BeyondWeb:打破LLM预训练数据壁垒的合成数据新范式
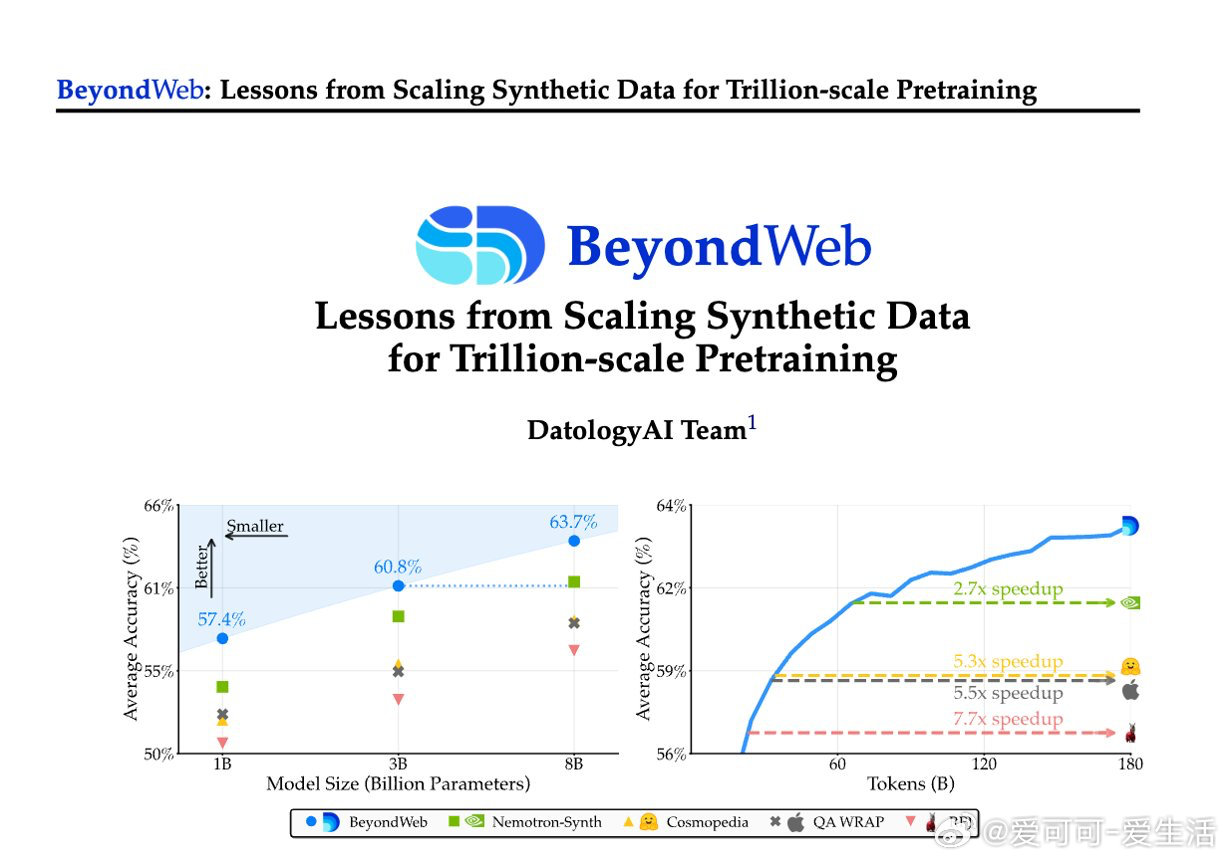
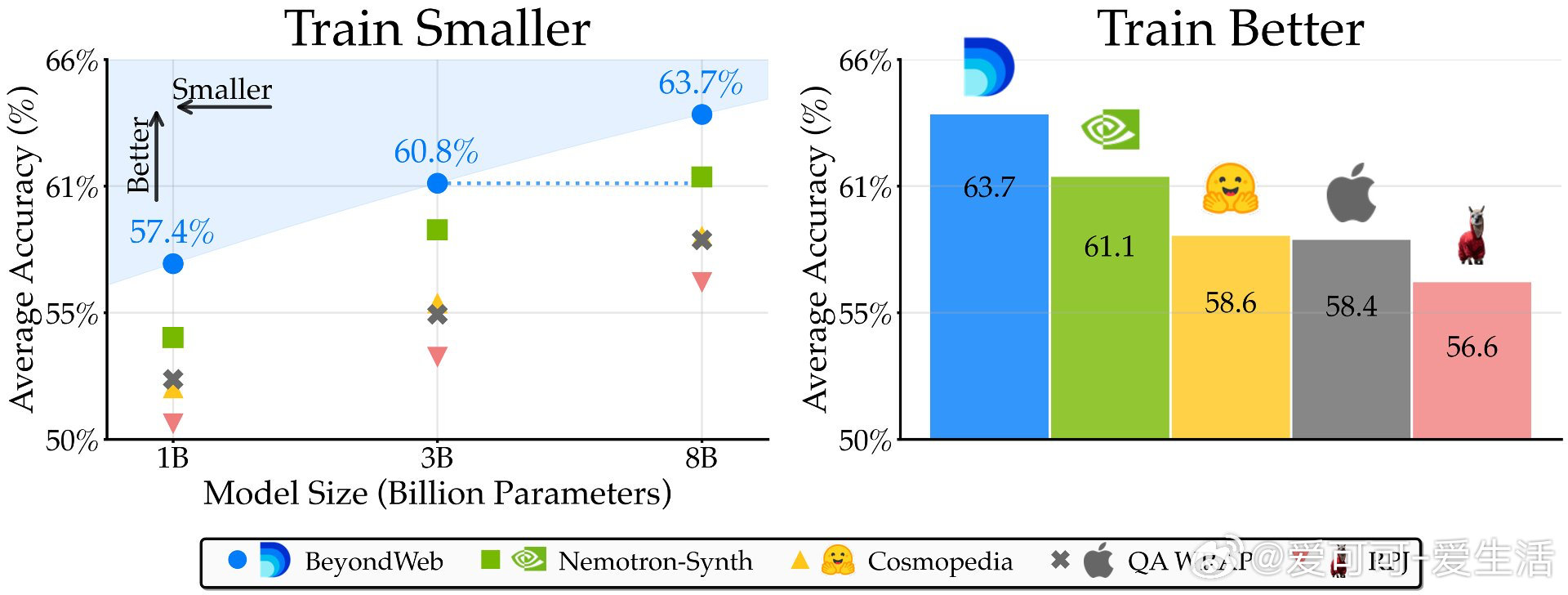
• 预训练遇到数据壁垒,单纯扩大网络抓取数据规模收益递减。BeyondWeb通过合成数据创新,实现3B参数模型性能超越多数8B基线,开辟性能-效率Pareto前沿。
