[CL]《Representing Speech Through Autoregressive Prediction of Cochlear Tokens》G Tuckute, K Kotar, E Fedorenko, D L.K. Yamins [MIT & Stanford University] (2025)
AuriStream:以生物学启发的两阶段自回归预测框架,革新语音表示学习
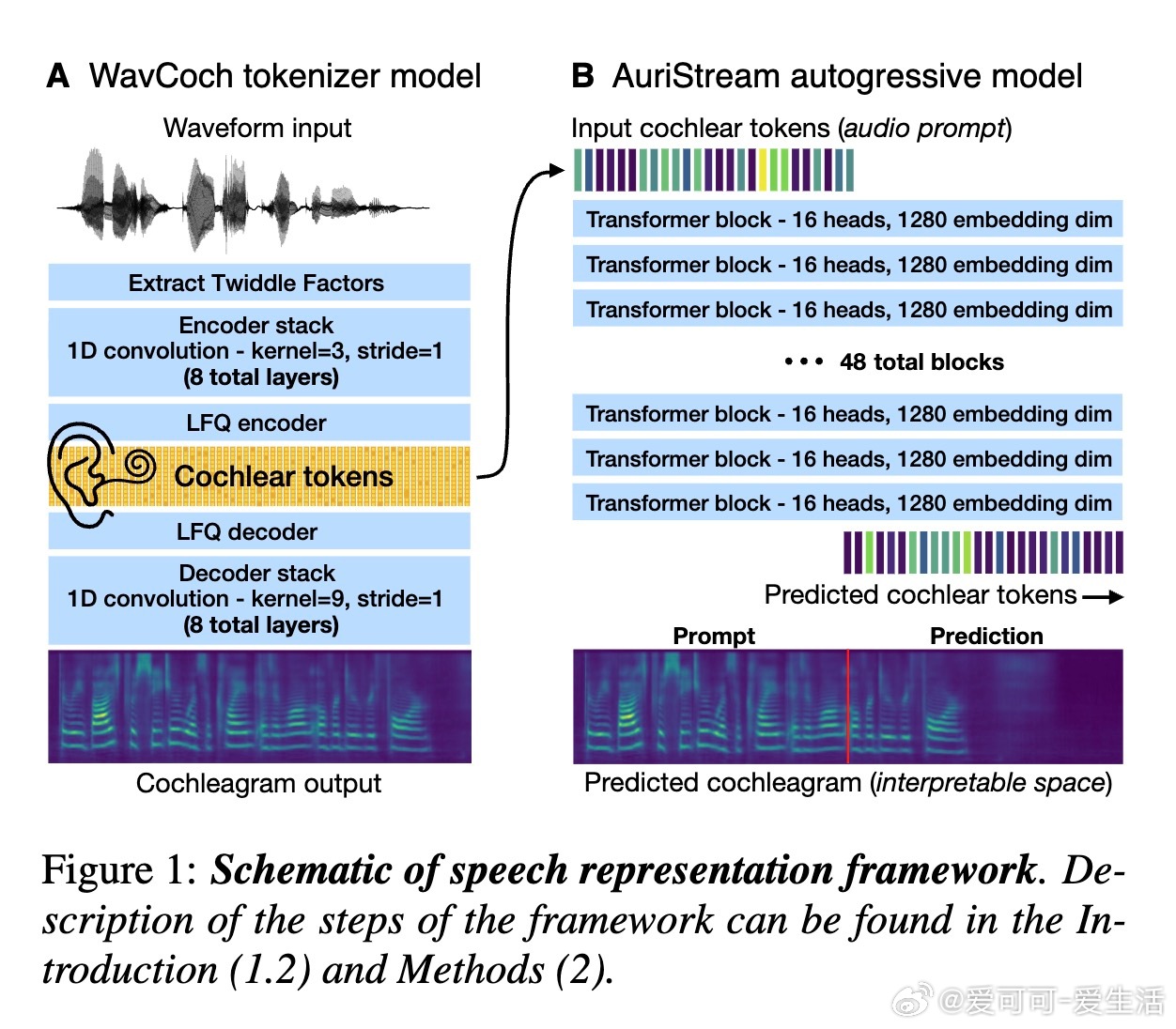
• 首阶段WavCoch将原始音频转换为基于人类耳蜗的时频表示——cochleagram,提取离散的cochlear tokens(8192词汇量,13-bit编码),高效且符合生物机制。
• 次阶段AuriStream为GPT风格自回归Transformer,基于cochlear tokens预测下一个音频片段,支持长达约20秒的语音上下文,训练于60K小时LibriLight数据。
• 表征能力覆盖音素识别、词识别及词汇语义,语义相似性指标(sSIMI)在自然及合成音频集均超越HuBERT、WavLM等先进模型,实现词义层面最优表现。
