[LG]《StepWiser: Stepwise Generative Judges for Wiser Reasoning》W Xiong, W Zhao, W Yuan, O Golovneva... [FAIR at Meta] (2025)
STEPWISER:一步步生成式评判模型,助力更精准的多步推理质量把控
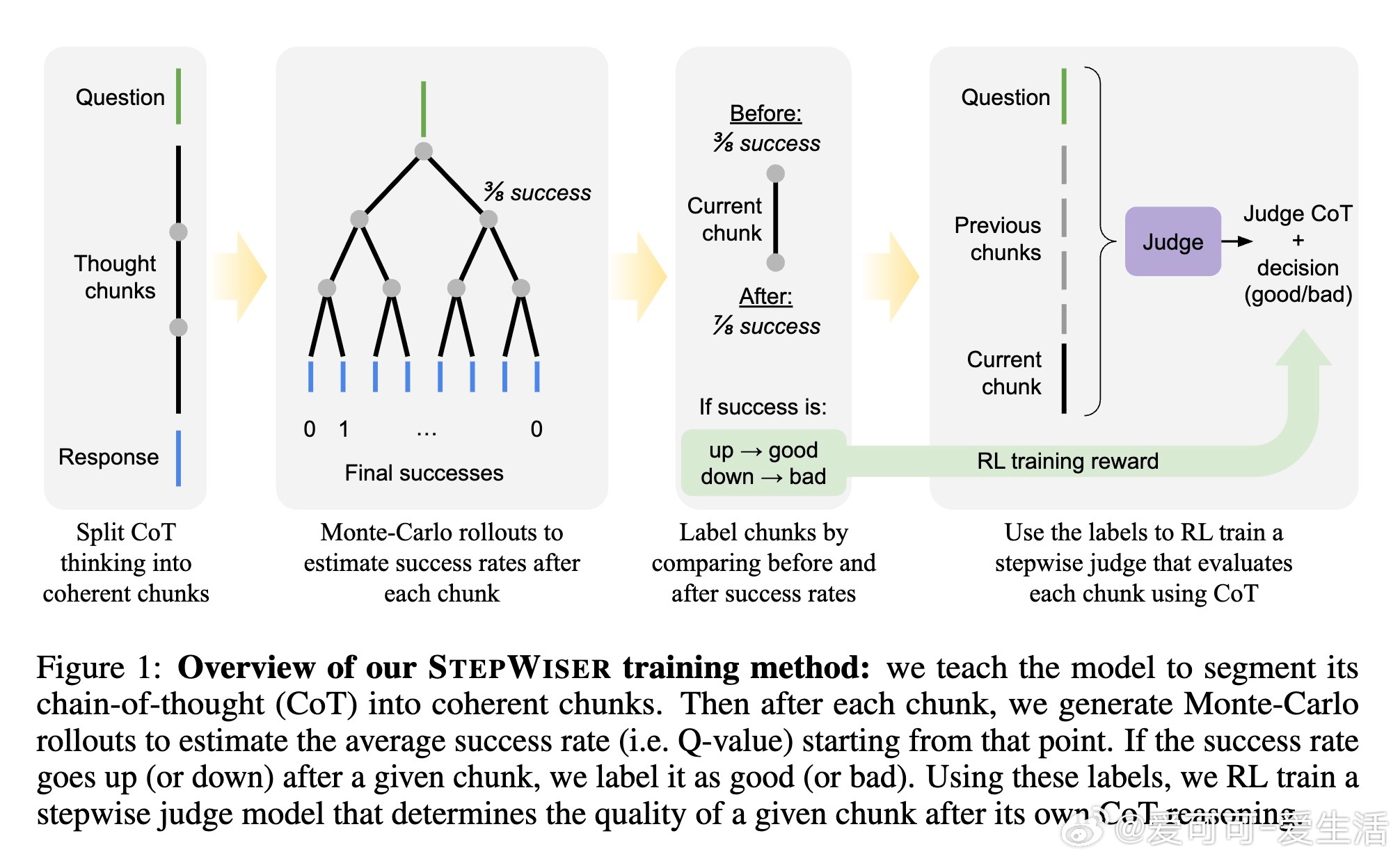
• 重新定义过程奖励模型,将中间推理步骤的评判转换为推理任务本身,实现“对推理的推理”。