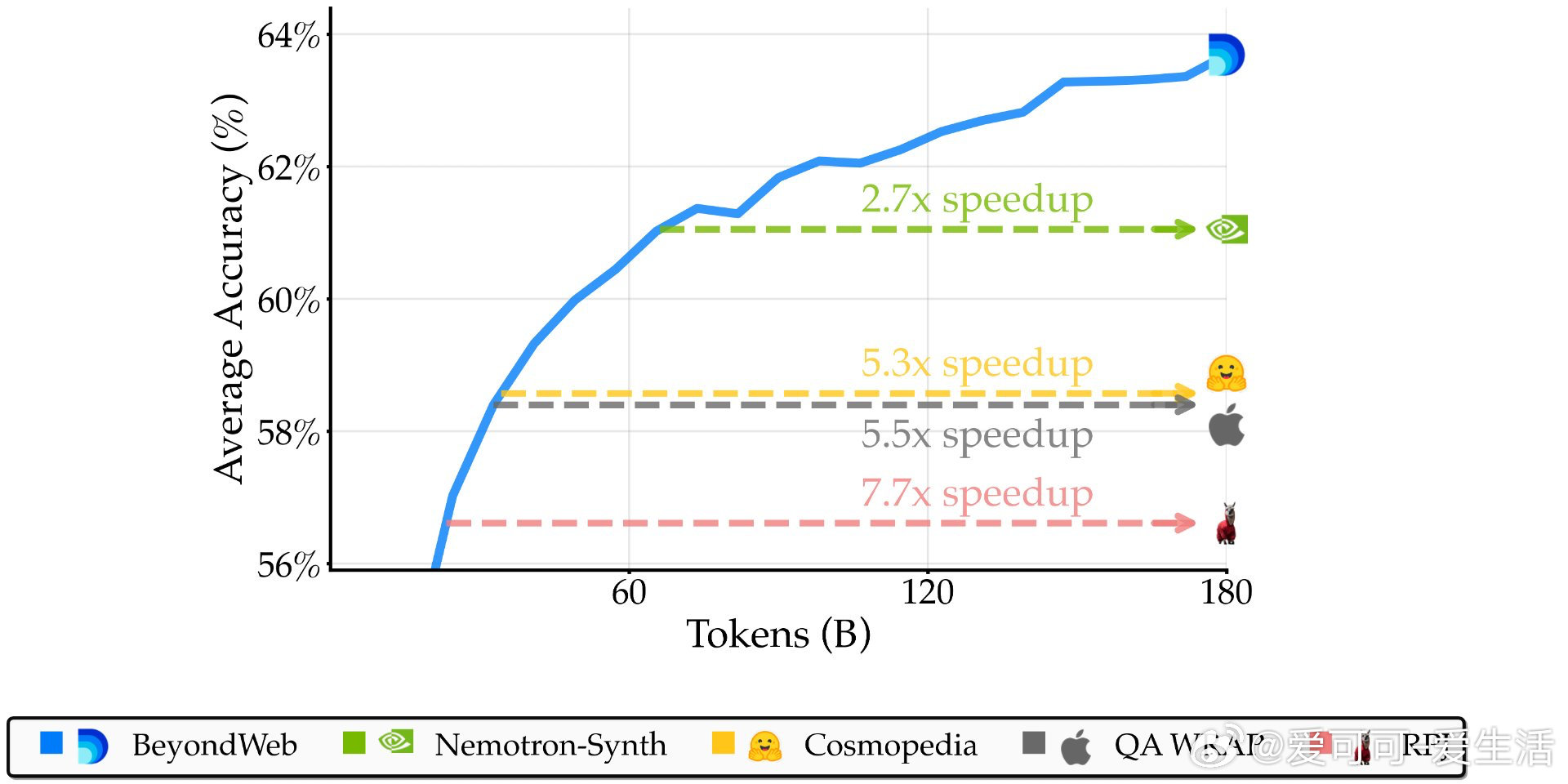
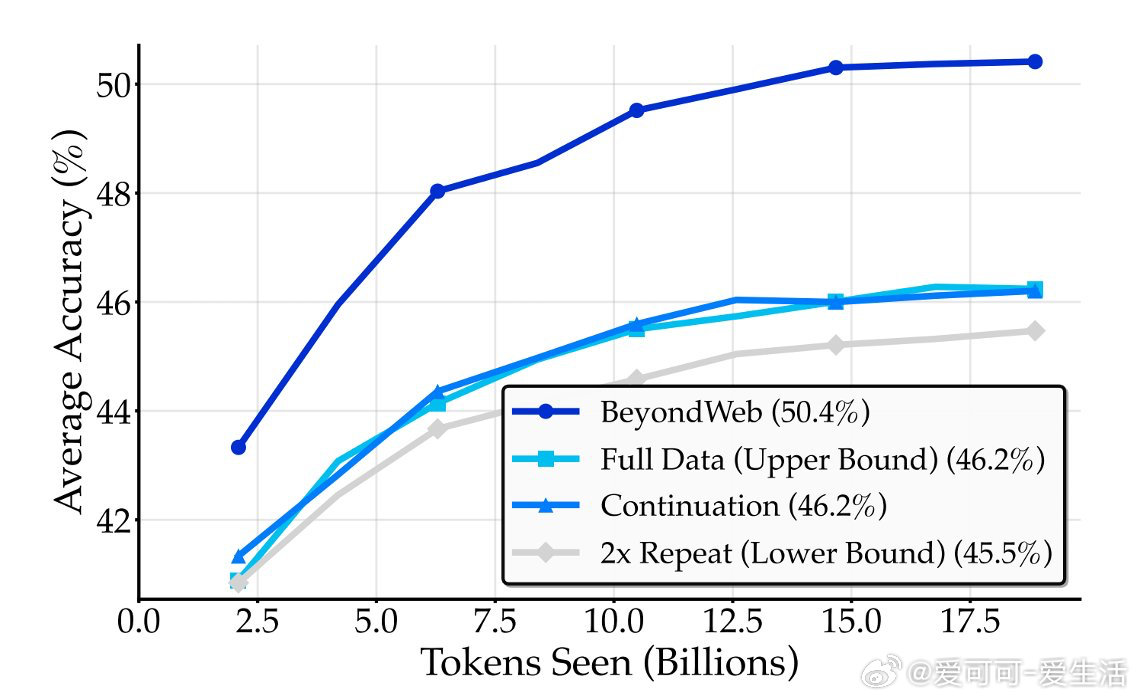
• 超越主流合成数据集:BeyondWeb在14项基准测试中平均领先Cosmopedia超5.1个百分点,领先Nemotron-Synth超2.6个百分点,训练速度提升超过2.7倍,最高达7.7倍。
• 关键洞见:
