[CL]《Learning Facts at Scale with Active Reading》J Lin, V Berges, X Chen, W Yih... [FAIR at Meta] (2025)
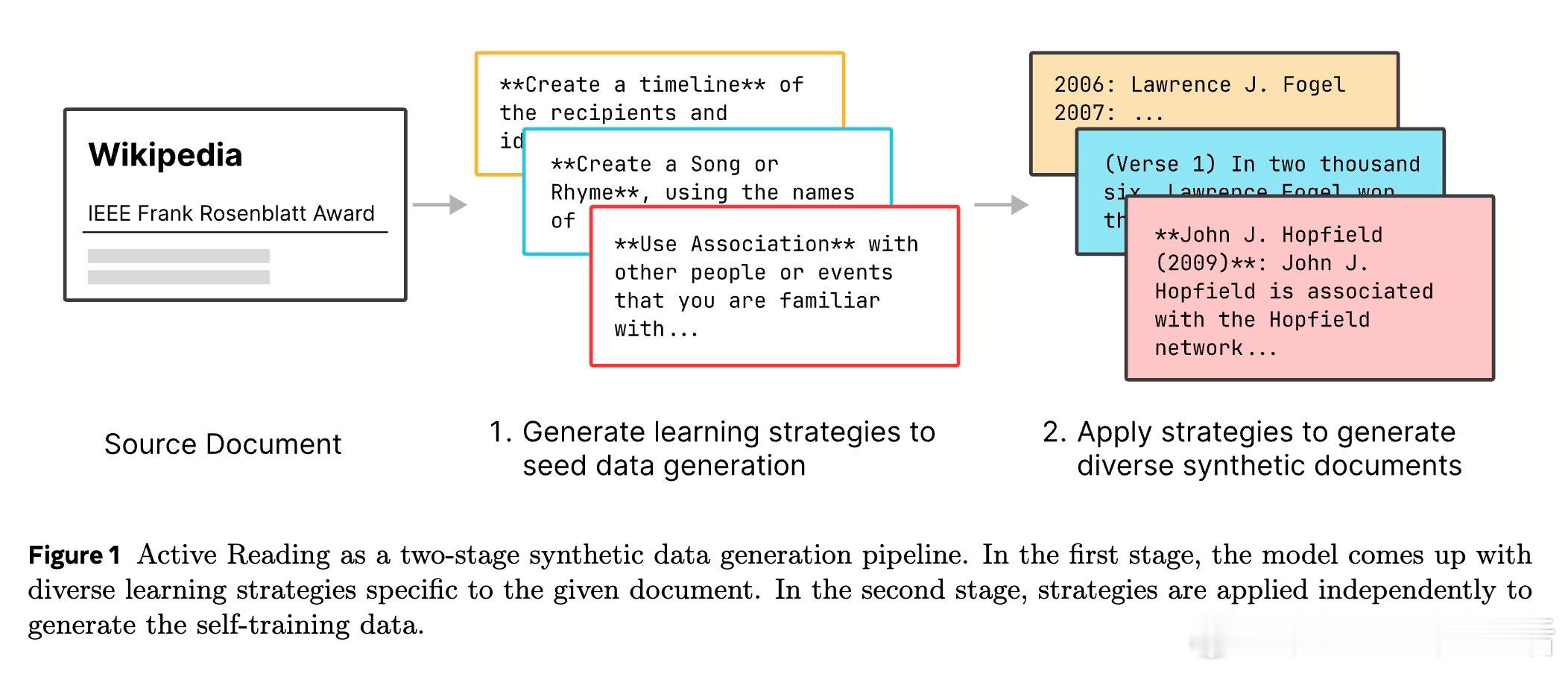
掌握大规模事实知识的关键在于“主动阅读”训练框架。该方法让大模型自主生成多样化学习策略,模拟人类多维度理解新知识的过程,远超传统的简单重复或固定模板问答生成。
