[CL]《Diffusion is a code repair operator and generator》M Singh, G Verbruggen, V Le, S Gulwani [Microsoft] (2025)
Diffusion模型在代码修复领域展现新潜力,通过迭代去噪latent表示,实现“最后一公里”修复与训练数据生成。
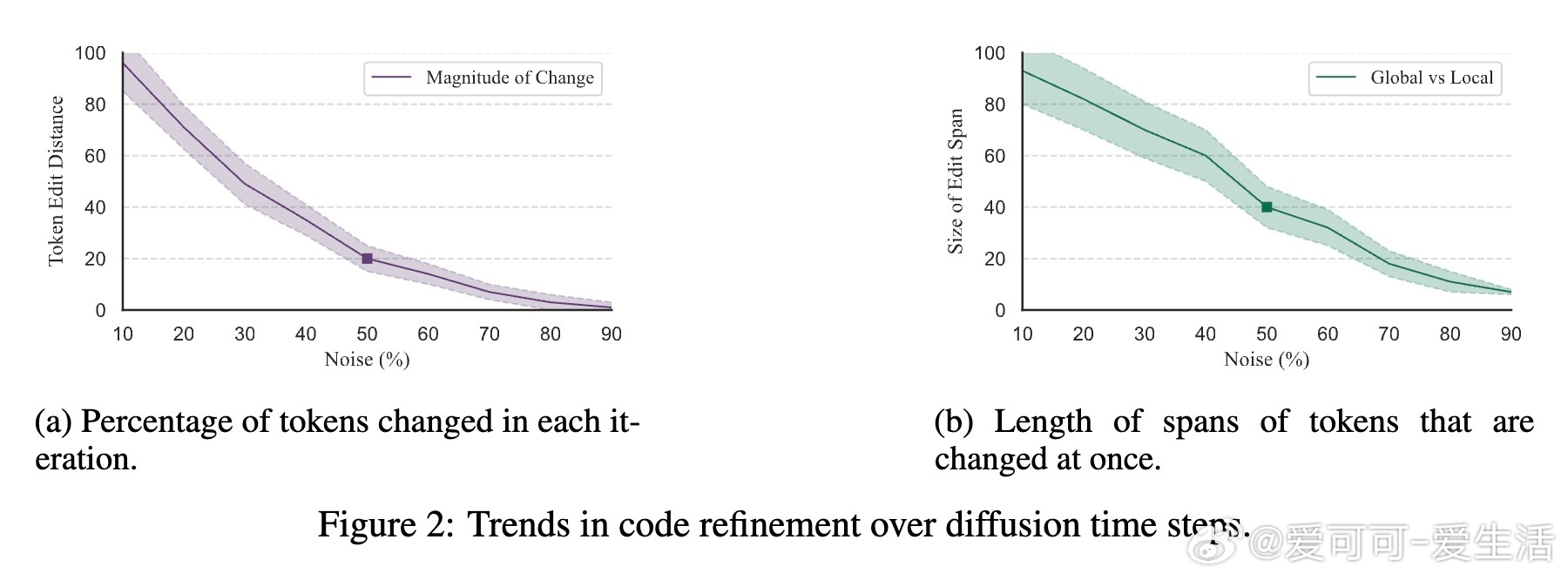
• 机制创新:Diffusion模型非一次性生成,而是逐步逆转加噪过程,后期步骤的离散token变化类似于微小修复,能精准定位并改正代码错误。
• 双重应用:
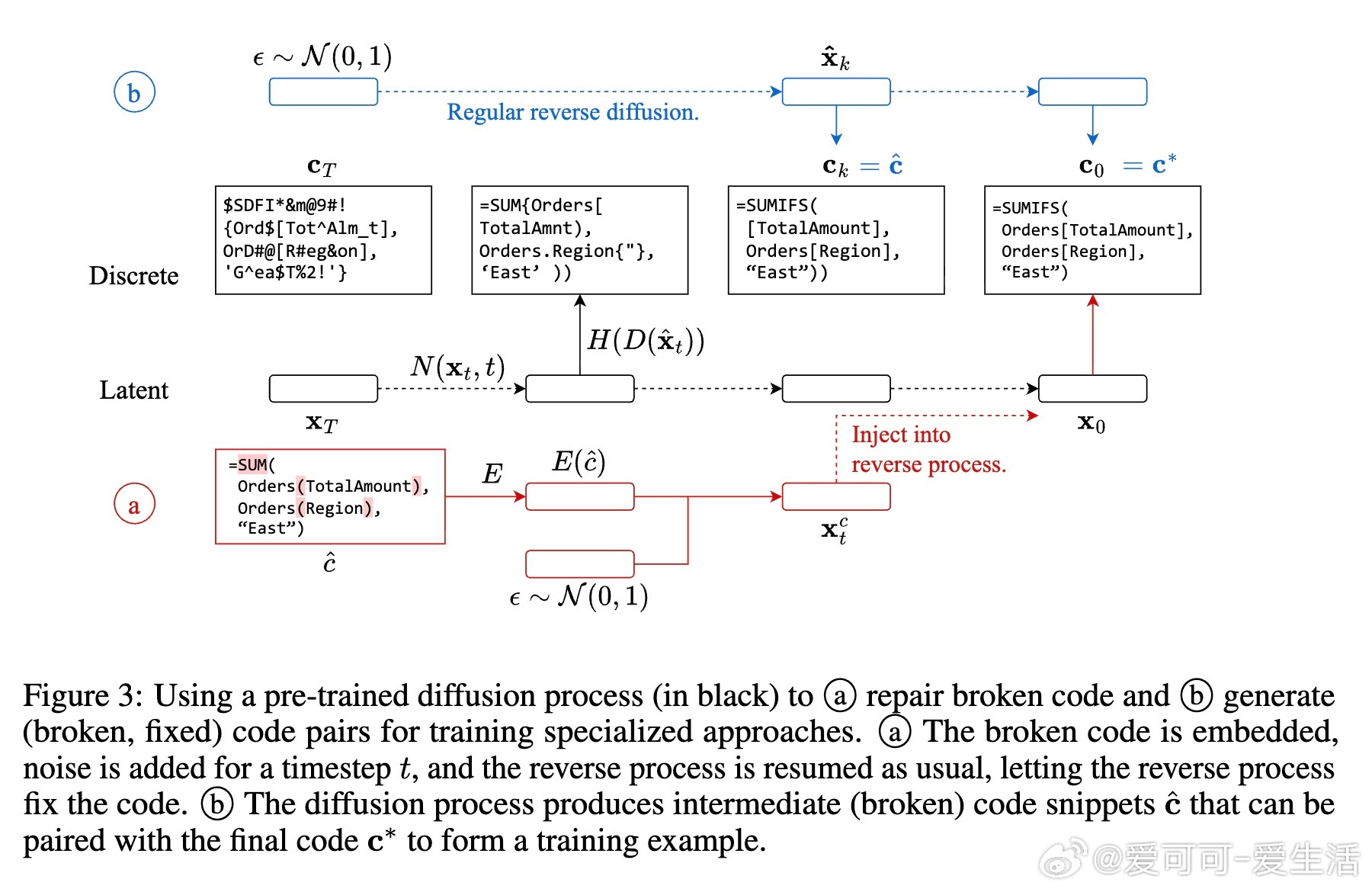
1️⃣ 直接修复:对损坏代码注入噪声后继续扩散逆转,模型自动修复语法错误,Python与Excel修复率达56.4%-68.2%。
2️⃣ 数据生成:从扩散中抽取中间“损坏-修复”代码对,生成多样性和复杂度更高的训练数据,提升下游模型修复性能2.5%-3.5%。
• 多语种验证:实验覆盖Python、Excel公式和PowerShell命令,展示跨语言适用性与修复效果。
• 技术架构:基于CodeFusion,结合Transformer编码器与解码器,训练过程中融合连续表示与离散token交叉熵损失,确保生成代码语法正确且语义合理。
• 性能对比:在小型模型(约6000万参数)下超越Codex等传统模型,展现强大潜力。多噪声水平投票策略进一步提升修复准确率。
• 长尾问题缓解:扩散模型无需人工规则即可生成真实感强、覆盖广泛的错误样本,解决传统数据生成器泛化不足和训练数据匮乏难题。
• 未来方向:结合执行反馈与更大规模模型,潜力巨大;当前限制包括仅支持较短代码片段及缺少语义上下文信息。
Diffusion模型不仅拓宽了代码自动修复的技术边界,也为合成训练数据提供了高质量新路径,是代码智能辅助的重要里程碑。
更多详情👉 arxiv.org/abs/2508.11110
代码修复扩散模型程序生成机器学习人工智能