• 在SUPERB语音任务基准上,AuriStream-1B在自动语音识别、意图分类、语音分离等多个任务表现优异,接近包含复杂手工设计的顶尖模型。
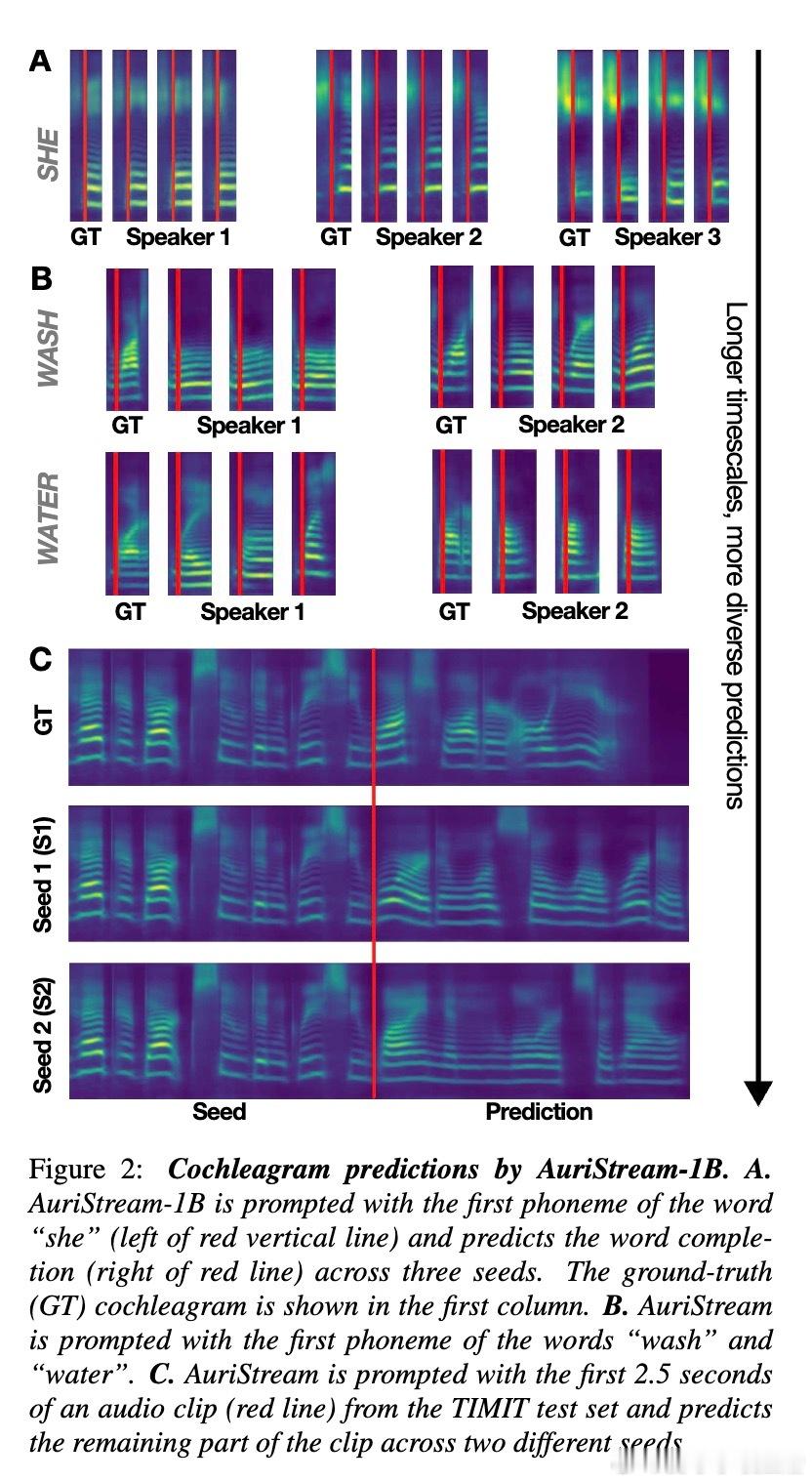
• 独特优势在于可生成音频连续片段,通过cochleagram反演听觉级别输出,提供语音预测的可视化与解释,突破传统黑箱模型限制。
• 研究揭示AuriStream能捕获语音的短期结构(完成词内音素序列)与长期多样性(多种合理词序列预测),体现对语音统计规律的深刻学习。
• 该框架避免传统重构、非因果预测或对比学习的生物不合理性,提出“Transformation Imitation”理念,将一种生物启发的音频表示转化为另一种,简洁且高效。
• 限制包括目前仅训练于英语朗读语料,未来将扩展至更自然和多样的语音数据,助力构建更接近人类听觉处理的神经网络模型。
论文🔗
探索详情与试听样本👉 tukoresearch.github.io/auristream-speech/
语音表示学习自回归模型人工智能深度学习神经网络听觉认知