• 主动阅读通过模型自拟策略(如释义、知识链接、主动回忆、类比推理等)对文档进行多角度合成训练数据,提高知识内化和推理能力。
• 在专家领域适配(如金融FinanceBench)和开放域事实问答(SimpleWikiQA)中,主动阅读分别令8B模型事实回忆率提升至66%和26%,相较基础微调提升超3倍及1.6倍。
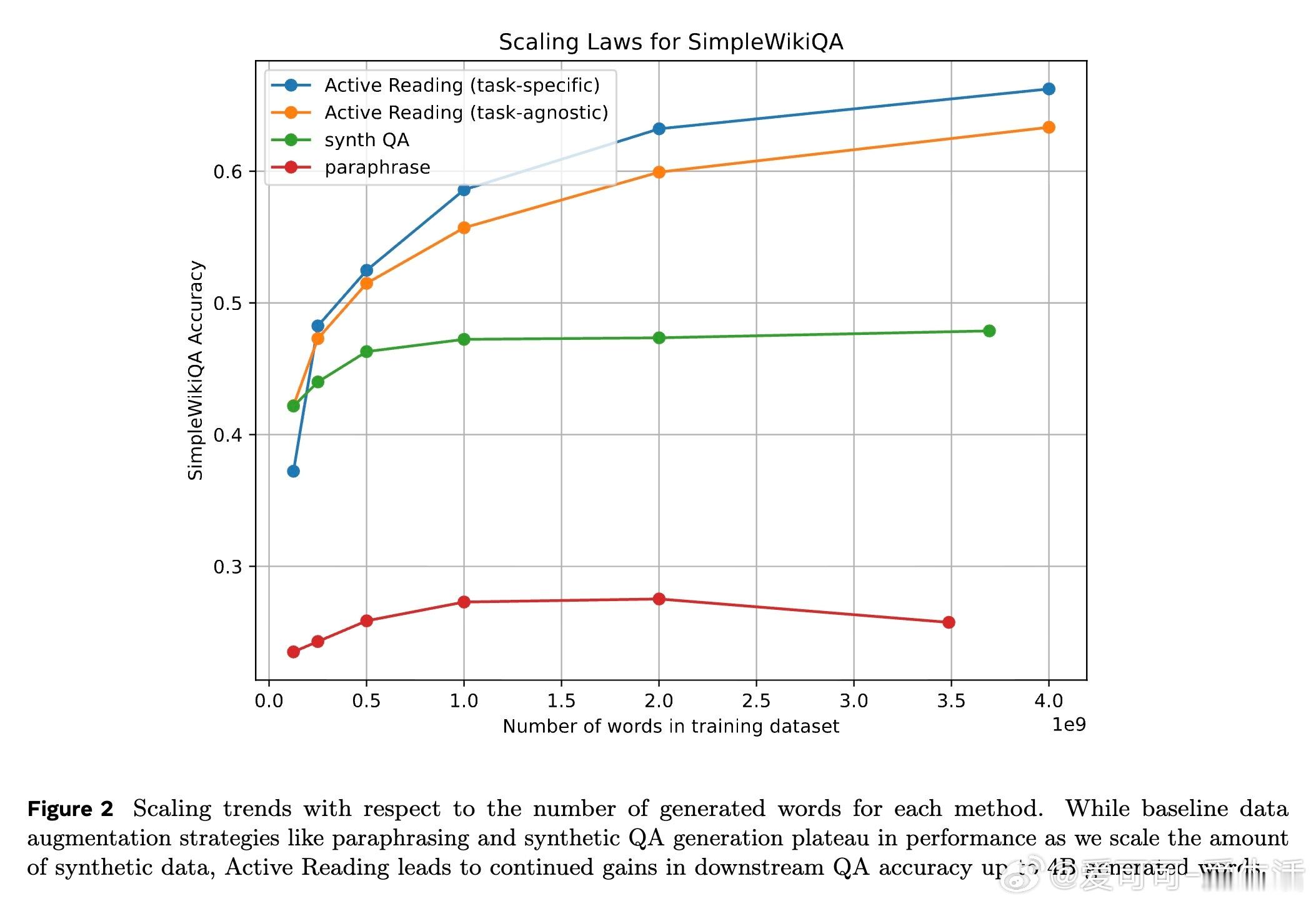