• 创新自我分段技术,令基础策略模型生成逻辑连贯、信息丰富的推理块(Chunks-of-Thought),增强步骤的独立性与完整性。
• 采用蒙特卡洛回滚估计每步的相对成功概率,基于步骤前后成功率变化标注标签,构建密集、在线的强化学习信号。
• 通过GRPO算法强化训练生成式评判模型,先生成推理链条解释,再给出最终判断,兼具透明度和判别力。
• 在ProcessBench基准测试中,STEPWISER在7B模型下达成61.9分,显著超越传统基于监督微调的判别模型(39.7分)和稀疏轨迹级RL模型。
• 推理时支持分块重置搜索,自动剔除错误步骤,提升解题准确率(最高提升至63.3%),同时保证解答长度稳定。
• 训练时利用STEPWISER筛选高质量自生成数据,提升下游模型表现,优于基于最终答案奖励的筛选策略。
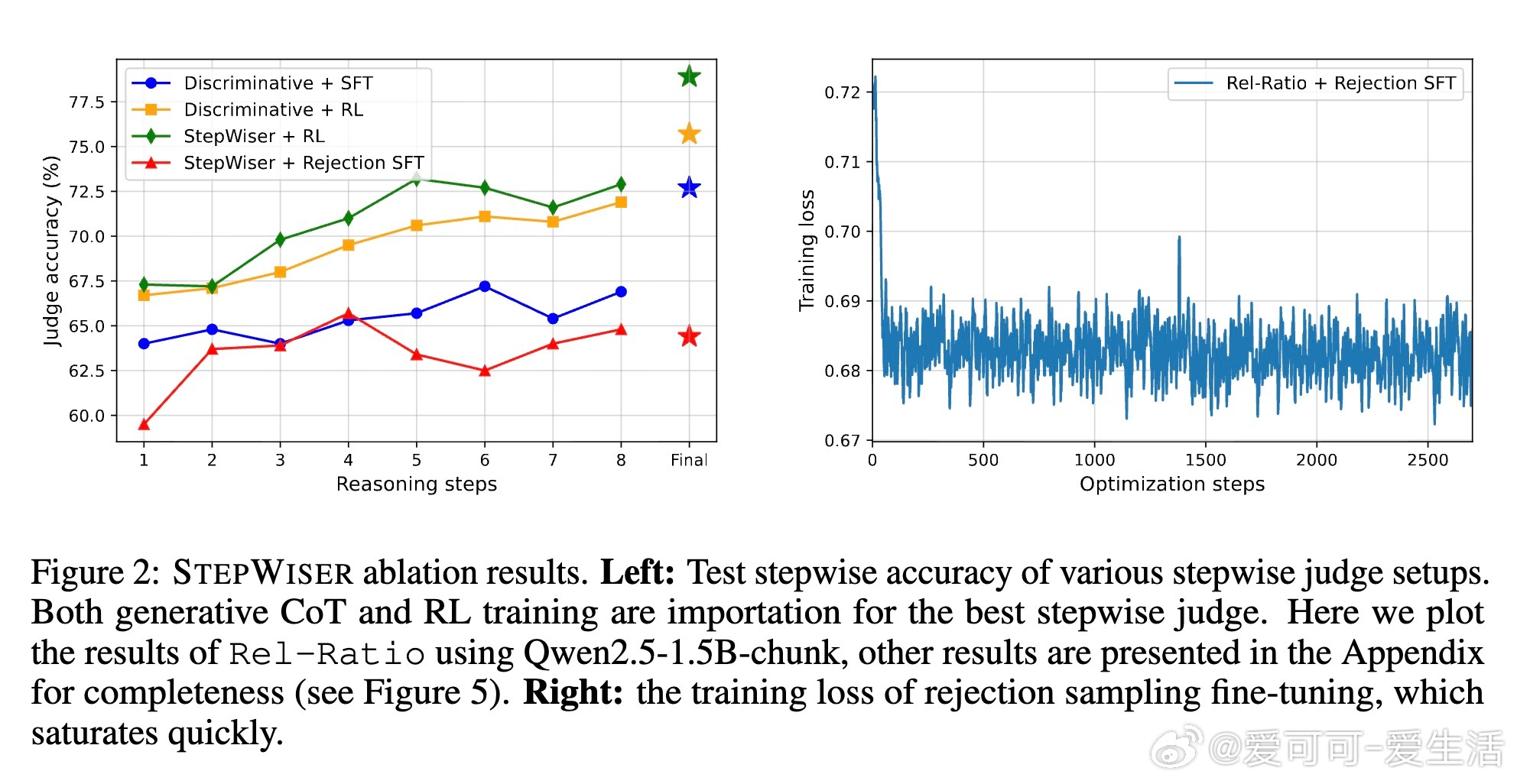
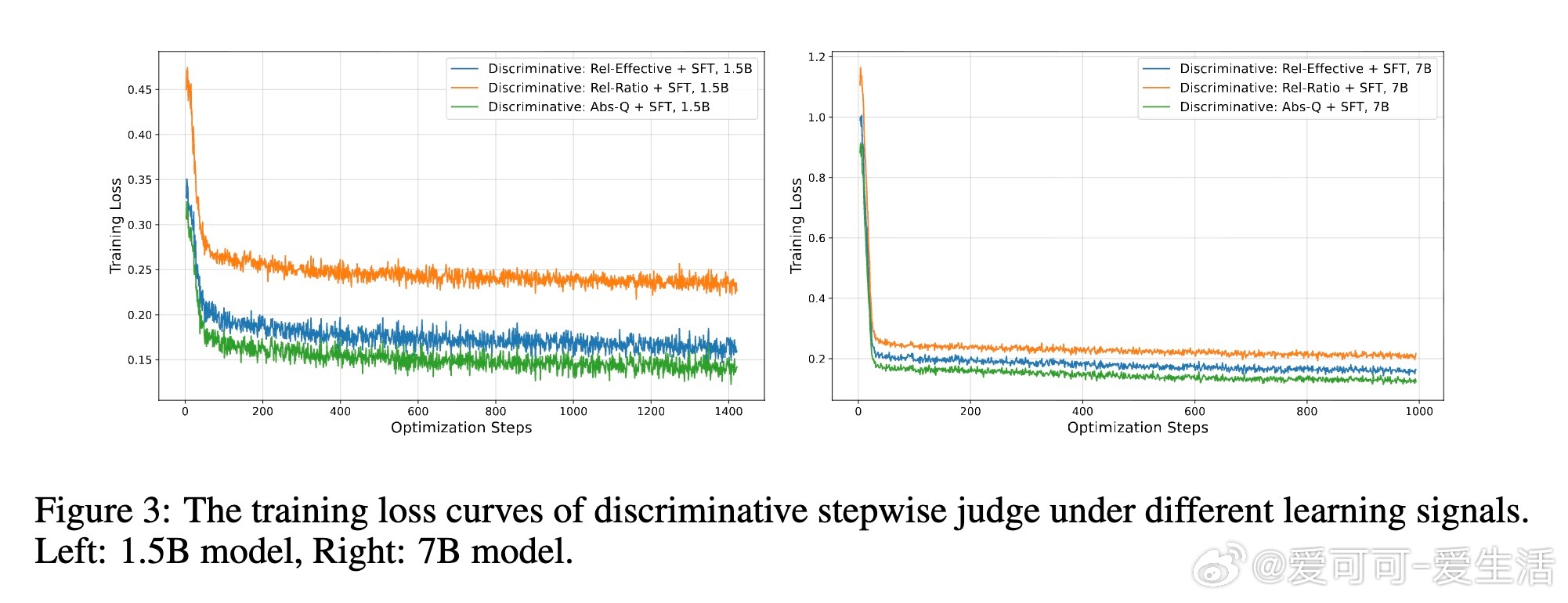
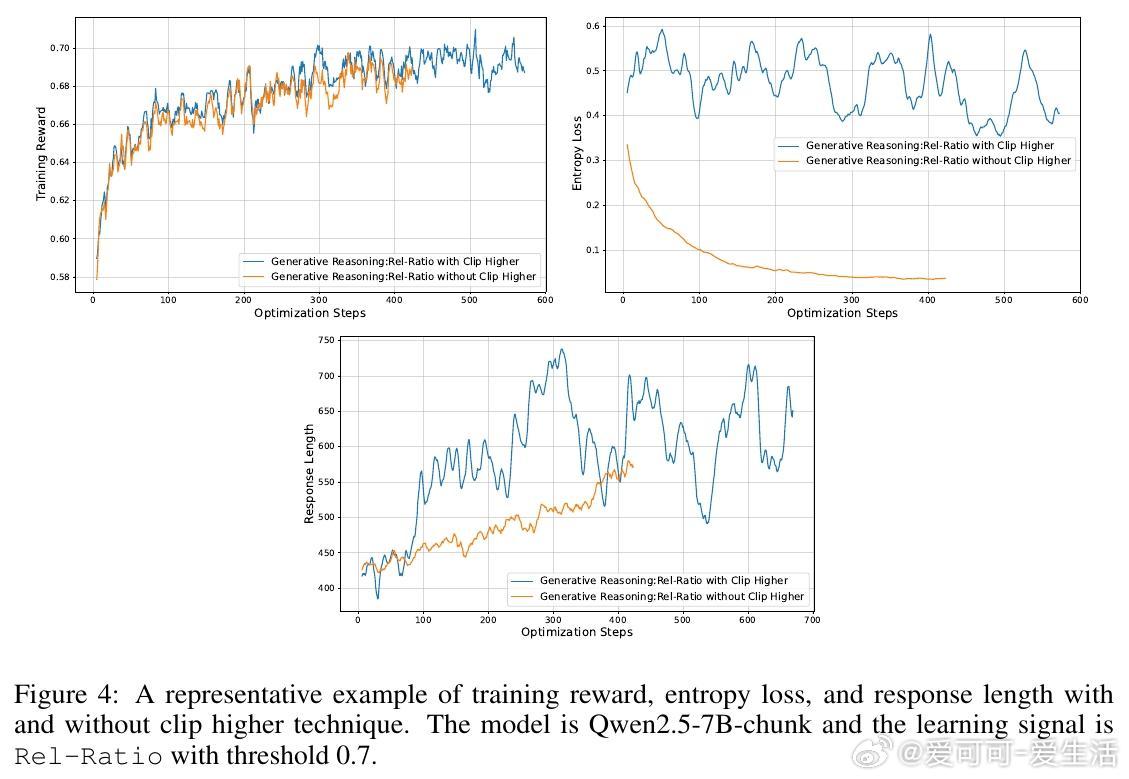
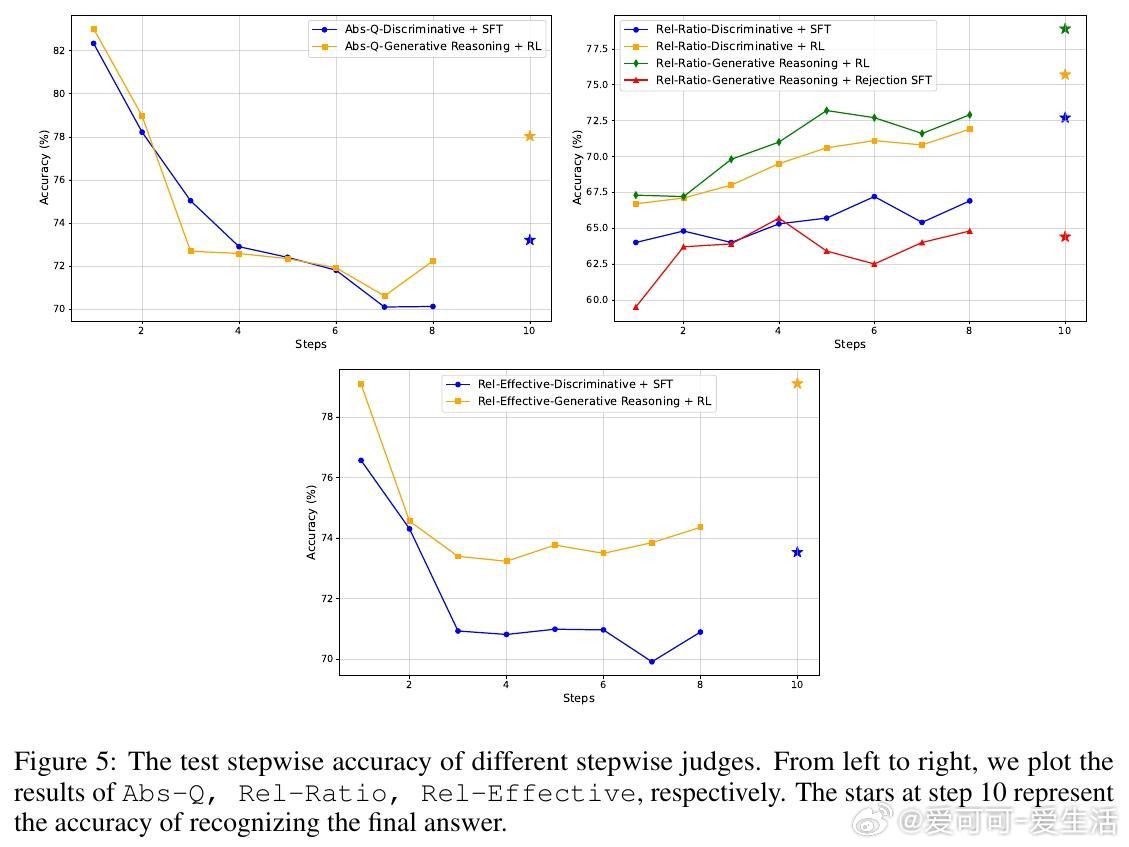
• 研究表明,生成式推理判决与在线强化学习的结合是性能跃升的关键,且相对奖励信号(Rel-Effective、Rel-Ratio)优于绝对质量阈值(Abs-Q)。
• 自我分段显著减少推理步骤数量(约减40%),节省计算与标注资源,促进高效训练。
STEPWISER通过“推理中的推理”,为多步推理任务提供更细粒度、更准确的质量评判与反馈机制,推动复杂问题求解能力的跨越式提升。
详情🔗arxiv.org/abs/2508.19229
人工智能大模型强化学习多步推理生成式模型模型评判