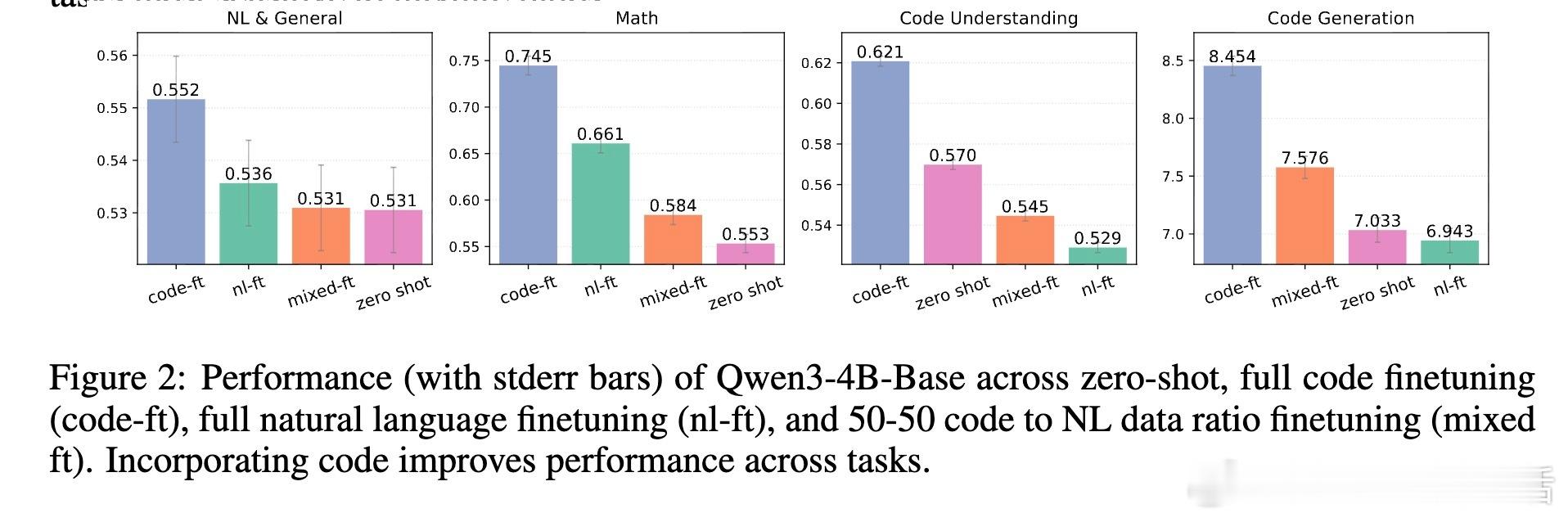
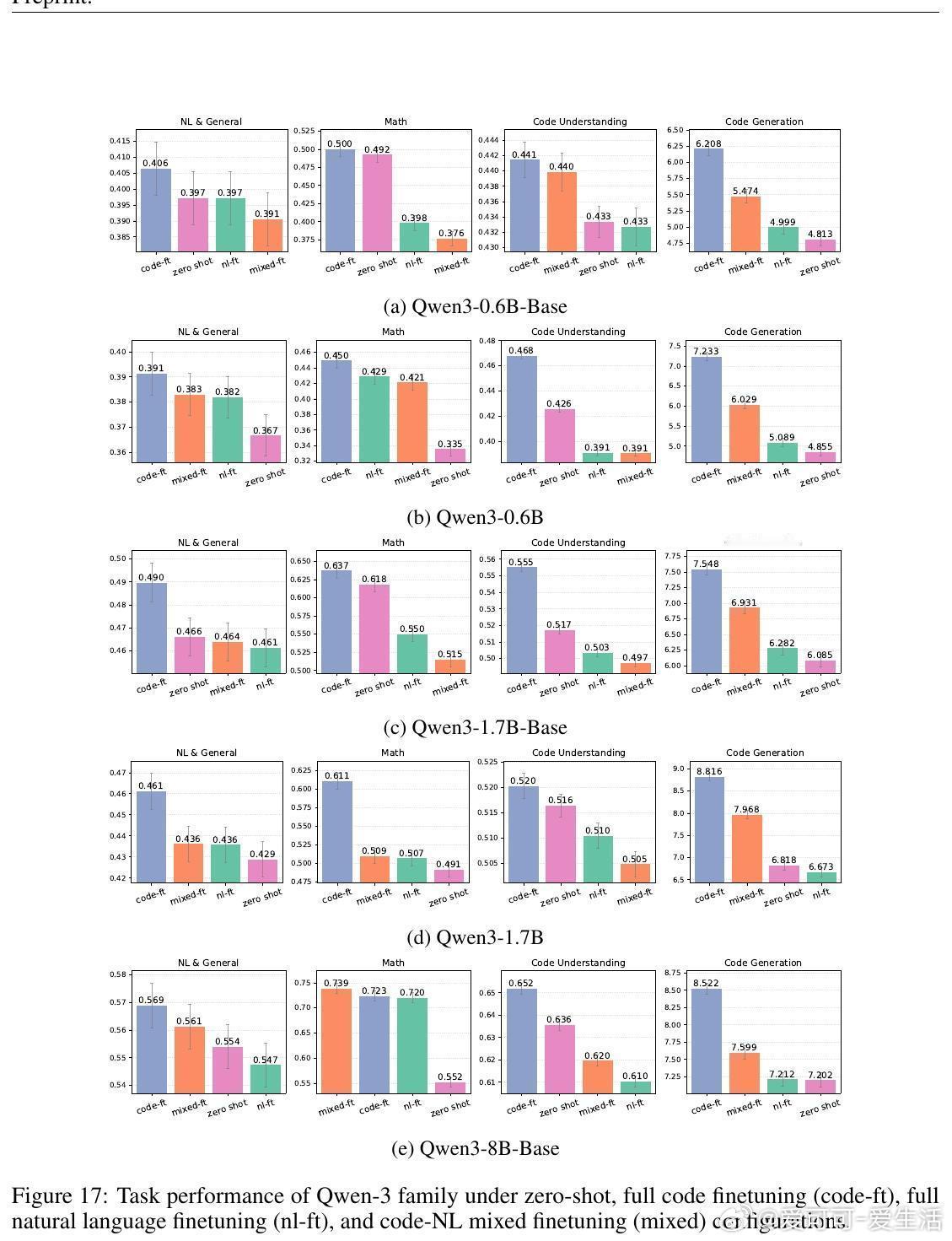
• 代码数据比例越高,整体推理表现越好,数学任务对此尤为敏感。
心得:
1. 结构化信息是提升推理的核心,简洁明确的代码框架比冗长注释更重要。
2. 适当抽象能减少训练成本,维持甚至提高模型理解和生成能力。
3. 多语言代码混合训练优于单一语言,丰富表达助力模型泛化。
想深挖如何设计训练数据、提升模型推理力?详见研究全文🔗arxiv.org/abs/2509.21499
大语言模型 代码推理 机器学习 人工智能 模型微调