• 生成数据规模达数十亿词时,主动阅读性能持续提升,而传统释义和合成问答方法表现趋于饱和,显示其更优的扩展潜力。
• 以1万亿词的主动阅读合成维基百科数据预训练,Meta WikiExpert-8B模型突破了多项基准,超越数百亿乃至数千亿参数规模的大模型,显示了其在事实知识掌握上的领先优势。
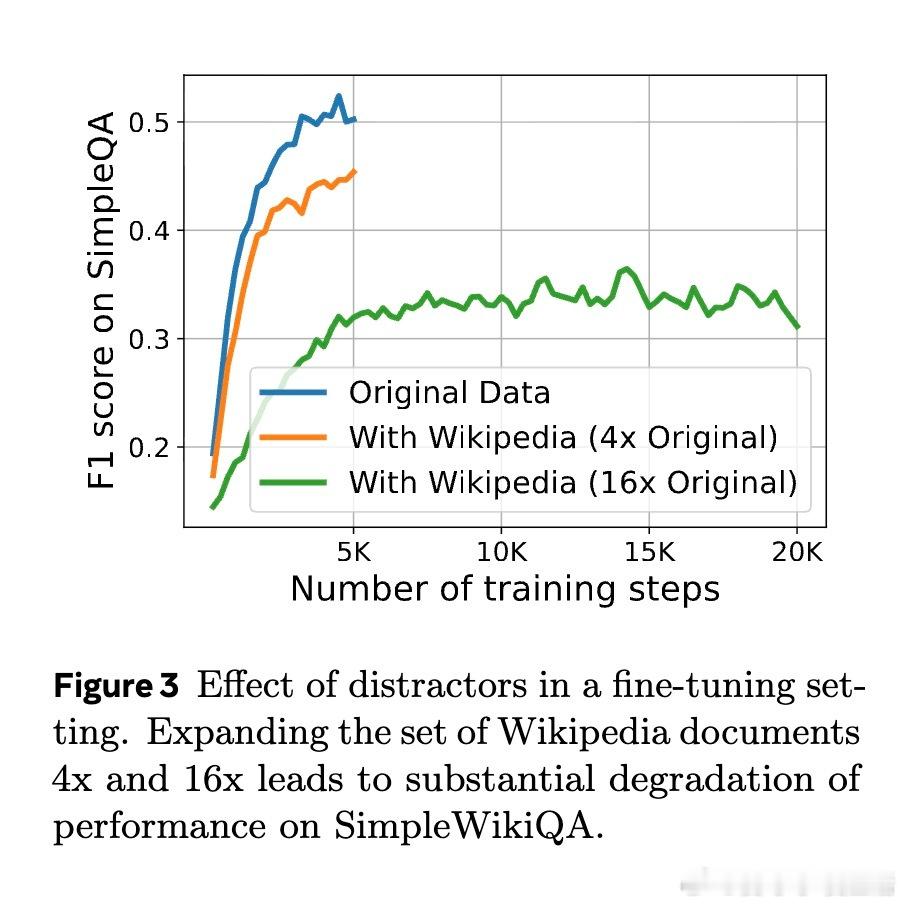
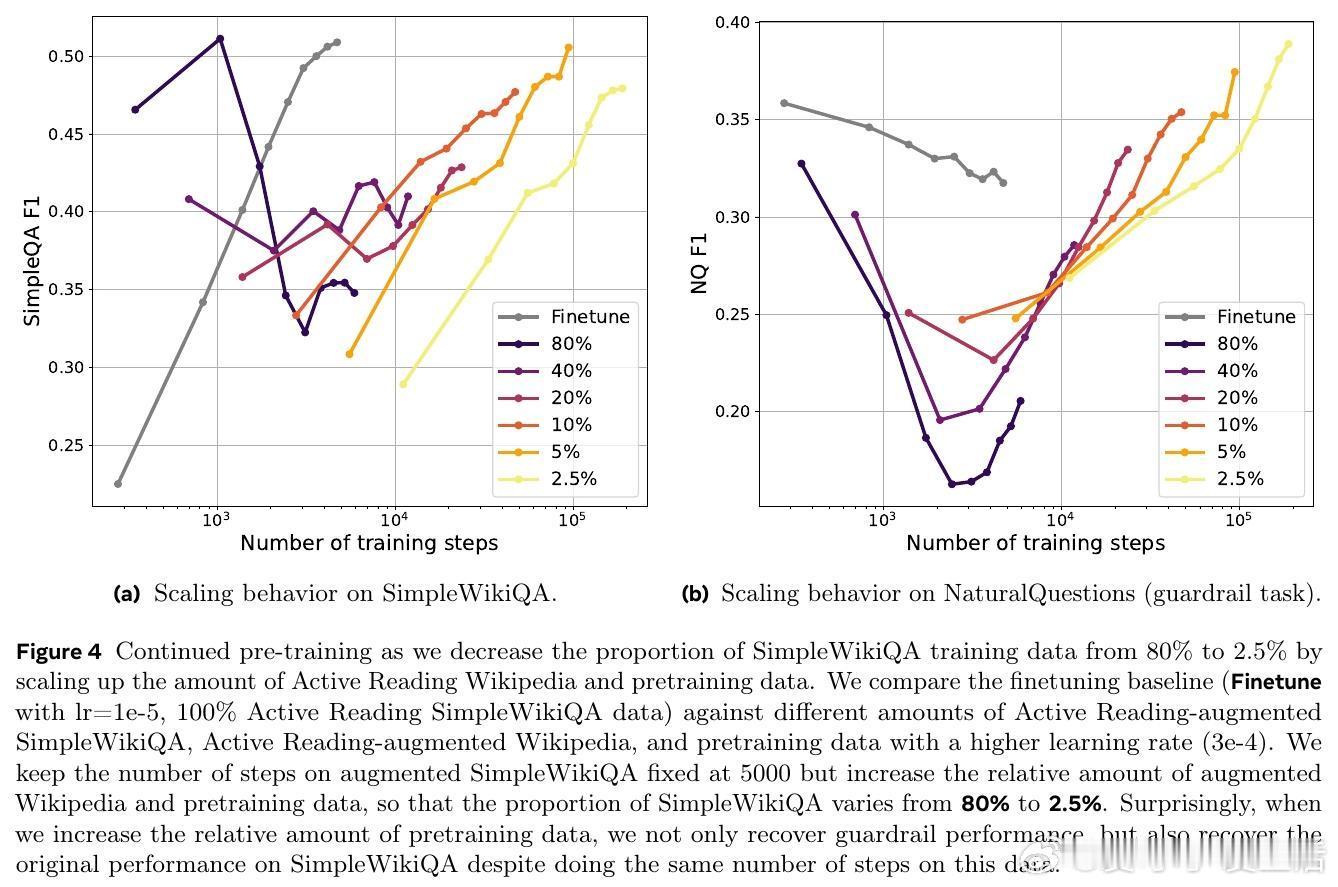