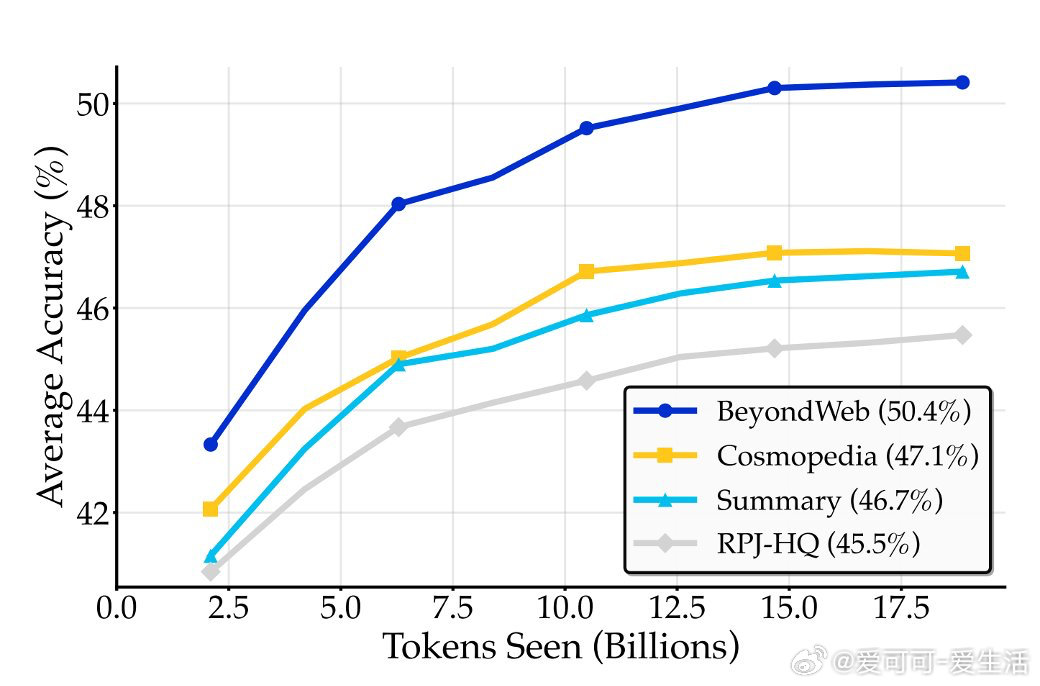
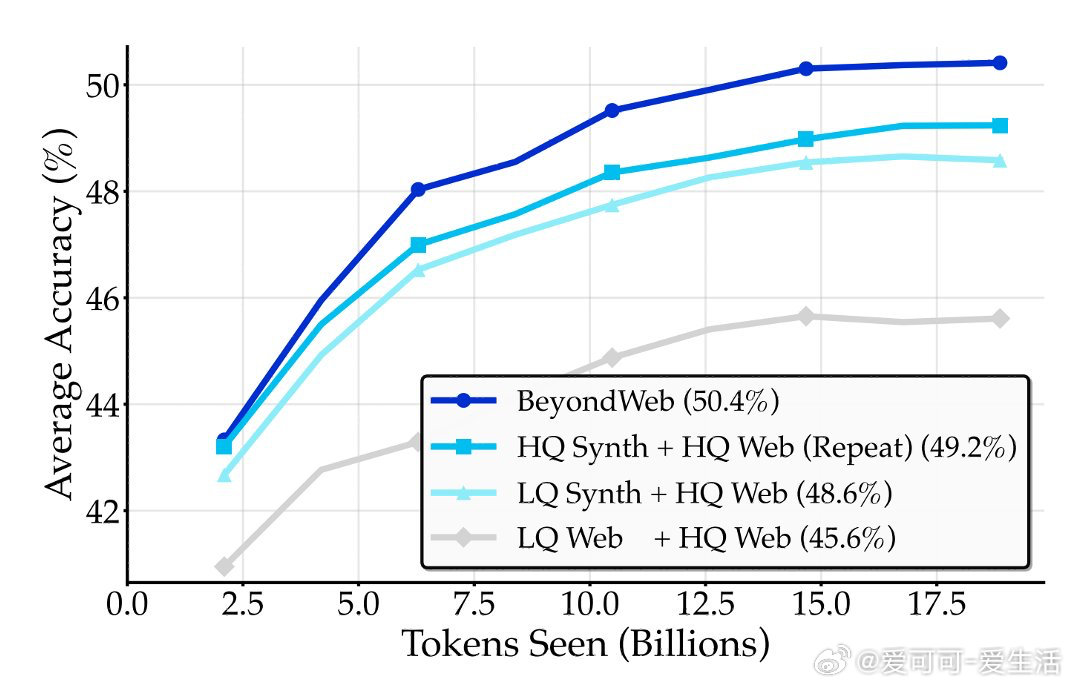
- 合成数据非单纯知识蒸馏,简单摘要可近似生成器驱动方法,但BeyondWeb通过精心设计的文档重述策略实现明显超越。
- 盲目扩展或重复数据难以打破数据壁垒,只有针对性填补数据分布空白的合成数据才能突破极限。
- 高质量种子数据对合成效果至关重要,优质数据重述优于低质数据生成,质量重于新颖性。
- 训练数据风格匹配(尤其是对话风格)有助提升下游性能,但收益迅速递减,非充分条件。
- 多样性策略能持续带来训练收益,固定风格合成数据易饱和,BeyondWeb多策略生成保持长期增益。
- 合成数据生成对重述模型家族鲁棒,模型质量与合成数据质量相关性极低,选用合适的小型模型即可高效生成。
- 重述模型规模提升到3B参数带来明显收益,超过8B参数边际效应递减,支持低成本扩展。
• 实践价值:BeyondWeb已应用于7万亿tokens规模预训练数据集构建,为产业界提供可扩展、高效、低成本的数据生成路径,助力模型训练民主化。
更多详情与实验数据请见:
博客👉 blog.datologyai.com/beyondweb
论文👉 arxiv.org/abs/2508.10975
大语言模型 合成数据 预训练 数据壁垒 机器学习 人工智能