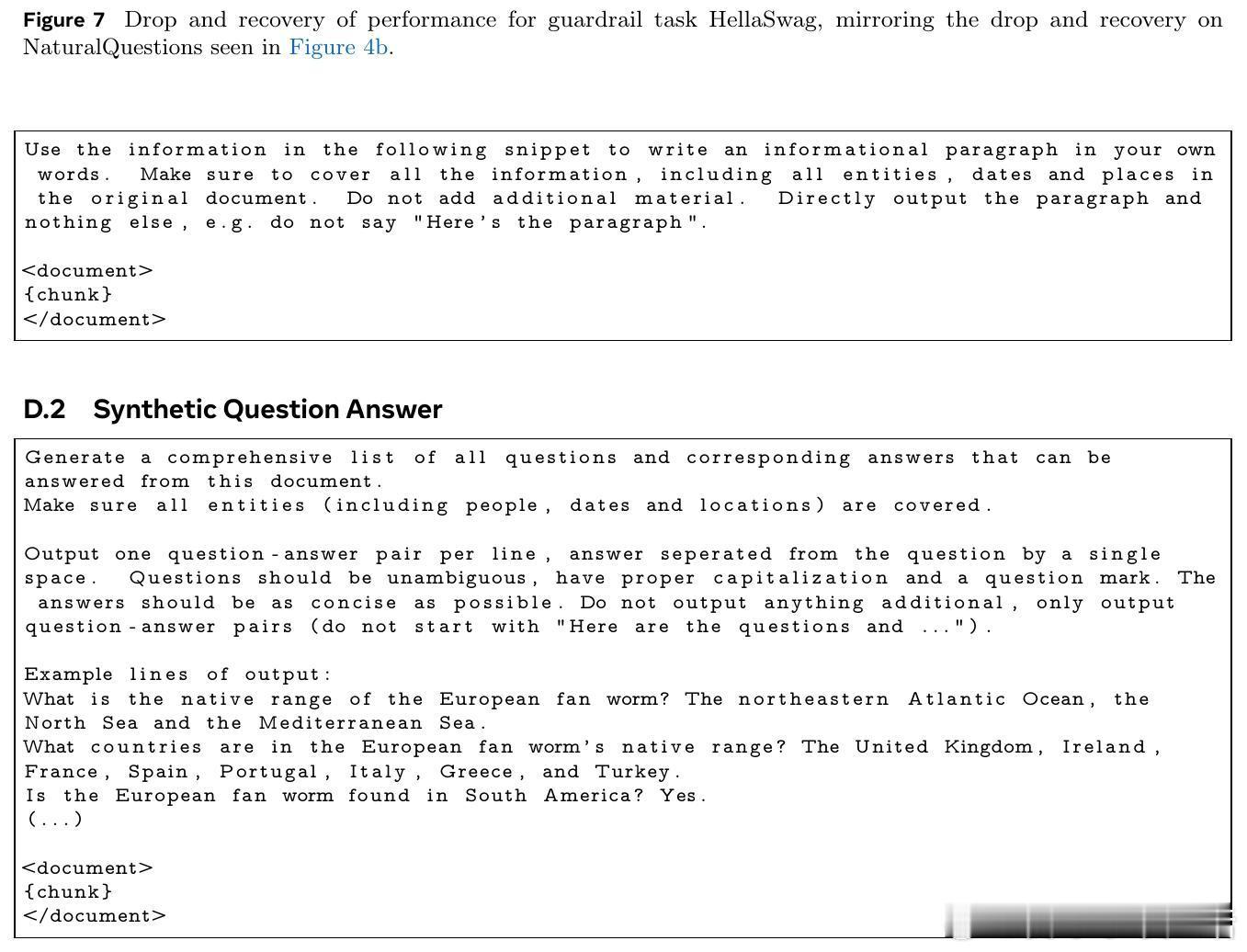
• 实验揭示,主动阅读数据的多样性(低自我重复度)是其效果显著的主因,而非单纯覆盖率提升;此外,训练时与预训练数据的合理混合有助于避免遗忘、促进知识整合。
• 研究还指出,模型使用自身生成的数据反而优于由更大模型生成的数据,提示学习材料与模型能力匹配的重要性。
• 主动阅读为未来大规模预训练和领域适配提供新范式,助推模型实现更稳健、全面的知识掌握,减少对检索增强生成的依赖,简化系统架构并提升推理质量。
主动阅读重塑了模型学习知识的路径,开启了参数内存知识系统化积累的新篇章。
详细阅读🔗arxiv.org/abs/2508.09494
开源模型🔗huggingface.co/facebook/meta-wiki-expert
数据集🔗huggingface.co/datasets/facebook/meta-active-reading
大规模语言模型知识学习主动阅读合成数据领域适配维基百科专家模型